

Last up in Privacy Tech for #enigma2021, @xchatty speaking about "IMPLEMENTING DIFFERENTIAL PRIVACY FOR THE 2020
* Data users expect consistent data releases
* Some people call synthetic data "fake data" like
"fake news"
* It's not clear what "quality assurance" and "data exploration" means in a DP framework

* required to collect it by the constitution
* but required to maintain privacy by law
* differential privacy is open and we can talk about privacy loss/accuracy tradeoff
* swapping assumed limitations of the attackers (e.g. limited computational power)
Change in the meaning of "privacy" as relative -- it requires a lot of explanation and overcoming organizational barriers.
* different groups at the Census thought that meant different things
* before, states were processed as they came in. Differential privacy requires everything be computed on at once
* required a lot more computing power
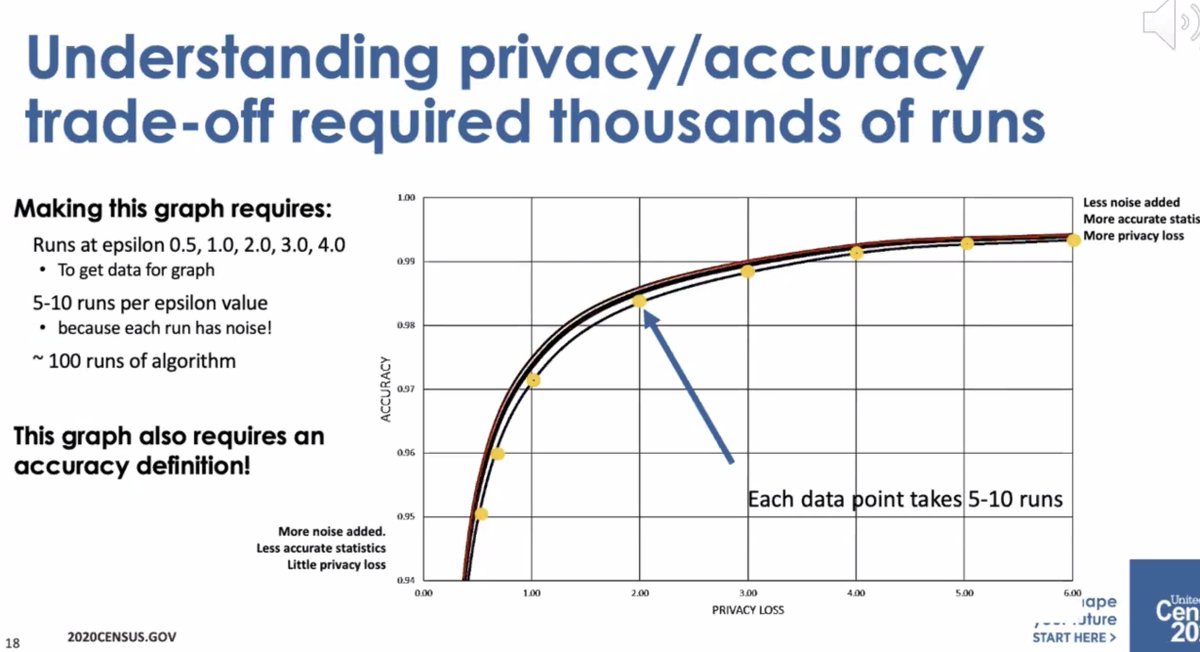
* initial implementation was by Dan Kiefer, who took a sabbatical
* expanded team to with Simson and others
* 2018 end to end test
* then got to move to AWS Elastic compute... but the monitoring wasn't good enough and had to create their own dashboard to track execution
* it wasn't a small amount of compute
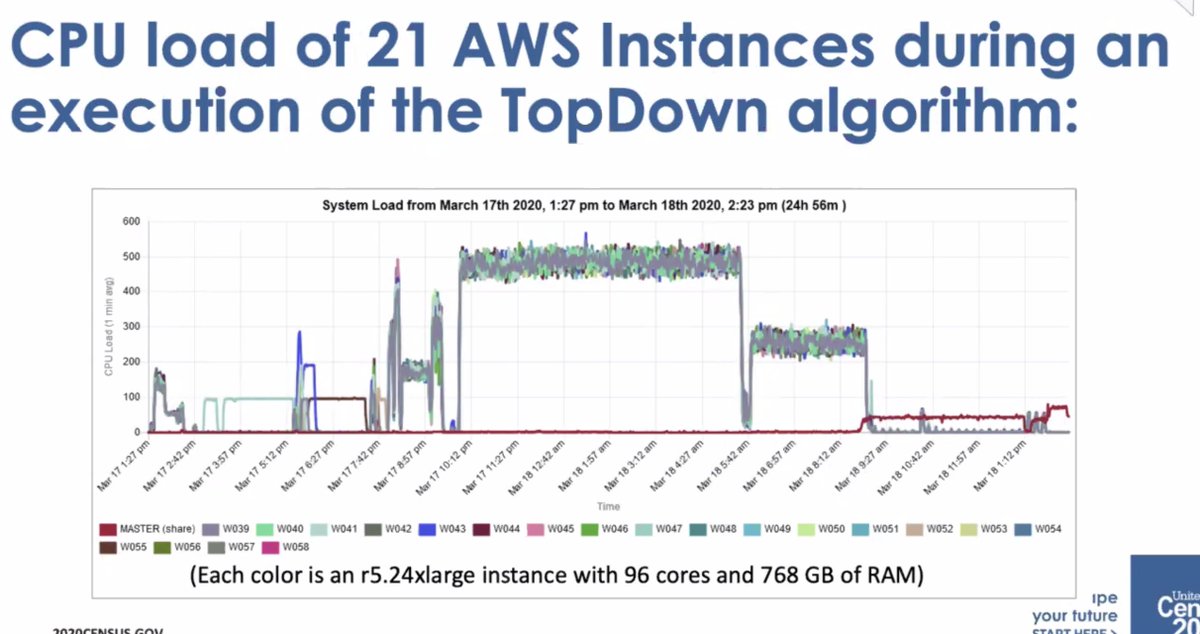
* ... it wasn't well-received by the data users who thought there was too much error
If you avoid that, you might add bias to the data. How to avoid that? Let some data users get access to the measurement files [I don't follow]

