
Next up at #enigma2021, Sanghyun Hong will be speaking about "A SOUND MIND IN A VULNERABLE BODY: PRACTICAL HARDWARE ATTACKS ON DEEP LEARNING"
(Hint: speaker is on the

* looks at the robustness in an isolated manner
* doesn't look at the whole ecosystem and how the model is used -- ML models are running in real hardware with real software which has real vulns!
e.g. fault injection attacks, side-channel attacks
* co-location of VMs from different users
* weak attackers with less subtle control
The cloud providers try to secure things, e.g. protections against Rowhammer
... BUT this focuses on the average or best case, not the worst cast!

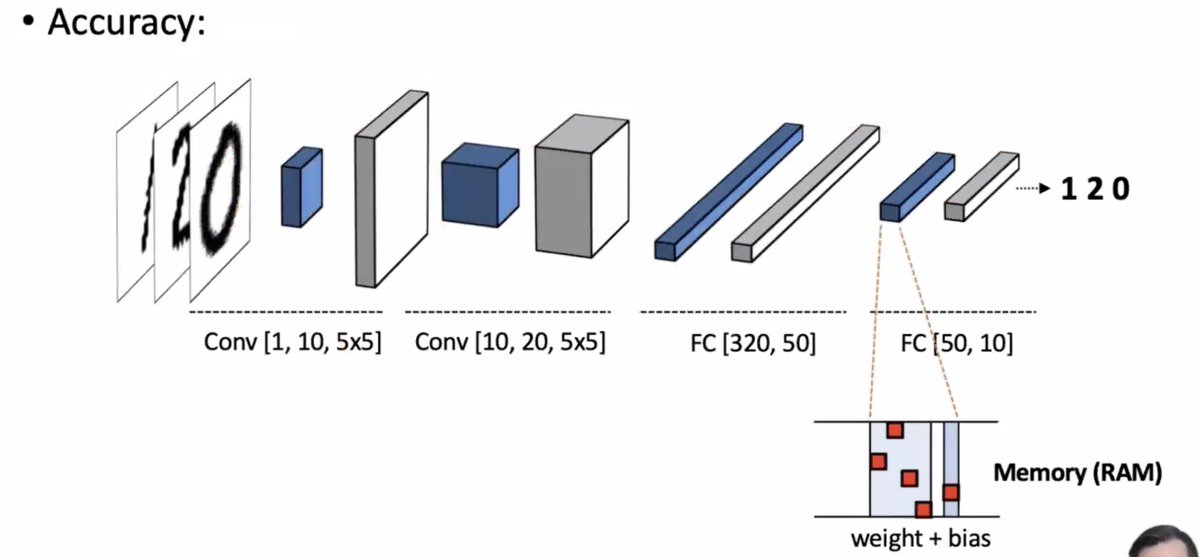
* negligible effect on the average case accuracy
* but flipping one bit can make significant amount of damage for particular queries
How much damage can a single bit flip cause?


