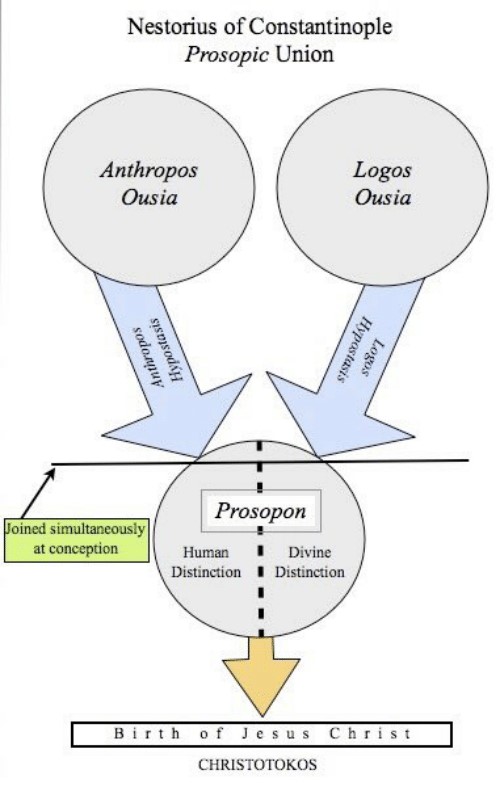
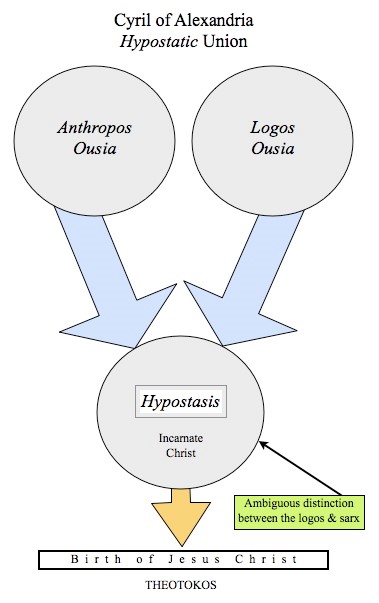
The elections in Bavaria show that the German political system, which has long seemed reasonably stolid, is in enormous flux at the moment.
A thread with four lessons. (Just wait till you get to Number 4! 😉)

Anyone who tries to sell that as a success for the liberal left is kidding themselves.
That narrative is certainly confirmed today, with the SPD in single digits.
But...
This is the CSU’s worst result in history. It comes at a moment when its sister party, Angela Merkel’s CDU, at 26%, polls worse than at any point since the 1950s.
But the Greens overwhelmingly drew voters from the SPD. So this is not the rise of a new kind of politics; it’s a realignment within the center-left camp.
Historically, Social Democrats have done so well by holding together a coalition of working-class voters (e.g. steelworkers) and the liberal bourgeoisie (e.g. teacher, university students, civil servants, artists).
Working-class voters are flocking to right-wing populists. The liberal bourgeoisie feels better represented by cosmopolitan parties like the Greens.
Cosmopolitain parties that don’t have to serve working-class voters have much more traction with the liberal bourgeoisie.
Parties like the Greens are very well set up to serve the ~20% of the education that is educated, reasonably affluent, predominantly urban, and pretty cosmopolitan in values.
More from All