More from Lea Kissner




More from Tech







After getting good feedback on yesterday's thread on #routemobile I think it is logical to do a bit in-depth technical study. Place #twilio at center, keep #routemobile & #tanla at the periphery & see who is each placed.
This thread is inspired by one of the articles I read on the-ken about #postman API & how they are transforming & expediting software product delivery & consumption, leading to enhanced developer productivity.
We all know that #Twilio offers host of APIs that can be readily used for faster integration by anyone who wants to have communication capabilities. Before we move ahead, let's get a few things cleared out.
Can anyone build the programming capability to process payments or communication capabilities? Yes, but will they, the answer is NO. Companies prefer to consume APIs offered by likes of #Stripe #twilio #Shopify #razorpay etc.
This offers two benefits - faster time to market, of course that means no need to re-invent the wheel + not worrying of compliance around payment process or communication regulations. This makes entire ecosystem extremely agile
So I have been studying this entire communication layer as its relevance is ever growing with more devices coming online, staying connected, and relying on real-time communication. Not that this domain under penetrated, but there is a change underway.
— Ameya (@Finstor85) February 10, 2021
This thread is inspired by one of the articles I read on the-ken about #postman API & how they are transforming & expediting software product delivery & consumption, leading to enhanced developer productivity.
We all know that #Twilio offers host of APIs that can be readily used for faster integration by anyone who wants to have communication capabilities. Before we move ahead, let's get a few things cleared out.
Can anyone build the programming capability to process payments or communication capabilities? Yes, but will they, the answer is NO. Companies prefer to consume APIs offered by likes of #Stripe #twilio #Shopify #razorpay etc.
This offers two benefits - faster time to market, of course that means no need to re-invent the wheel + not worrying of compliance around payment process or communication regulations. This makes entire ecosystem extremely agile



You May Also Like

Margatha Natarajar murthi - Uthirakosamangai temple near Ramanathapuram,TN
#ArudraDarisanam
Unique Natarajar made of emerlad is abt 6 feet tall.
It is always covered with sandal paste.Only on Thriuvadhirai Star in month Margazhi-Nataraja can be worshipped without sandal paste.

