

Last up in Privacy Tech for #enigma2021, @xchatty speaking about "IMPLEMENTING DIFFERENTIAL PRIVACY FOR THE 2020
* Data users expect consistent data releases
* Some people call synthetic data "fake data" like
"fake news"
* It's not clear what "quality assurance" and "data exploration" means in a DP framework

* required to collect it by the constitution
* but required to maintain privacy by law
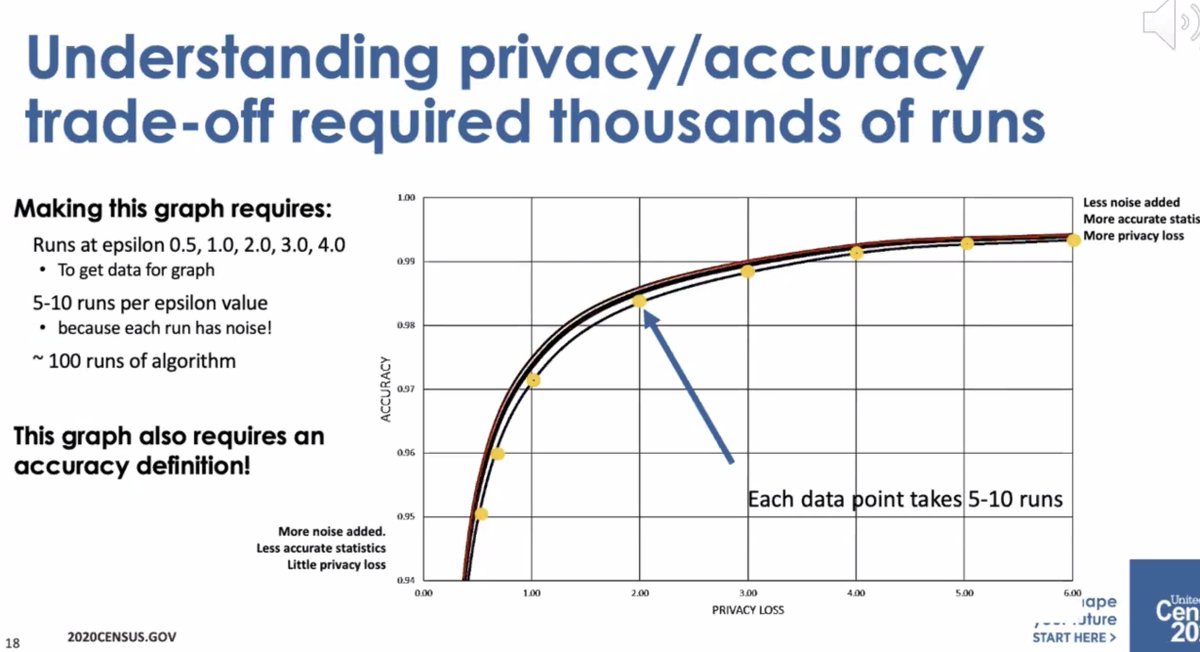
* differential privacy is open and we can talk about privacy loss/accuracy tradeoff
* swapping assumed limitations of the attackers (e.g. limited computational power)
Change in the meaning of "privacy" as relative -- it requires a lot of explanation and overcoming organizational barriers.
* different groups at the Census thought that meant different things
* before, states were processed as they came in. Differential privacy requires everything be computed on at once
* required a lot more computing power
* initial implementation was by Dan Kiefer, who took a sabbatical
* expanded team to with Simson and others
* 2018 end to end test
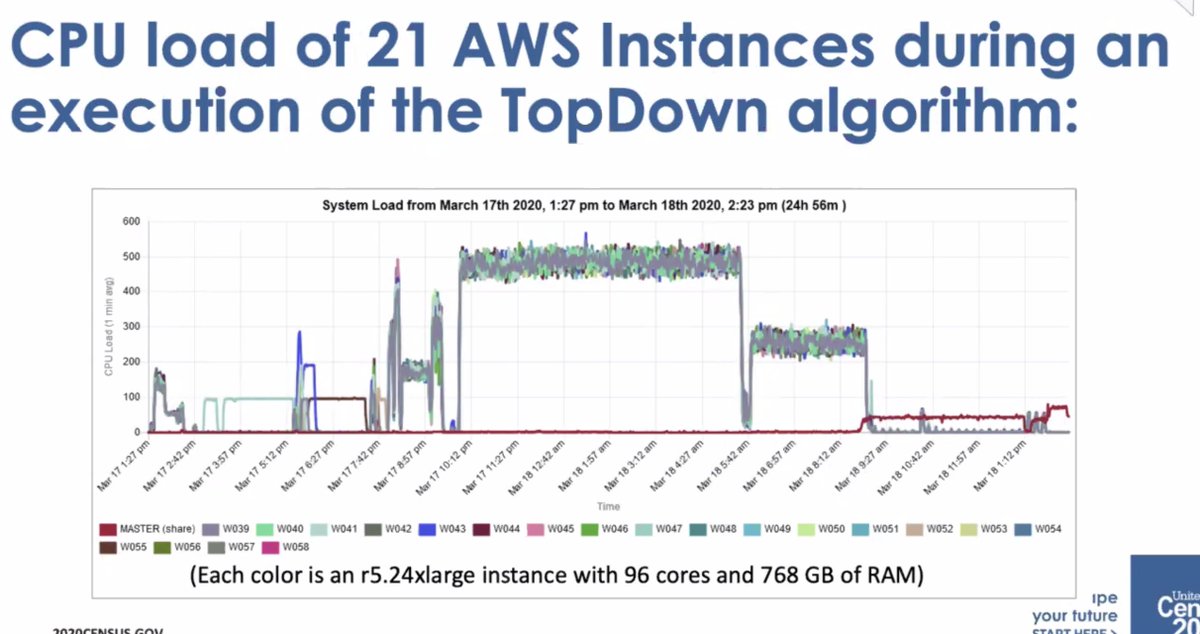
* then got to move to AWS Elastic compute... but the monitoring wasn't good enough and had to create their own dashboard to track execution
* it wasn't a small amount of compute
* ... it wasn't well-received by the data users who thought there was too much error
If you avoid that, you might add bias to the data. How to avoid that? Let some data users get access to the measurement files [I don't follow]