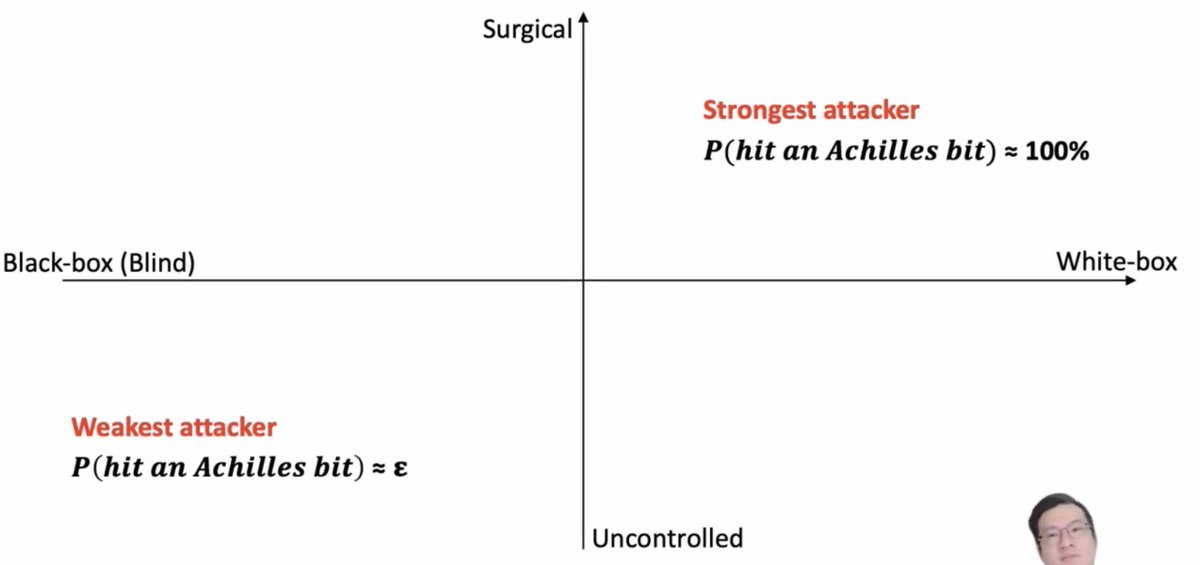
Some strong attackers might be able to hit an "achilles" bit (one that's really going to mess with the model), but weaker attackers are going to hit bits more randomly.


The attacker might want to get their hands on fancy DNNs which are considered trade secrets and proprietary to their creators. They're expensive to make! They need good training data! People want to protect them!
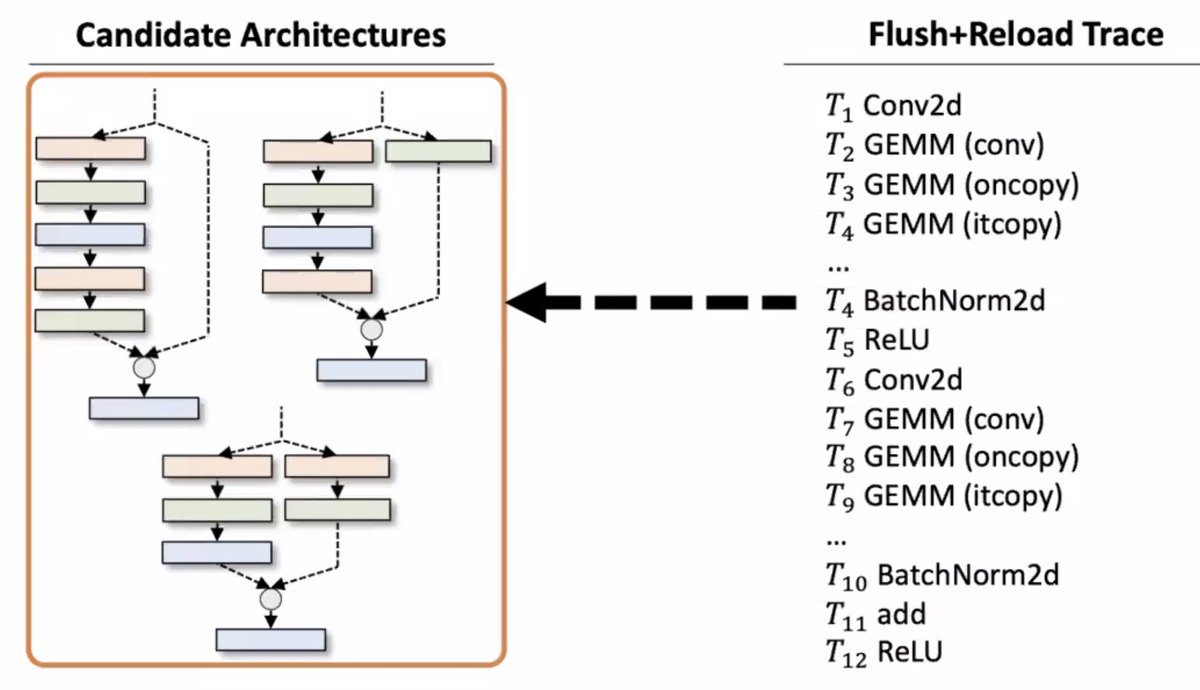
Does this work? Apparently so: they tried it out using a cache side-channel attack and got back the architectures of the fancy DNN back.

