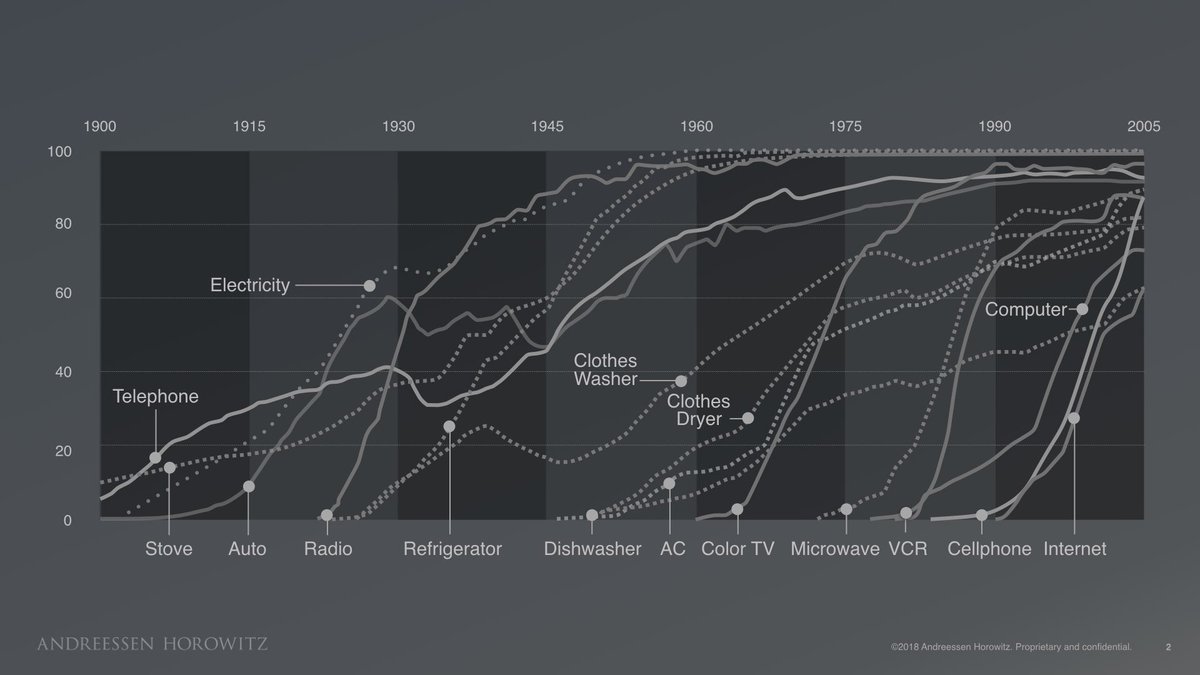
Technology is connected to the "tailpipes" of these facilities and is used to remove CO2 from the plant exhaust.
What is carbon capture? And how does it work?
While carbon capture is regularly discussed in the media, no one really ever explains what it is.
Below is a quick thread discussing the technology behind traditional carbon capture 👇
Technology is connected to the "tailpipes" of these facilities and is used to remove CO2 from the plant exhaust.
This step is called "sequestration" and is why experts often talks about "carbon capture and sequestration" or "CCS".
Currently, one of the most economic forms of carbon capture is called "amine-based" capture.
An "amine" is a special liquid chemical which selectively grabs on to CO2 molecules.
The exhaust bubbles up through the column, and the amine drips down.
The liquid amine and gas exhaust mix in the column.
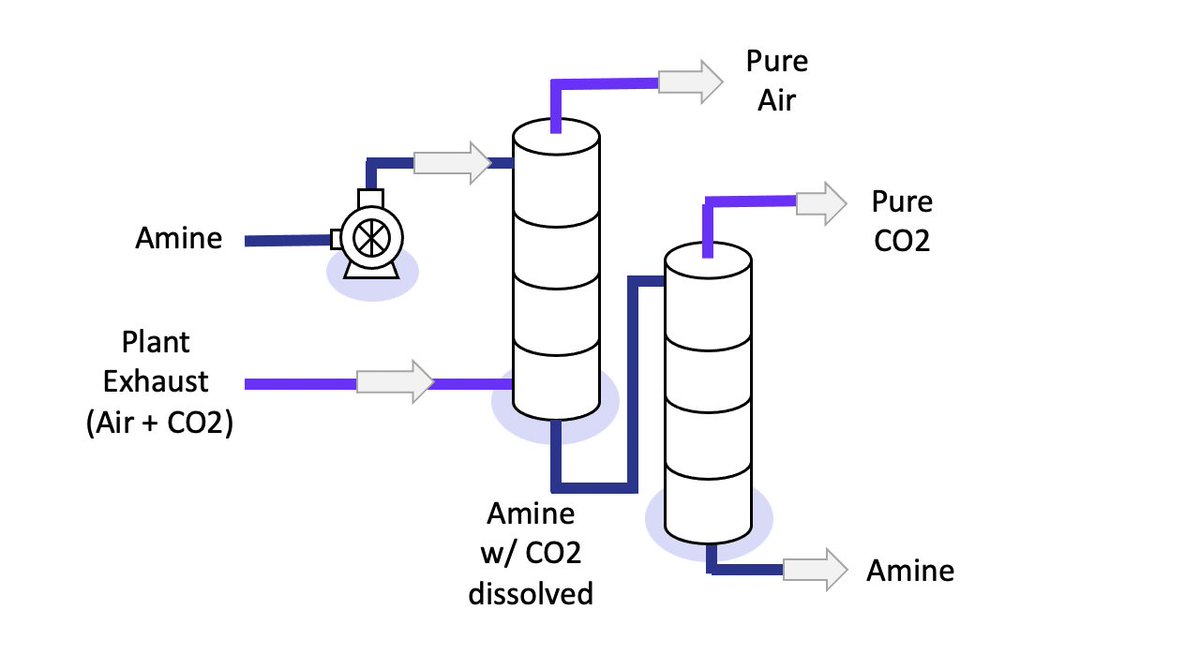
The amine with dissolved CO2 is sent into a second column where it is heated.
In the second column, the CO2 pops out of the amine.
Now, we have separated the CO2.
Below is a picture of an amine plant used for CO2 scrubbing.