More from Lea Kissner




More from Tech


On press call, Zuckerberg says FB users "naturally engage more with sensational content" that comes close to violating its rules. Compares it to cable TV and tabloids, and says, "This seems to be true regardless of where we set our policy lines."
Zuckerberg says FB is in the process of setting up a "new independent body" that users will be able to appeal content takedowns to. Sort of like the "Facebook Supreme Court" idea he previewed earlier this year.
Zuckerberg: "One of my biggest lessons from this year is that when you connect more than 2 billion people, you’re going to see the good and bad of humanity."
This is how Facebook says it's trying to change the engagement pattern on its services. https://t.co/3p0PGc912o

.@RebeccaJarvis asks Zuckerberg if anyone is going to lose their job over the revelations in the NYT story. He dodges, says that personnel issues aren't a public matter, and that employee performance is evaluated all the time.
Zuckerberg says FB is in the process of setting up a "new independent body" that users will be able to appeal content takedowns to. Sort of like the "Facebook Supreme Court" idea he previewed earlier this year.
Zuckerberg: "One of my biggest lessons from this year is that when you connect more than 2 billion people, you’re going to see the good and bad of humanity."
This is how Facebook says it's trying to change the engagement pattern on its services. https://t.co/3p0PGc912o
.@RebeccaJarvis asks Zuckerberg if anyone is going to lose their job over the revelations in the NYT story. He dodges, says that personnel issues aren't a public matter, and that employee performance is evaluated all the time.