Master Thread of all my threads!
Hello!! 👋
• I have curated some of the best tweets from the best traders we know of.
• Making one master thread and will keep posting all my threads under this.
• Go through this for super learning/value totally free of cost! 😃
1. 7 FREE OPTION TRADING COURSES FOR
2. THE ABSOLUTE BEST 15 SCANNERS EXPERTS ARE USING
Got these scanners from the following accounts:
1. @Pathik_Trader
2. @sanjufunda
3. @sanstocktrader
4. @SouravSenguptaI
5. @Rishikesh_ADX
3. 12 TRADING SETUPS which experts are using.
These setups I found from the following 4 accounts:
1. @Pathik_Trader
2. @sourabhsiso19
3. @ITRADE191
4.
4. Curated tweets on HOW TO SELL STRADDLES.
Everything covered in this thread.
1. Management
2. How to initiate
3. When to exit straddles
4. Examples
5. Videos on
Hello!! 👋
• I have curated some of the best tweets from the best traders we know of.
• Making one master thread and will keep posting all my threads under this.
• Go through this for super learning/value totally free of cost! 😃
1. 7 FREE OPTION TRADING COURSES FOR
A THREAD:
— Aditya Todmal (@AdityaTodmal) November 28, 2020
7 FREE OPTION TRADING COURSES FOR BEGINNERS.
Been getting lot of dm's from people telling me they want to learn option trading and need some recommendations.
Here I'm listing the resources every beginner should go through to shorten their learning curve.
(1/10)
2. THE ABSOLUTE BEST 15 SCANNERS EXPERTS ARE USING
Got these scanners from the following accounts:
1. @Pathik_Trader
2. @sanjufunda
3. @sanstocktrader
4. @SouravSenguptaI
5. @Rishikesh_ADX
The absolute best 15 scanners which experts are using.
— Aditya Todmal (@AdityaTodmal) January 29, 2021
Got these scanners from the following accounts:
1. @Pathik_Trader
2. @sanjufunda
3. @sanstocktrader
4. @SouravSenguptaI
5. @Rishikesh_ADX
Share for the benefit of everyone.
3. 12 TRADING SETUPS which experts are using.
These setups I found from the following 4 accounts:
1. @Pathik_Trader
2. @sourabhsiso19
3. @ITRADE191
4.
12 TRADING SETUPS which experts are using.
— Aditya Todmal (@AdityaTodmal) February 7, 2021
These setups I found from the following 4 accounts:
1. @Pathik_Trader
2. @sourabhsiso19
3. @ITRADE191
4. @DillikiBiili
Share for the benefit of everyone.
4. Curated tweets on HOW TO SELL STRADDLES.
Everything covered in this thread.
1. Management
2. How to initiate
3. When to exit straddles
4. Examples
5. Videos on
Curated tweets on How to Sell Straddles
— Aditya Todmal (@AdityaTodmal) February 21, 2021
Everything covered in this thread.
1. Management
2. How to initiate
3. When to exit straddles
4. Examples
5. Videos on Straddles
Share if you find this knowledgeable for the benefit of others.









You May Also Like

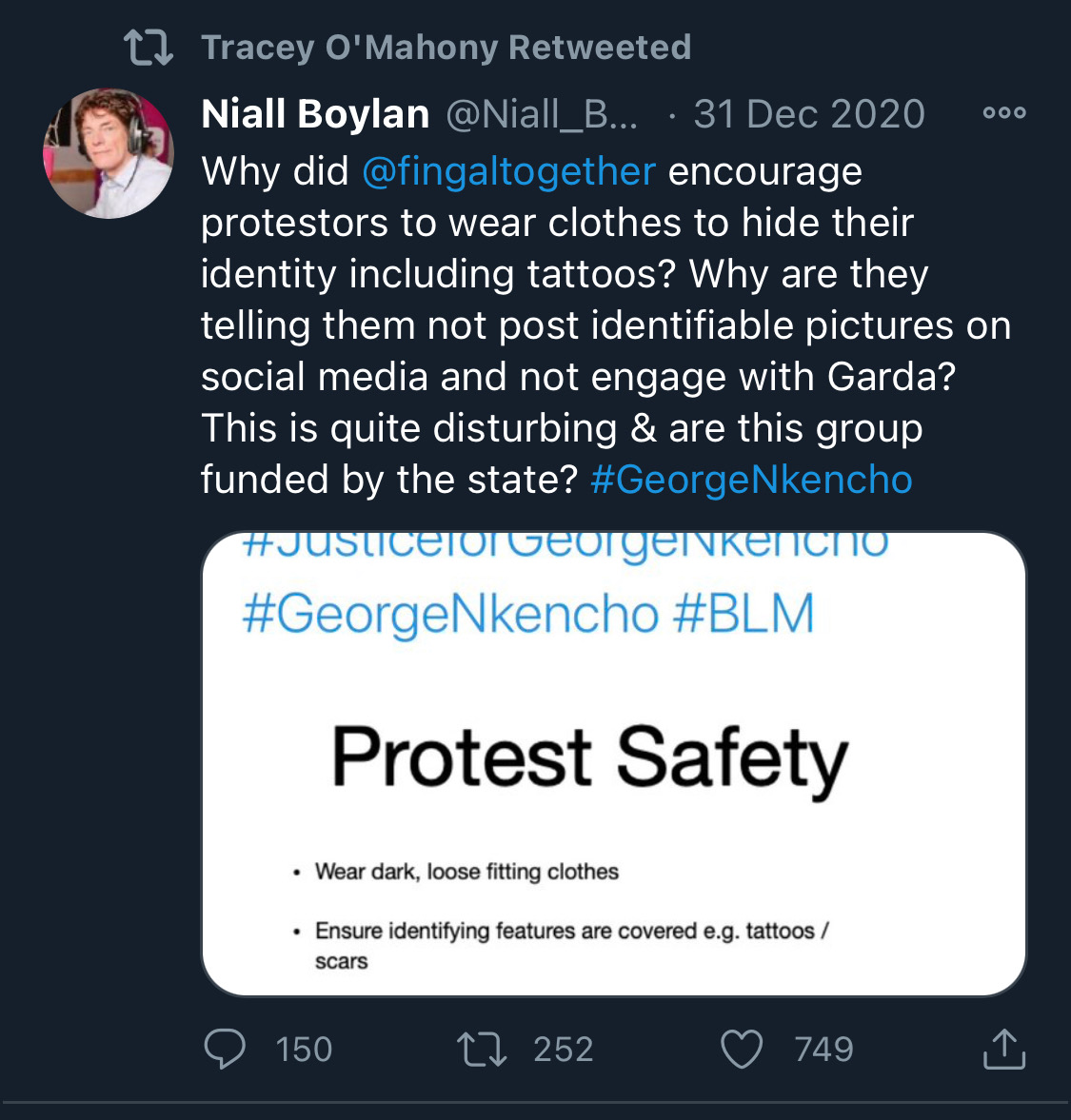
Fake chats claiming to be from the Irish African community are being disseminated by the far right in order to suggest that violence is imminent from #BLM supporters. This is straight out of the QAnon and Proud Boys playbook. Spread the word. Protest safely. #georgenkencho