After removing the sandal paste,day long rituals & various abhishekam will be https://t.co/e1Ye8DrNWb day Maragatha Nataraja sannandhi will be closed after anointing the murthi with fresh sandal paste.Maragatha Natarajar is covered with sandal paste throughout the year

as Emerald has scientific property of its molecules getting disturbed when exposed to light/water/sound.This is an ancient Shiva temple considered to be 3000 years old -believed to be where Bhagwan Shiva gave Veda gyaana to Parvati Devi.This temple has some stunning sculptures.

#ArudraDarisanam
Unique Natarajar made of emerlad is abt 6 feet tall.
It is always covered with sandal paste.Only on Thriuvadhirai Star in month Margazhi-Nataraja can be worshipped without sandal paste.
After removing the sandal paste,day long rituals & various abhishekam will be https://t.co/e1Ye8DrNWb day Maragatha Nataraja sannandhi will be closed after anointing the murthi with fresh sandal paste.Maragatha Natarajar is covered with sandal paste throughout the year
as Emerald has scientific property of its molecules getting disturbed when exposed to light/water/sound.This is an ancient Shiva temple considered to be 3000 years old -believed to be where Bhagwan Shiva gave Veda gyaana to Parvati Devi.This temple has some stunning sculptures.










1/ 👋 Excited to share what we’ve been building at https://t.co/GOQJ7LjQ2t + we are going to tweetstorm our progress every week!
Week 1 highlights: getting shortlisted for YC W2019🤞, acquiring a premium domain💰, meeting Substack's @hamishmckenzie and Stripe CEO @patrickc 🤩
2/ So what is Brew?
brew / bru : / to make (beer, coffee etc.) / verb: begin to develop 🌱
A place for you to enjoy premium content while supporting your favorite creators. Sort of like a ‘Consumer-facing Patreon’ cc @jackconte
(we’re still working on the pitch)
3/ So, why be so transparent? Two words: launch strategy.
jk 😅 a) I loooove doing something consistently for a long period of time b) limited downside and infinite upside (feedback, accountability, reach).
cc @altimor, @pmarca

4/ https://t.co/GOQJ7LjQ2t domain 🍻
It started with a cold email. Guess what? He was using BuyMeACoffee on his blog, and was excited to hear about what we're building next. Within 2w, we signed the deal at @Escrowcom's SF office. You’re a pleasure to work with @MichaelCyger!
5/ @ycombinator's invite for the in-person interview arrived that evening. Quite a day!
Thanks @patio11 for the thoughtful feedback on our YC application, and @gabhubert for your directions on positioning the product — set the tone for our pitch!

Week 1 highlights: getting shortlisted for YC W2019🤞, acquiring a premium domain💰, meeting Substack's @hamishmckenzie and Stripe CEO @patrickc 🤩
2/ So what is Brew?
brew / bru : / to make (beer, coffee etc.) / verb: begin to develop 🌱
A place for you to enjoy premium content while supporting your favorite creators. Sort of like a ‘Consumer-facing Patreon’ cc @jackconte
(we’re still working on the pitch)
3/ So, why be so transparent? Two words: launch strategy.
jk 😅 a) I loooove doing something consistently for a long period of time b) limited downside and infinite upside (feedback, accountability, reach).
cc @altimor, @pmarca
4/ https://t.co/GOQJ7LjQ2t domain 🍻
It started with a cold email. Guess what? He was using BuyMeACoffee on his blog, and was excited to hear about what we're building next. Within 2w, we signed the deal at @Escrowcom's SF office. You’re a pleasure to work with @MichaelCyger!
5/ @ycombinator's invite for the in-person interview arrived that evening. Quite a day!
Thanks @patio11 for the thoughtful feedback on our YC application, and @gabhubert for your directions on positioning the product — set the tone for our pitch!