What an amazing presentation! Loved how @ravidharamshi77 brilliantly started off with global macros & capital markets, and then gradually migrated to Indian equities, summing up his thesis for a bull market case!
@MadhusudanKela @VQIndia @sameervq
My key learnings: ⬇️⬇️⬇️
First, the BEAR case:
1. Bitcoin has surpassed all the bubbles of the last 45 years in extent that includes Gold, Nikkei, dotcom bubble.
2. Cyclically adjusted PE ratio for S&P 500 almost at 1929 (The Great Depression) peaks, at highest levels except the dotcom crisis in 2000.
3. World market cap to GDP ratio presently at 124% vs last 5 years average of 92% & last 10 years average of 85%.
US market cap to GDP nearing 200%.
4. Bitcoin (as an asset class) has moved to the 3rd place in terms of price gains in preceding 3 years before peak (900%); 1st was Tulip bubble in 17th century (rising 2200%).
@MadhusudanKela @VQIndia @sameervq
My key learnings: ⬇️⬇️⬇️
Bubble or Bull Market? Join us for a short presentation and candid one on one on 27th Jan, 4pm with Shri \u2066@MadhusudanKela\u2069. \u2066@VQIndia\u2069 \u2066@sameervq\u2069 #bubbleorbullmarket pic.twitter.com/LBvlBrz6mS
— Ravi Dharamshi (@ravidharamshi77) January 24, 2021
First, the BEAR case:
1. Bitcoin has surpassed all the bubbles of the last 45 years in extent that includes Gold, Nikkei, dotcom bubble.
2. Cyclically adjusted PE ratio for S&P 500 almost at 1929 (The Great Depression) peaks, at highest levels except the dotcom crisis in 2000.
3. World market cap to GDP ratio presently at 124% vs last 5 years average of 92% & last 10 years average of 85%.
US market cap to GDP nearing 200%.
4. Bitcoin (as an asset class) has moved to the 3rd place in terms of price gains in preceding 3 years before peak (900%); 1st was Tulip bubble in 17th century (rising 2200%).
You May Also Like






So friends here is the thread on the recommended pathway for new entrants in the stock market.
Here I will share what I believe are essentials for anybody who is interested in stock markets and the resources to learn them, its from my experience and by no means exhaustive..
First the very basic : The Dow theory, Everybody must have basic understanding of it and must learn to observe High Highs, Higher Lows, Lower Highs and Lowers lows on charts and their
Even those who are more inclined towards fundamental side can also benefit from Dow theory, as it can hint start & end of Bull/Bear runs thereby indication entry and exits.
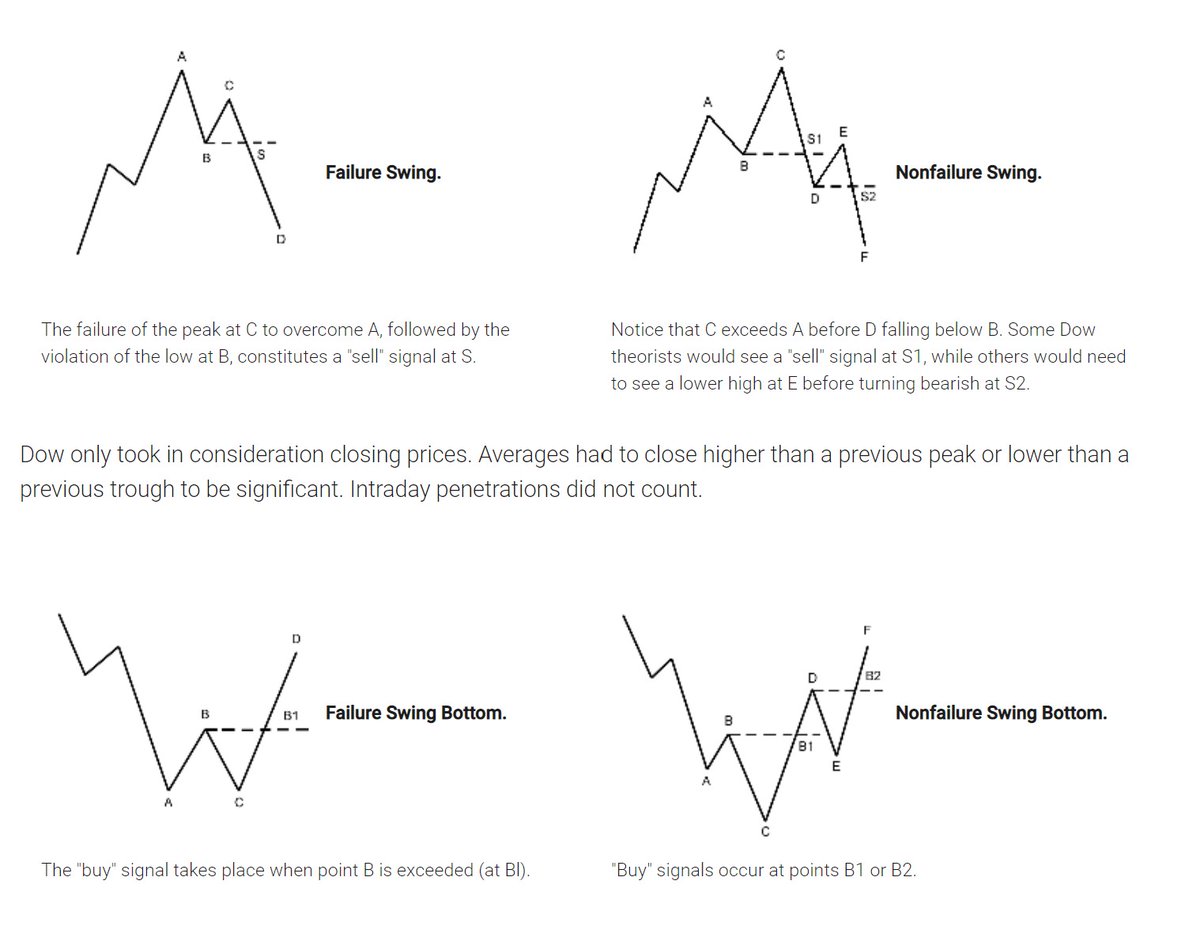
Next basic is Wyckoff's Theory. It tells how accumulation and distribution happens with regularity and how the market actually
Dow theory is old but
Here I will share what I believe are essentials for anybody who is interested in stock markets and the resources to learn them, its from my experience and by no means exhaustive..
First the very basic : The Dow theory, Everybody must have basic understanding of it and must learn to observe High Highs, Higher Lows, Lower Highs and Lowers lows on charts and their
Even those who are more inclined towards fundamental side can also benefit from Dow theory, as it can hint start & end of Bull/Bear runs thereby indication entry and exits.
Next basic is Wyckoff's Theory. It tells how accumulation and distribution happens with regularity and how the market actually
Dow theory is old but
Old is Gold....
— Professor (@DillikiBiili) January 23, 2020
this Bharti Airtel chart is a true copy of the Wyckoff Pattern propounded in 1931....... pic.twitter.com/tQ1PNebq7d