There is co-ordination across the far right in Ireland now to stir both left and right in the hopes of creating a race war. Think critically! Fascists see the tragic killing of #georgenkencho, the grief of his community and pending investigation as a flashpoint for action.
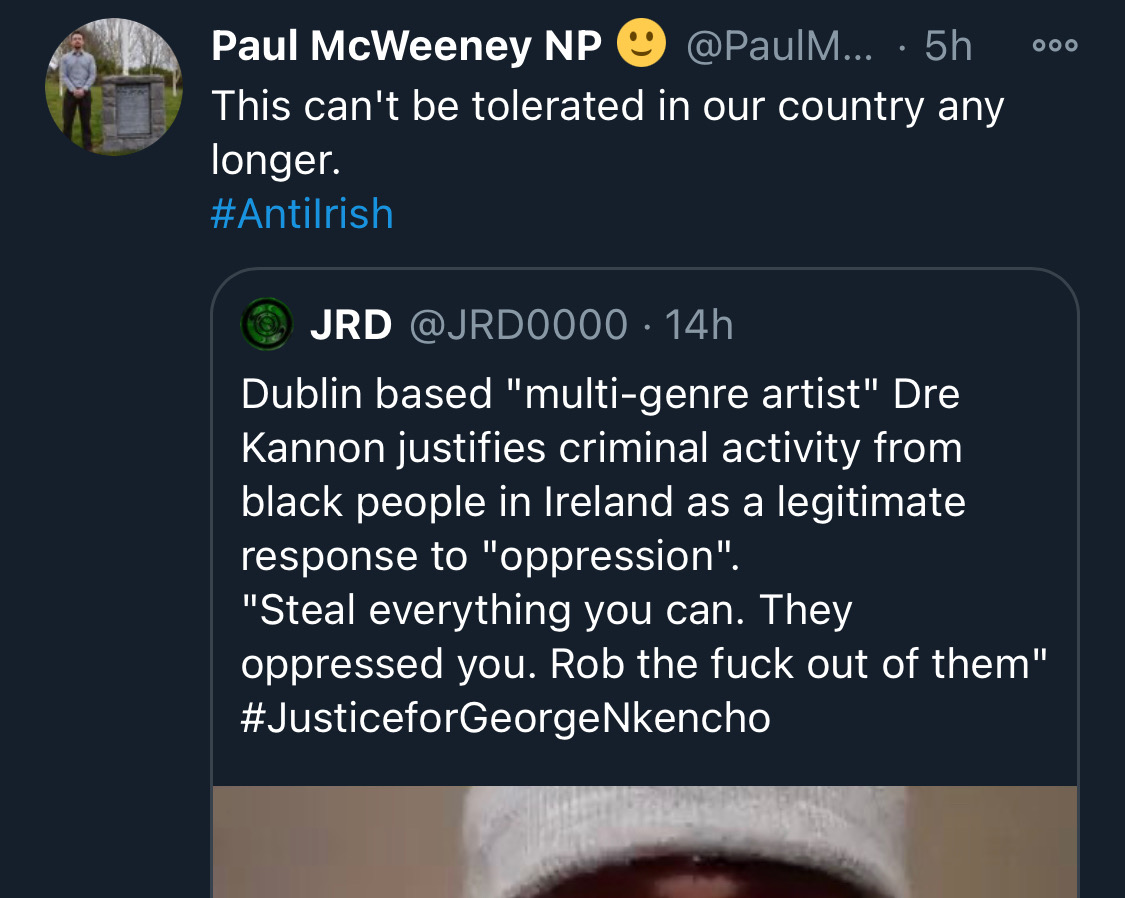
Across Telegram, Twitter and Facebook disinformation is being peddled on the back of these tragic events. From false photographs to the tactics ofwhite supremacy, the far right is clumsily trying to drive hate against minority groups and figureheads.
Declan Ganley’s Burkean group and the incel wing of National Party (Gearóid Murphy, Mick O’Keeffe & Co.) as well as all the usuals are concerted in their efforts to demonstrate their white supremacist cred. The quiet parts are today being said out loud.
The best thing you can do is challenge disinformation and report posts where engagement isn’t appropriate. Many of these are blatantly racist posts designed to drive recruitment to NP and other Nationalist groups. By all means protest but stay safe.
There is co-ordination across the far right in Ireland now to stir both left and right in the hopes of creating a race war. Think critically! Fascists see the tragic killing of #georgenkencho, the grief of his community and pending investigation as a flashpoint for action.
Across Telegram, Twitter and Facebook disinformation is being peddled on the back of these tragic events. From false photographs to the tactics ofwhite supremacy, the far right is clumsily trying to drive hate against minority groups and figureheads.
Be aware, the images the #farright are sharing in the hopes of starting a race war, are not of the SPAR employee that was punched. They\u2019re older photos of a Everton fan. Be aware of the information you\u2019re sharing and that it may be false. Always #factcheck #GeorgeNkencho pic.twitter.com/4c9w4CMk5h
— antifa.drone (@antifa_drone) December 31, 2020
Declan Ganley’s Burkean group and the incel wing of National Party (Gearóid Murphy, Mick O’Keeffe & Co.) as well as all the usuals are concerted in their efforts to demonstrate their white supremacist cred. The quiet parts are today being said out loud.
There is a concerted effort in far-right Telegram groups to try and incite violence on street by targetting people for racist online abuse following the killing of George Nkencho
— Mark Malone (@soundmigration) January 1, 2021
This follows on and is part of a misinformation campaign to polarise communities at this time.
The best thing you can do is challenge disinformation and report posts where engagement isn’t appropriate. Many of these are blatantly racist posts designed to drive recruitment to NP and other Nationalist groups. By all means protest but stay safe.

