Next up at #enigma2021, Sanghyun Hong will be speaking about "A SOUND MIND IN A VULNERABLE BODY: PRACTICAL HARDWARE ATTACKS ON DEEP LEARNING"
(Hint: speaker is on the

* looks at the robustness in an isolated manner
* doesn't look at the whole ecosystem and how the model is used -- ML models are running in real hardware with real software which has real vulns!
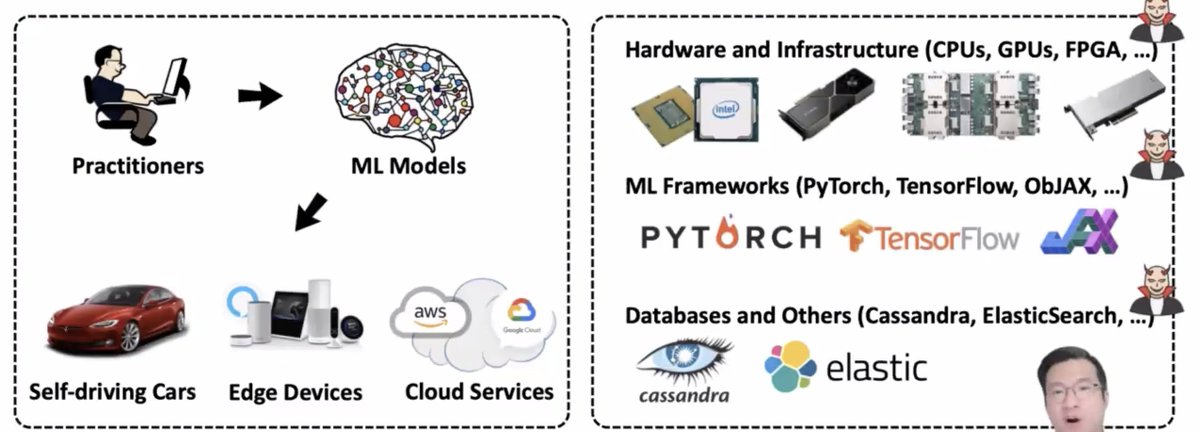
e.g. fault injection attacks, side-channel attacks
* co-location of VMs from different users
* weak attackers with less subtle control
The cloud providers try to secure things, e.g. protections against Rowhammer
... BUT this focuses on the average or best case, not the worst cast!