More from Lea Kissner





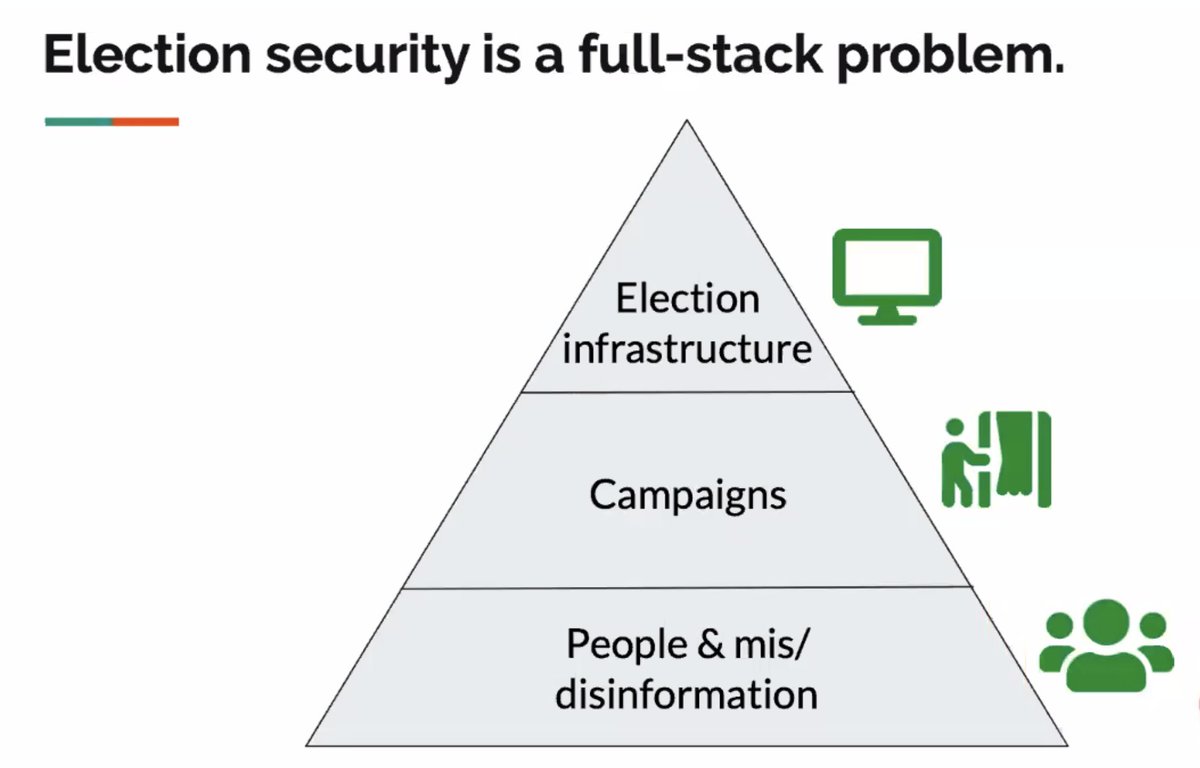
More from Science

#DDDD $LBPS $LOAC
A thread on the potential near term catalysts behind why I have increased my position in 4d Pharma @4dpharmaplc (LON: #DDDD):