1/x Fort Detrick History
Mr. Patrick, one of the chief scientists at the Army Biological Warfare Laboratories at Fort Detrick in Frederick, Md., held five classified US patents for the process of weaponizing anthrax.
2/x
Under Mr. Patrick’s direction, scientists at Fort Detrick developed a tularemia agent that, if disseminated by airplane, could cause casualties & sickness over 1000s mi². In a 10,000 mi² range, it had 90% casualty rate & 50% fatality rate

3/x His team explored Q fever, plague, & Venezuelan equine encephalitis, testing more than 20 anthrax strains to discern most lethal variety. Fort Detrick scientists used aerosol spray systems inside fountain pens, walking sticks, light bulbs, & even in 1953 Mercury exhaust pipes

4/x After retiring in 1986, Mr. Patrick remained one of the world’s foremost specialists on biological warfare & was a consultant to the CIA, FBI, & US military. He debriefed Soviet defector Ken Alibek, the deputy chief of the Soviet biowarfare program
https://t.co/sHqSaTSqtB

5/x Back in Time
In 1949 the Army created a small team of chemists at "Camp Detrick" called Special Operations Division. Its assignment was to find military uses for toxic bacteria. The coercive use of toxins was a new field, which fascinated Allen Dulles, later head of the CIA

Mr. Patrick, one of the chief scientists at the Army Biological Warfare Laboratories at Fort Detrick in Frederick, Md., held five classified US patents for the process of weaponizing anthrax.
2/x
Under Mr. Patrick’s direction, scientists at Fort Detrick developed a tularemia agent that, if disseminated by airplane, could cause casualties & sickness over 1000s mi². In a 10,000 mi² range, it had 90% casualty rate & 50% fatality rate
3/x His team explored Q fever, plague, & Venezuelan equine encephalitis, testing more than 20 anthrax strains to discern most lethal variety. Fort Detrick scientists used aerosol spray systems inside fountain pens, walking sticks, light bulbs, & even in 1953 Mercury exhaust pipes
4/x After retiring in 1986, Mr. Patrick remained one of the world’s foremost specialists on biological warfare & was a consultant to the CIA, FBI, & US military. He debriefed Soviet defector Ken Alibek, the deputy chief of the Soviet biowarfare program
https://t.co/sHqSaTSqtB
5/x Back in Time
In 1949 the Army created a small team of chemists at "Camp Detrick" called Special Operations Division. Its assignment was to find military uses for toxic bacteria. The coercive use of toxins was a new field, which fascinated Allen Dulles, later head of the CIA