
1 There's a chasm between an NLP technology that works well in the research lab and something that works for applications that real people use. This was eye-opening when I started my career, and every time I talk to an NLP engineer at @textio, it continues to strike me even now.
More from Machine learning

Happy 2⃣0⃣2⃣1⃣ to all.🎇
For any Learning machines out there, here are a list of my fav online investing resources. Feel free to add yours.
Let's dive in.
⬇️⬇️⬇️
Investing Services
✔️ @themotleyfool - @TMFStockAdvisor & @TMFRuleBreakers services
✔️ @7investing
✔️ @investing_city
https://t.co/9aUK1Tclw4
✔️ @MorningstarInc Premium
✔️ @SeekingAlpha Marketplaces (Check your area of interest, Free trials, Quality, track record...)
General Finance/Investing
✔️ @morganhousel
https://t.co/f1joTRaG55
✔️ @dollarsanddata
https://t.co/Mj1owkzRc8
✔️ @awealthofcs
https://t.co/y81KHfh8cn
✔️ @iancassel
https://t.co/KEMTBHa8Qk
✔️ @InvestorAmnesia
https://t.co/zFL3H2dk6s
✔️
Tech focused
✔️ @stratechery
https://t.co/VsNwRStY9C
✔️ @bgurley
https://t.co/NKXGtaB6HQ
✔️ @CBinsights
https://t.co/H77hNp2X5R
✔️ @benedictevans
https://t.co/nyOlasCY1o
✔️
Tech Deep dives
✔️ @StackInvesting
https://t.co/WQ1yBYzT2m
✔️ @hhhypergrowth
https://t.co/kcLKITRLz1
✔️ @Beth_Kindig
https://t.co/CjhLRdP7Rh
✔️ @SeifelCapital
https://t.co/CXXG5PY0xX
✔️ @borrowed_ideas
For any Learning machines out there, here are a list of my fav online investing resources. Feel free to add yours.
Let's dive in.
⬇️⬇️⬇️
Investing Services
✔️ @themotleyfool - @TMFStockAdvisor & @TMFRuleBreakers services
✔️ @7investing
✔️ @investing_city
https://t.co/9aUK1Tclw4
✔️ @MorningstarInc Premium
✔️ @SeekingAlpha Marketplaces (Check your area of interest, Free trials, Quality, track record...)
General Finance/Investing
✔️ @morganhousel
https://t.co/f1joTRaG55
✔️ @dollarsanddata
https://t.co/Mj1owkzRc8
✔️ @awealthofcs
https://t.co/y81KHfh8cn
✔️ @iancassel
https://t.co/KEMTBHa8Qk
✔️ @InvestorAmnesia
https://t.co/zFL3H2dk6s
✔️
Tech focused
✔️ @stratechery
https://t.co/VsNwRStY9C
✔️ @bgurley
https://t.co/NKXGtaB6HQ
✔️ @CBinsights
https://t.co/H77hNp2X5R
✔️ @benedictevans
https://t.co/nyOlasCY1o
✔️
Tech Deep dives
✔️ @StackInvesting
https://t.co/WQ1yBYzT2m
✔️ @hhhypergrowth
https://t.co/kcLKITRLz1
✔️ @Beth_Kindig
https://t.co/CjhLRdP7Rh
✔️ @SeifelCapital
https://t.co/CXXG5PY0xX
✔️ @borrowed_ideas





