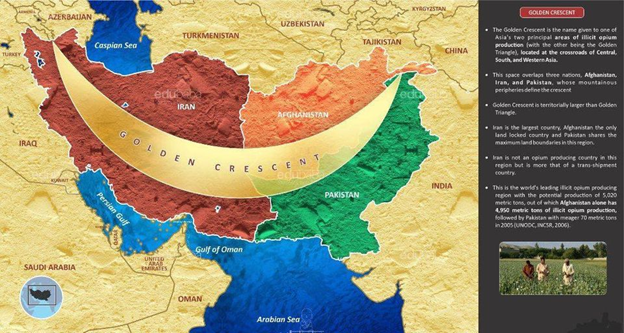
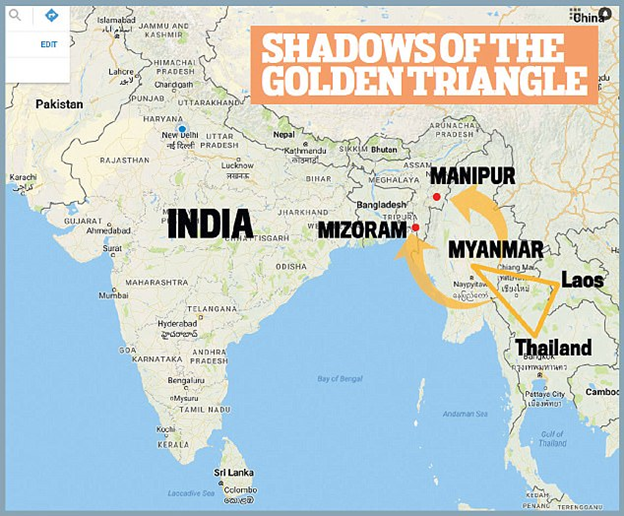
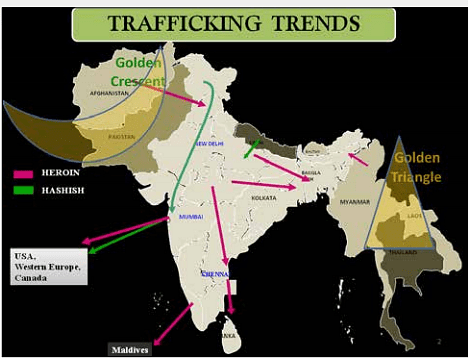
This post is pretty bizarre, but it manages to hit on so many false beliefs that I've seen hurt junior data scientists that it deserves some explicit
More from Data science




Wellll... A few weeks back I started working on a tutorial for our lab's Code Club on how to make shitty graphs. It was too dispiriting and I balked. A twitter workshop with figures and code:
Here's the code to generate the data frame. You can get the "raw" data from https://t.co/jcTE5t0uBT

Obligatory stacked bar chart that hides any sense of variation in the data

Obligatory stacked bar chart that shows all the things and yet shows absolutely nothing at the same time

STACKED Donut plot. Who doesn't want a donut? Who wouldn't want a stack of them!?! This took forever to render and looked worse than it should because coord_polar doesn't do scales="free_x".

When are you doing pie charts?
— #BlackLivesMatter (@surt_lab) October 13, 2020
Here's the code to generate the data frame. You can get the "raw" data from https://t.co/jcTE5t0uBT
Obligatory stacked bar chart that hides any sense of variation in the data
Obligatory stacked bar chart that shows all the things and yet shows absolutely nothing at the same time
STACKED Donut plot. Who doesn't want a donut? Who wouldn't want a stack of them!?! This took forever to render and looked worse than it should because coord_polar doesn't do scales="free_x".



You May Also Like

https://t.co/6cRR2B3jBE
Viruses and other pathogens are often studied as stand-alone entities, despite that, in nature, they mostly live in multispecies associations called biofilms—both externally and within the host.
https://t.co/FBfXhUrH5d

Microorganisms in biofilms are enclosed by an extracellular matrix that confers protection and improves survival. Previous studies have shown that viruses can secondarily colonize preexisting biofilms, and viral biofilms have also been described.

...we raise the perspective that CoVs can persistently infect bats due to their association with biofilm structures. This phenomenon potentially provides an optimal environment for nonpathogenic & well-adapted viruses to interact with the host, as well as for viral recombination.

Biofilms can also enhance virion viability in extracellular environments, such as on fomites and in aquatic sediments, allowing viral persistence and dissemination.

Viruses and other pathogens are often studied as stand-alone entities, despite that, in nature, they mostly live in multispecies associations called biofilms—both externally and within the host.
https://t.co/FBfXhUrH5d
Microorganisms in biofilms are enclosed by an extracellular matrix that confers protection and improves survival. Previous studies have shown that viruses can secondarily colonize preexisting biofilms, and viral biofilms have also been described.
...we raise the perspective that CoVs can persistently infect bats due to their association with biofilm structures. This phenomenon potentially provides an optimal environment for nonpathogenic & well-adapted viruses to interact with the host, as well as for viral recombination.
Biofilms can also enhance virion viability in extracellular environments, such as on fomites and in aquatic sediments, allowing viral persistence and dissemination.