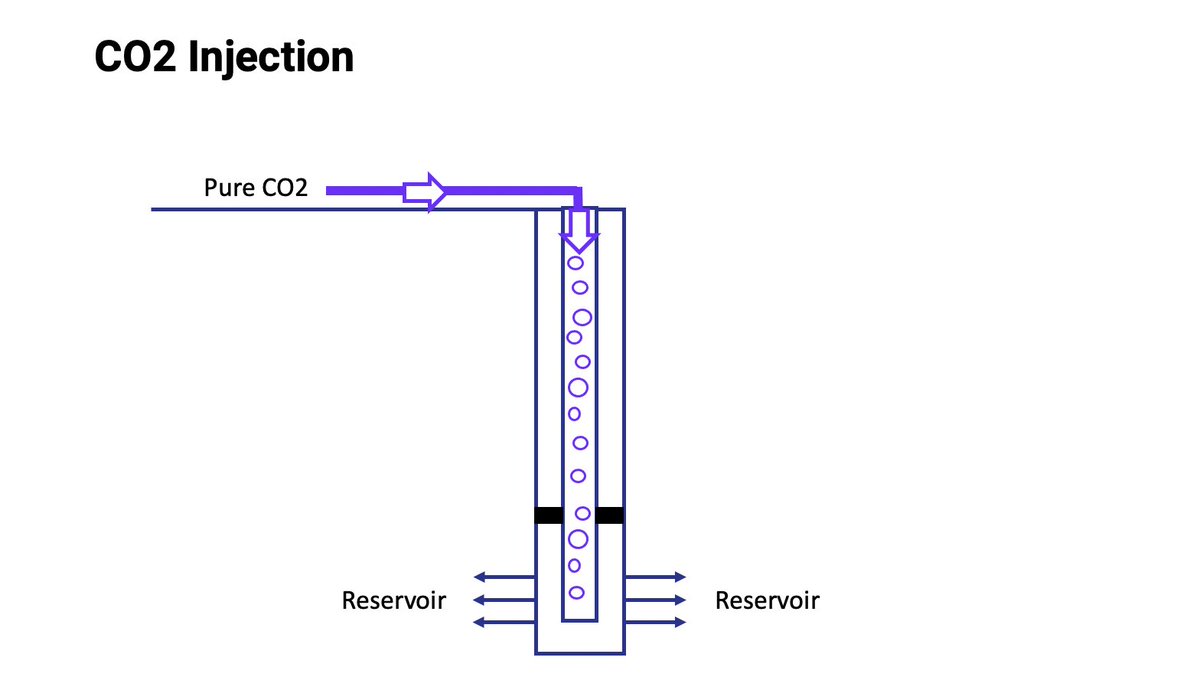
The CO2 is injected into a well for permanent storage underground, usually a few hundred yards away.
What I've described is called "point source capture" because it captures CO2 from a single plant exhaust
With new advances in technology, CO2 can also be captured directly from the air we breathe
More from Science