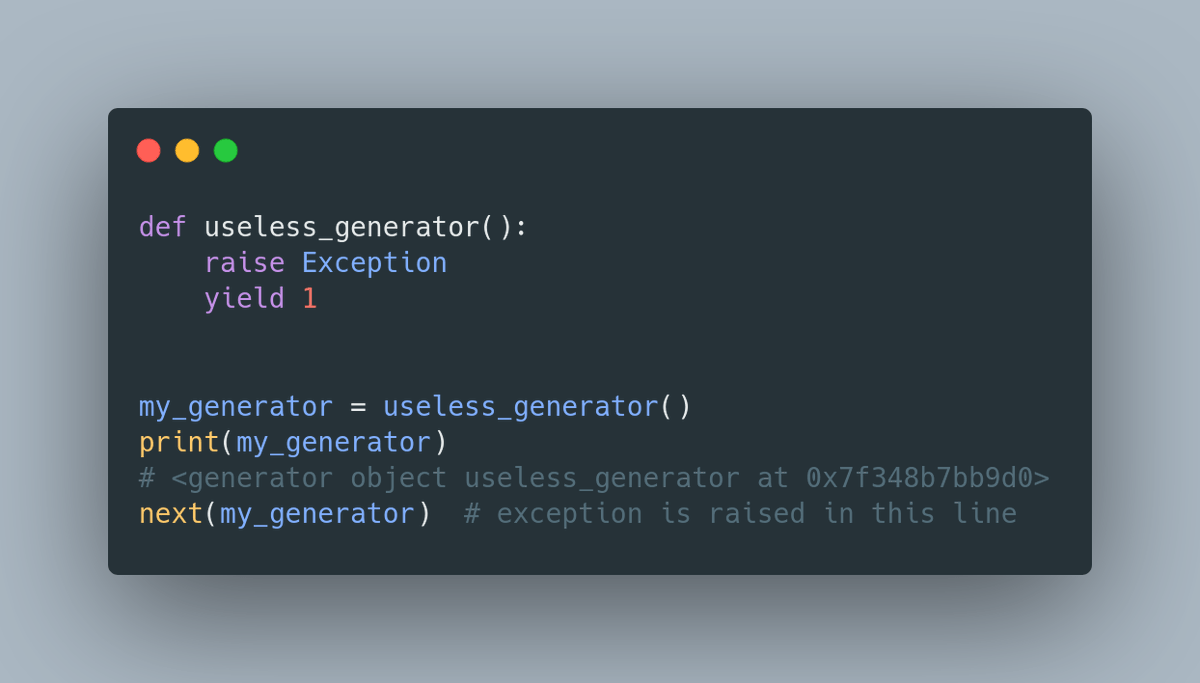


Starting a new project using #Angular? Here is a list of all the stuff i use to launch my projects the fastest i can.
A THREAD 👇
Have you heard about Monorepo? I created one with all my Angular (and Nest) projects using https://t.co/aY5llDtXg8.
I can share A LOT of code with it. Ex: Everytime i start a new project, i just need to import an Auth lib, that i created, and all Auth related stuff is set up.
Everyone in the Angular community knows about https://t.co/kDnunQZnxE. It's not the most beautiful component library out there, but it's good and easy to work with.
There's a bunch of state management solutions for Angular, but https://t.co/RJwpn74Qev is by far my favorite.
There's a lot of boilerplate, but you can solve this with the built-in schematics and/or with your own schematics
Are you not using custom schematics yet? Take a look at this:
https://t.co/iLrIaHVafm
https://t.co/3382Tn2k7C
You can automate all the boilerplate with hundreds of files associates with creating a new feature.
A THREAD 👇
Have you heard about Monorepo? I created one with all my Angular (and Nest) projects using https://t.co/aY5llDtXg8.
I can share A LOT of code with it. Ex: Everytime i start a new project, i just need to import an Auth lib, that i created, and all Auth related stuff is set up.
Everyone in the Angular community knows about https://t.co/kDnunQZnxE. It's not the most beautiful component library out there, but it's good and easy to work with.
There's a bunch of state management solutions for Angular, but https://t.co/RJwpn74Qev is by far my favorite.
There's a lot of boilerplate, but you can solve this with the built-in schematics and/or with your own schematics
Are you not using custom schematics yet? Take a look at this:
https://t.co/iLrIaHVafm
https://t.co/3382Tn2k7C
You can automate all the boilerplate with hundreds of files associates with creating a new feature.
You May Also Like






THREAD PART 1.
On Sunday 21st June, 14 year old Noah Donohoe left his home to meet his friends at Cave Hill Belfast to study for school. #RememberMyNoah💙

He was on his black Apollo mountain bike, fully dressed, wearing a helmet and carrying a backpack containing his laptop and 2 books with his name on them. He also had his mobile phone with him.
On the 27th of June. Noah's naked body was sadly discovered 950m inside a storm drain, between access points. This storm drain was accessible through an area completely unfamiliar to him, behind houses at Northwood Road. https://t.co/bpz3Rmc0wq
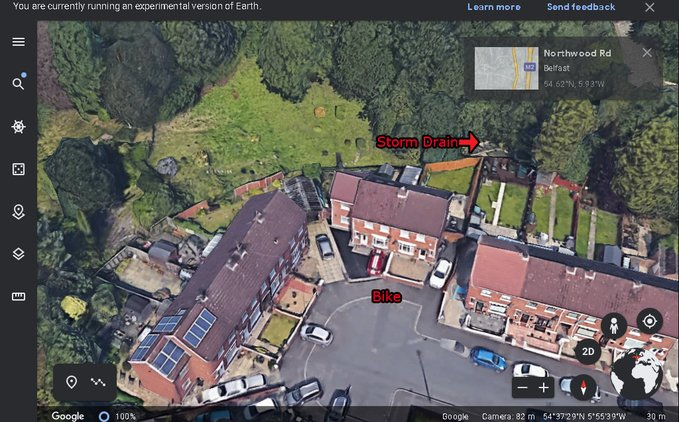
"Noah's body was found by specially trained police officers between two drain access points within a section of the tunnel running under the Translink access road," said Mr McCrisken."
Noah's bike was also found near a house, behind a car, in the same area. It had been there for more than 24 hours before a member of public who lived in the street said she read reports of a missing child and checked the bike and phoned the police.
On Sunday 21st June, 14 year old Noah Donohoe left his home to meet his friends at Cave Hill Belfast to study for school. #RememberMyNoah💙
He was on his black Apollo mountain bike, fully dressed, wearing a helmet and carrying a backpack containing his laptop and 2 books with his name on them. He also had his mobile phone with him.
On the 27th of June. Noah's naked body was sadly discovered 950m inside a storm drain, between access points. This storm drain was accessible through an area completely unfamiliar to him, behind houses at Northwood Road. https://t.co/bpz3Rmc0wq
"Noah's body was found by specially trained police officers between two drain access points within a section of the tunnel running under the Translink access road," said Mr McCrisken."
Noah's bike was also found near a house, behind a car, in the same area. It had been there for more than 24 hours before a member of public who lived in the street said she read reports of a missing child and checked the bike and phoned the police.