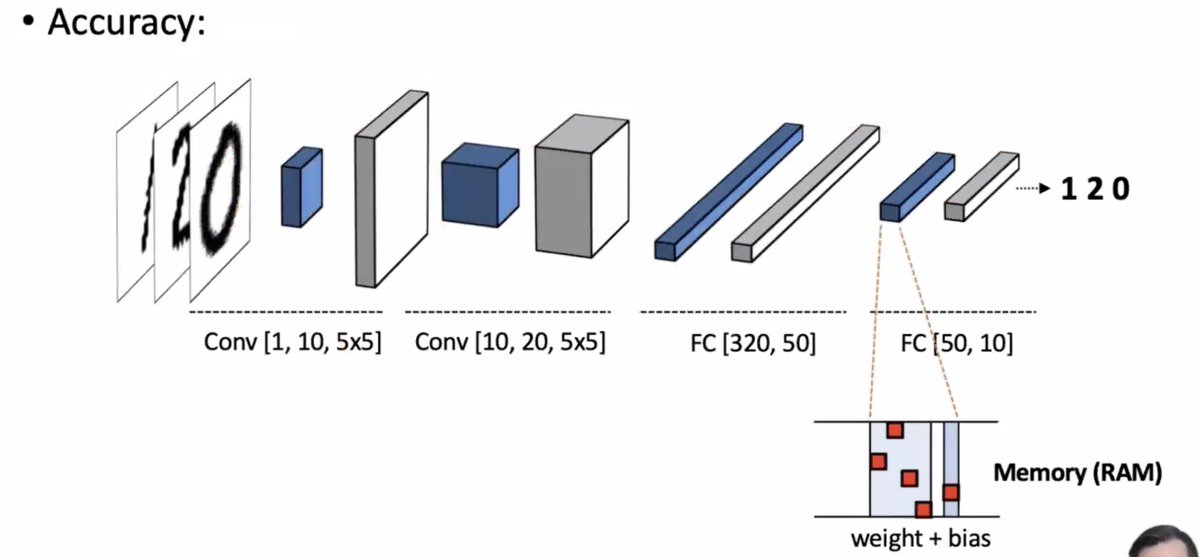
* negligible effect on the average case accuracy
* but flipping one bit can make significant amount of damage for particular queries
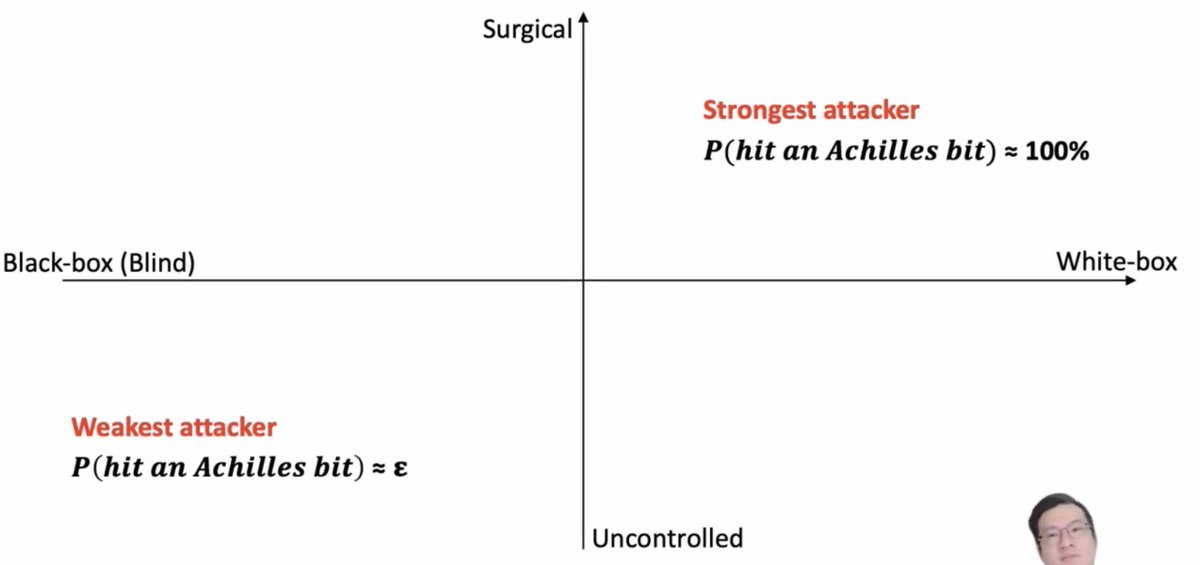
How much damage can a single bit flip cause?


Some strong attackers might be able to hit an "achilles" bit (one that's really going to mess with the model), but weaker attackers are going to hit bits more randomly.


