
These networks are primary focus for compression tasks of data in Machine Learning.
Ever heard of Autoencoders?
The first time I saw a Neural Network with more output neurons than in the hidden layers, I couldn't figure how it would work?!
#DeepLearning #MachineLearning
Here's a little something about them: 🧵👇

These networks are primary focus for compression tasks of data in Machine Learning.
Later when someone needs, can just take that small representation and recreate the original, just like a zip file.📥
Our inputs and outputs are same and a simple euclidean distance can be used as a loss function for measuring the reconstruction.
Of course, we wouldn't expect a perfect reconstruction.
We are just trying to minimize the L here. All the backpropagation rules still hold.
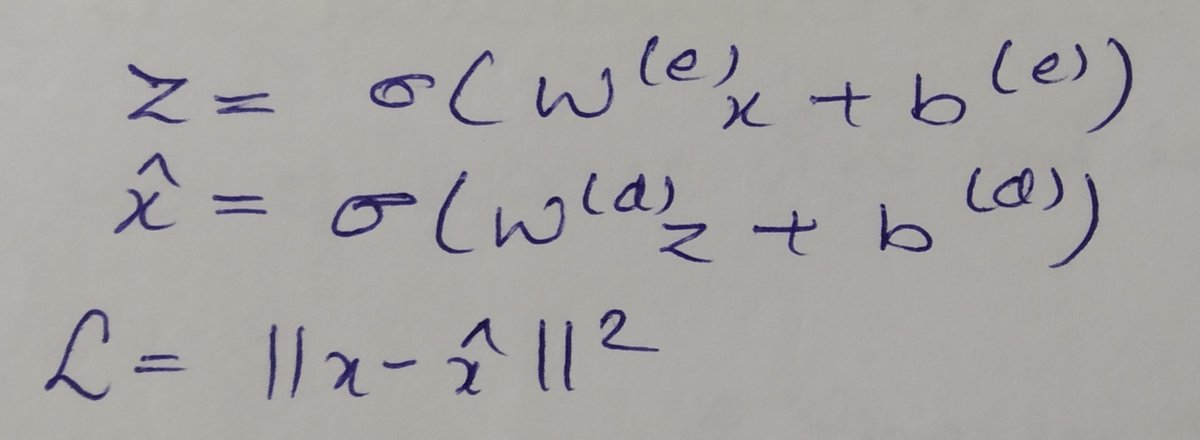
▫️ Can learn non-linear transformations, with non-linear activation functions and multiple layers.
▫️ Doesn't have to learn only from dense layers, can learn from convolutional layers too, better for images, videos right?
▫️ Can make use of pre-trained layers from another model to apply transfer learning to enhance the encoder /decoder
🔸 Image Colouring
🔸 Feature Variation
🔸 Dimensionality Reduction
🔸 Denoising Image
🔸 Watermark Removal
More from Machine learning



10 PYTHON 🐍 libraries for machine learning.
Retweets are appreciated.
[ Thread ]

1. NumPy (Numerical Python)
- The most powerful feature of NumPy is the n-dimensional array.
- It contains basic linear algebra functions, Fourier transforms, and tools for integration with other low-level languages.
Ref: https://t.co/XY13ILXwSN

2. SciPy (Scientific Python)
- SciPy is built on NumPy.
- It is one of the most useful libraries for a variety of high-level science and engineering modules like discrete Fourier transform, Linear Algebra, Optimization, and Sparse matrices.
Ref: https://t.co/ALTFqM2VUo

3. Matplotlib
- Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python.
- You can also use Latex commands to add math to your plot.
- Matplotlib makes hard things possible.
Ref: https://t.co/zodOo2WzGx

4. Pandas
- Pandas is for structured data operations and manipulations.
- It is extensively used for data munging and preparation.
- Pandas were added relatively recently to Python and have been instrumental in boosting Python’s usage.
Ref: https://t.co/IFzikVHht4

Retweets are appreciated.
[ Thread ]
1. NumPy (Numerical Python)
- The most powerful feature of NumPy is the n-dimensional array.
- It contains basic linear algebra functions, Fourier transforms, and tools for integration with other low-level languages.
Ref: https://t.co/XY13ILXwSN
2. SciPy (Scientific Python)
- SciPy is built on NumPy.
- It is one of the most useful libraries for a variety of high-level science and engineering modules like discrete Fourier transform, Linear Algebra, Optimization, and Sparse matrices.
Ref: https://t.co/ALTFqM2VUo
3. Matplotlib
- Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python.
- You can also use Latex commands to add math to your plot.
- Matplotlib makes hard things possible.
Ref: https://t.co/zodOo2WzGx
4. Pandas
- Pandas is for structured data operations and manipulations.
- It is extensively used for data munging and preparation.
- Pandas were added relatively recently to Python and have been instrumental in boosting Python’s usage.
Ref: https://t.co/IFzikVHht4







You May Also Like

✨📱 iOS 12.1 📱✨
🗓 Release date: October 30, 2018
📝 New Emojis: 158
https://t.co/bx8XjhiCiB

New in iOS 12.1: 🥰 Smiling Face With 3 Hearts https://t.co/6eajdvueip

New in iOS 12.1: 🥵 Hot Face https://t.co/jhTv1elltB

New in iOS 12.1: 🥶 Cold Face https://t.co/EIjyl6yZrF

New in iOS 12.1: 🥳 Partying Face https://t.co/p8FDNEQ3LJ

🗓 Release date: October 30, 2018
📝 New Emojis: 158
https://t.co/bx8XjhiCiB
New in iOS 12.1: 🥰 Smiling Face With 3 Hearts https://t.co/6eajdvueip
New in iOS 12.1: 🥵 Hot Face https://t.co/jhTv1elltB
New in iOS 12.1: 🥶 Cold Face https://t.co/EIjyl6yZrF
New in iOS 12.1: 🥳 Partying Face https://t.co/p8FDNEQ3LJ

Stan Lee’s fictional superheroes lived in the real New York. Here’s where they lived, and why. https://t.co/oV1IGGN8R6

Stan Lee, who died Monday at 95, was born in Manhattan and graduated from DeWitt Clinton High School in the Bronx. His pulp-fiction heroes have come to define much of popular culture in the early 21st century.
Tying Marvel’s stable of pulp-fiction heroes to a real place — New York — served a counterbalance to the sometimes gravity-challenged action and the improbability of the stories. That was just what Stan Lee wanted. https://t.co/rDosqzpP8i

The New York universe hooked readers. And the artists drew what they were familiar with, which made the Marvel universe authentic-looking, down to the water towers atop many of the buildings. https://t.co/rDosqzpP8i

The Avengers Mansion was a Beaux-Arts palace. Fans know it as 890 Fifth Avenue. The Frick Collection, which now occupies the place, uses the address of the front door: 1 East 70th Street.
Stan Lee, who died Monday at 95, was born in Manhattan and graduated from DeWitt Clinton High School in the Bronx. His pulp-fiction heroes have come to define much of popular culture in the early 21st century.
Tying Marvel’s stable of pulp-fiction heroes to a real place — New York — served a counterbalance to the sometimes gravity-challenged action and the improbability of the stories. That was just what Stan Lee wanted. https://t.co/rDosqzpP8i
The New York universe hooked readers. And the artists drew what they were familiar with, which made the Marvel universe authentic-looking, down to the water towers atop many of the buildings. https://t.co/rDosqzpP8i
The Avengers Mansion was a Beaux-Arts palace. Fans know it as 890 Fifth Avenue. The Frick Collection, which now occupies the place, uses the address of the front door: 1 East 70th Street.











