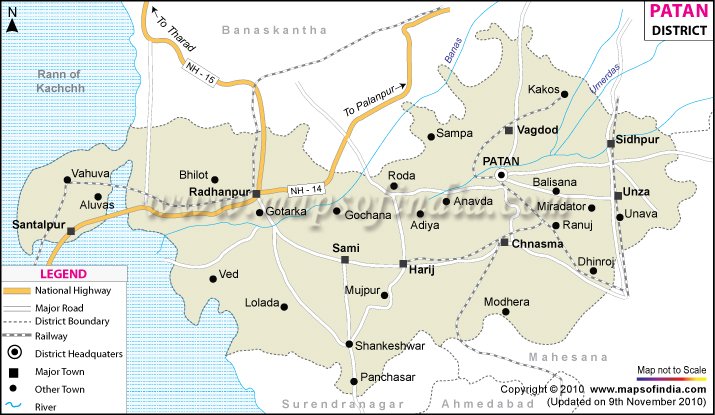
#சதுரகிரி #ஶ்ரீசுந்தரமகாலிங்கசுவாமி திருக்கோவில். மிக விசேஷமான மலை. போய் வந்தவர்களுக்கு இதன் பெருமை புரியும். சித்தர்கள் இன்றும் அருவமாக வாழும் மலை. திசைக்கு நான்கு கிரிகள் (மலை)வீதம் பதினாறு கிரிகள் சமமாக சதுரமாக அமைந்த காரணத்தால் சதுரகிரி என்ற பெயர் ஏற்பட்டது. மலையின் பரப்பளவு



சதுரகிரி தல வரலாறு : சதுரகிரி மலை அடிவாரத்திலுள்ள கோட்டையூரில் பிறந்தவன் பச்சைமால். இவன் பசுக்களை மேய்த்து பிழைத்தான். இவனது பெற்றோர் தில்லைக்கோன்- திலகமதி. மனைவி சடைமங்கை.
இவள் மாமனார் வீட்டில் தினமும் பாலைக் கொடுத்து


இதனையடுத்து #கோரக்க_சித்தர் தவம் செய்த குகையும், #பதஞ்சலி முனிவரின் சீடர்கள் பூஜித்த லிங்கமும் உள்ளது. இந்த லிங்கத்தை தரிசிக்க வேண்டுமானால், ஆகாய கங்கை