1) NASDAQ listing. This is the most obvious.
The idea behind this is that the huge pool of capital and institutional interest in the NASDAQ will enable a higher per-share valuation for #DDDD than was achievable in the UK.
Comparators to @4dpharmaplc #DDDD (market capitalisation £150m) on the NASDAQ and their market capitalisation:
Seres Therapeutics: $2.33bn = £1.72bn (has had a successful phase 3 C. difficile trial); from my previous research (below) the chance of #DDDD achieving this at least once is at least
Kaleido Biosciences: $347m = £256m. 4 products under consideration, compared to #DDDD's potential 16. When you view @4dpharmaplc's 1000+ patents and AI-driven MicroRx platform (not to mention their end-to-end manufacturing capability), 4d's undervaluation is clear.
A thread on the potential near term catalysts behind why I have increased my position in 4d Pharma @4dpharmaplc (LON: #DDDD):
1) NASDAQ listing. This is the most obvious.
The idea behind this is that the huge pool of capital and institutional interest in the NASDAQ will enable a higher per-share valuation for #DDDD than was achievable in the UK.
Comparators to @4dpharmaplc #DDDD (market capitalisation £150m) on the NASDAQ and their market capitalisation:
Seres Therapeutics: $2.33bn = £1.72bn (has had a successful phase 3 C. difficile trial); from my previous research (below) the chance of #DDDD achieving this at least once is at least
While looking at speculative pharmaceutical stocks I am reminded of why I am averse to these risky picks.#DDDD was compelling enough, though, to break this rule. The 10+ treatments under trial, industry-leading IP portfolio, and comparable undervaluation are inescapable.
— Shrey Srivastava (@BlogShrey) December 16, 2020
Kaleido Biosciences: $347m = £256m. 4 products under consideration, compared to #DDDD's potential 16. When you view @4dpharmaplc's 1000+ patents and AI-driven MicroRx platform (not to mention their end-to-end manufacturing capability), 4d's undervaluation is clear.




It's another stunning Malagasy #dartfrog/#poisonfrog for today's #FrogOfTheDay, #42 Mantella cowani Boulenger, 1882! A highly threatened, actively conserved and managed frog from the highlands of central #Madagascar
#MadagascarFrogs
📸D.Edmonds/CalPhotos

This thread will cover only a tiny fraction of the work on Mantella cowanii because, being so charismatic and threatened, it has received quite a bit of attention.
#MadagascarFrogs
We start at the very beginning: the first specimens, two females, were collected by Reverend Deans Cowan in East Betsileo, Madagascar, and sent to London, where George Albert Boulenger described the species in 1882.
#MadagascarFrogs

Boulenger placed the species in his new genus, Mantella, along with ebenaui, betsileo, and madagascariensis. He recognised that the other Malagasy poison frogs were distinct from the Dendrobates of the Americas, although he did keep them in the Dendrobatidae.
#MadagascarFrogs
As more specimens were collected, it became clear that the species was highly variable. In 1978, Jean Guibé wrote with interest about this variability, describing a new subspecies, M. cowani nigricans—today a full species. #MadagascarFrogs
https://t.co/dwaHMbrYbj

#MadagascarFrogs
📸D.Edmonds/CalPhotos
This thread will cover only a tiny fraction of the work on Mantella cowanii because, being so charismatic and threatened, it has received quite a bit of attention.
#MadagascarFrogs
We start at the very beginning: the first specimens, two females, were collected by Reverend Deans Cowan in East Betsileo, Madagascar, and sent to London, where George Albert Boulenger described the species in 1882.
#MadagascarFrogs
Boulenger placed the species in his new genus, Mantella, along with ebenaui, betsileo, and madagascariensis. He recognised that the other Malagasy poison frogs were distinct from the Dendrobates of the Americas, although he did keep them in the Dendrobatidae.
#MadagascarFrogs
As more specimens were collected, it became clear that the species was highly variable. In 1978, Jean Guibé wrote with interest about this variability, describing a new subspecies, M. cowani nigricans—today a full species. #MadagascarFrogs
https://t.co/dwaHMbrYbj






