The attacker might want to get their hands on fancy DNNs which are considered trade secrets and proprietary to their creators. They're expensive to make! They need good training data! People want to protect them!
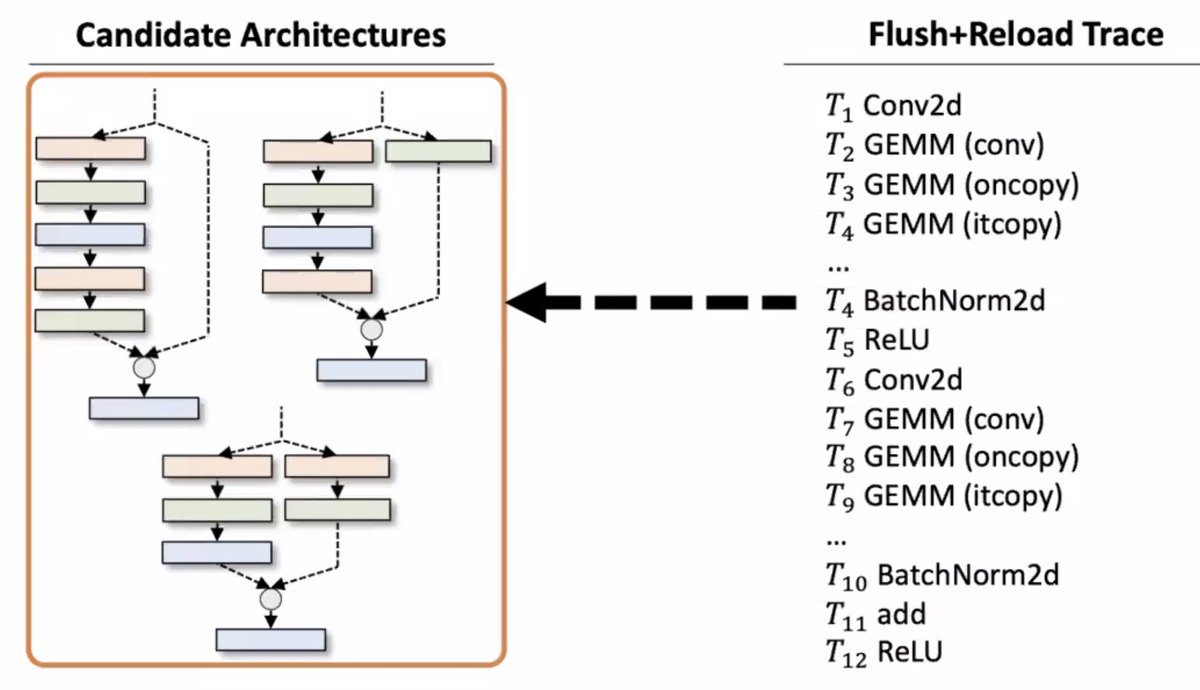
Does this work? Apparently so: they tried it out using a cache side-channel attack and got back the architectures of the fancy DNN back.

More from Lea Kissner





More from Science








Hard agree. And if this is useful, let me share something that often gets omitted (not by @kakape).
Variants always emerge, & are not good or bad, but expected. The challenge is figuring out which variants are bad, and that can't be done with sequence alone.
You can't just look at a sequence and say, "Aha! A mutation in spike. This must be more transmissible or can evade antibody neutralization." Sure, we can use computational models to try and predict the functional consequence of a given mutation, but models are often wrong.
The virus acquires mutations randomly every time it replicates. Many mutations don't change the virus at all. Others may change it in a way that have no consequences for human transmission or disease. But you can't tell just looking at sequence alone.
In order to determine the functional impact of a mutation, you need to actually do experiments. You can look at some effects in cell culture, but to address questions relating to transmission or disease, you have to use animal models.
The reason people were concerned initially about B.1.1.7 is because of epidemiological evidence showing that it rapidly became dominant in one area. More rapidly that could be explained unless it had some kind of advantage that allowed it to outcompete other circulating variants.
Variants always emerge, & are not good or bad, but expected. The challenge is figuring out which variants are bad, and that can't be done with sequence alone.
Feels like the next thing we're going to need is a ranking system for how concerning "variants of concern\u201d actually are.
— Kai Kupferschmidt (@kakape) January 15, 2021
A lot of constellations of mutations are concerning, but people are lumping together variants with vastly different levels of evidence that we need to worry.
You can't just look at a sequence and say, "Aha! A mutation in spike. This must be more transmissible or can evade antibody neutralization." Sure, we can use computational models to try and predict the functional consequence of a given mutation, but models are often wrong.
The virus acquires mutations randomly every time it replicates. Many mutations don't change the virus at all. Others may change it in a way that have no consequences for human transmission or disease. But you can't tell just looking at sequence alone.
In order to determine the functional impact of a mutation, you need to actually do experiments. You can look at some effects in cell culture, but to address questions relating to transmission or disease, you have to use animal models.
The reason people were concerned initially about B.1.1.7 is because of epidemiological evidence showing that it rapidly became dominant in one area. More rapidly that could be explained unless it had some kind of advantage that allowed it to outcompete other circulating variants.