"The new answer to a 77-year-old problem"
😭
https://t.co/hm9NoaU4nr
https://t.co/8fKDiKjSWc
https://t.co/jkaicC1F2x
https://t.co/PpxWT4Jef4
😭
The new answer to a 77-year-old problem in data analysis, published today in @naturemethods. Instead of significance tests, use estimation graphics. Our software suite DABEST makes it easy for everyone to visualize effect sizes.https://t.co/UzwXJ7EUC5 pic.twitter.com/VtxyY0xaRM
— Adam Claridge-Chang (@adamcchang) June 19, 2019
https://t.co/hm9NoaU4nr
Open letter to journal editors: dynamite plots must die. Dynamite plots, also known as bar and line graphs, hide important information. Editors should require authors to show readers the data and avoid these plots. https://t.co/0GNKEIUCJL pic.twitter.com/OS9ytEFRZN
— Rafael Irizarry (@rafalab) February 22, 2019
https://t.co/8fKDiKjSWc
Couldn't find D3 code for grouped horisontal box plots that show data points so I made this @mbostock @thisisalfie https://t.co/cQjDPhyZdw pic.twitter.com/y6RNmDB2p3
— Ulrik Lyngs (@ulyngs) June 28, 2017
https://t.co/jkaicC1F2x
made a pkg for pirate plots in ggplot: add any of points/means/bars/CIs/violins \u2013 better than ye olde bar/box plotshttps://t.co/Z2m2kW3hsl pic.twitter.com/npAirPQexM
— Mika Braginsky (@mbraginsky) September 28, 2017
https://t.co/PpxWT4Jef4
See the new #PowerBI visual awesomeness for data points & sources, box-&-whisker plots! https://t.co/dOmgoxWfDE pic.twitter.com/HAUOAMJEJW
— Microsoft Power BI (@MSPowerBI) February 1, 2016

https://t.co/hXlo8qgkD0
Look like that they got a classical case of PCR Cross-Contamination.
They had 2 fabricated samples (SRX9714436 and SRX9714921) on the same PCR run. Alongside with Lung07. They did not perform metagenomic sequencing on the “feces” and they did not get

A positive oral or anal swab from anywhere in their sampling. Feces came from anus and if these were positive the anal swabs must also be positive. Clearly it got there after the NA have been extracted and were from the very low-level degraded RNA which were mutagenized from
The Taq. https://t.co/yKXCgiT29w to see SRX9714921 and SRX9714436.
Human+Mouse in the positive SRA, human in both of them. Seeing human+mouse in identical proportions across 3 different sequencers (PRJNA573298, A22, SEX9714436) are pretty straight indication that the originals
Were already contaminated with Human and mouse from the very beginning, and that this contamination is due to dishonesty in the sample handling process which prescribe a spiking of samples in ACE2-HEK293T/A549, VERO E6 and Human lung xenograft mouse.
The “lineages” they claimed to have found aren’t mutational lineages at all—all the mutations they see on these sequences were unique to that specific sequence, and are the result of RNA degradation and from the Taq polymerase errors accumulated from the nested PCR process

Look like that they got a classical case of PCR Cross-Contamination.
They had 2 fabricated samples (SRX9714436 and SRX9714921) on the same PCR run. Alongside with Lung07. They did not perform metagenomic sequencing on the “feces” and they did not get
A positive oral or anal swab from anywhere in their sampling. Feces came from anus and if these were positive the anal swabs must also be positive. Clearly it got there after the NA have been extracted and were from the very low-level degraded RNA which were mutagenized from
The Taq. https://t.co/yKXCgiT29w to see SRX9714921 and SRX9714436.
Human+Mouse in the positive SRA, human in both of them. Seeing human+mouse in identical proportions across 3 different sequencers (PRJNA573298, A22, SEX9714436) are pretty straight indication that the originals
Were already contaminated with Human and mouse from the very beginning, and that this contamination is due to dishonesty in the sample handling process which prescribe a spiking of samples in ACE2-HEK293T/A549, VERO E6 and Human lung xenograft mouse.
The “lineages” they claimed to have found aren’t mutational lineages at all—all the mutations they see on these sequences were unique to that specific sequence, and are the result of RNA degradation and from the Taq polymerase errors accumulated from the nested PCR process

This is a thread on statistics in science: 1/7 (via @LogicofScience)
Basic Statistics Part 1: The Law of Large Numbers https://t.co/wUH8eAAIak
#Science #Statistics

Basic Statistics Part 2: Correlation vs. Causation
https://t.co/Azhyl8pDsX (2/7)
Basic Statistics Part 3: The Dangers of Large Data Sets: A Tale of P values, Error Rates, and Bonferroni Corrections
https://t.co/LetN6aEBRM (3/7)
Basic statistics part 4: understanding P values
https://t.co/K8MMMgTCOf (4/7)
Basic Statistics Part 5: Means vs Medians, Is the “Average”
Basic Statistics Part 1: The Law of Large Numbers https://t.co/wUH8eAAIak
#Science #Statistics
Basic Statistics Part 2: Correlation vs. Causation
https://t.co/Azhyl8pDsX (2/7)
Basic Statistics Part 3: The Dangers of Large Data Sets: A Tale of P values, Error Rates, and Bonferroni Corrections
https://t.co/LetN6aEBRM (3/7)
Basic statistics part 4: understanding P values
https://t.co/K8MMMgTCOf (4/7)
Basic Statistics Part 5: Means vs Medians, Is the “Average”