MDZS is laden with buddhist references. As a South Asian person, and history buff, it is so interesting to see how Buddhism, which originated from India, migrated, flourished & changed in the context of China. Here's some research (🙏🏼 @starkjeon for CN insight + citations)
1. LWJ’s sword Bichen ‘is likely an abbreviation for the term 躲避红尘 (duǒ bì hóng chén), which can be translated as such: 躲避: shunning or hiding away from 红尘 (worldly affairs; which is a buddhist teaching.) (https://t.co/zF65W3roJe) (abbrev. TWX)
2. Sandu (三 毒), Jiang Cheng’s sword, refers to the three poisons (triviṣa) in Buddhism; desire (kāma-taṇhā), delusion (bhava-taṇhā) and hatred (vibhava-taṇhā).
These 3 poisons represent the roots of craving (tanha) and are the cause of Dukkha (suffering, pain) and thus result in rebirth.
Interesting that MXTX used this name for one of the characters who suffers, arguably, the worst of these three emotions.
3. The Qian kun purse “乾坤袋 (qián kūn dài) – can be called “Heaven and Earth” Pouch. In Buddhism, Maitreya (मैत्रेय) owns this to store items. It was believed that there was a mythical space inside the bag that could absorb the world.” (TWX)
1. LWJ’s sword Bichen ‘is likely an abbreviation for the term 躲避红尘 (duǒ bì hóng chén), which can be translated as such: 躲避: shunning or hiding away from 红尘 (worldly affairs; which is a buddhist teaching.) (https://t.co/zF65W3roJe) (abbrev. TWX)
2. Sandu (三 毒), Jiang Cheng’s sword, refers to the three poisons (triviṣa) in Buddhism; desire (kāma-taṇhā), delusion (bhava-taṇhā) and hatred (vibhava-taṇhā).
These 3 poisons represent the roots of craving (tanha) and are the cause of Dukkha (suffering, pain) and thus result in rebirth.
Interesting that MXTX used this name for one of the characters who suffers, arguably, the worst of these three emotions.
3. The Qian kun purse “乾坤袋 (qián kūn dài) – can be called “Heaven and Earth” Pouch. In Buddhism, Maitreya (मैत्रेय) owns this to store items. It was believed that there was a mythical space inside the bag that could absorb the world.” (TWX)