
12 straightforward quotes on self-care:
1.

Read the book "Live Intentionally" to change your: ~
Habits
~ Daily routine
~ Mindset
~ Become strong
~ Disciplined.
Get your copy:
https://t.co/xUNhwAzbr9
For more content like this and retweet the first tweet to share with others:
https://t.co/csfVxVGfPR
12 straightforward quotes on self-care:
— Strong Minded (@strongminded101) October 3, 2022
1. pic.twitter.com/0vswwjrLbh
More from All























You May Also Like

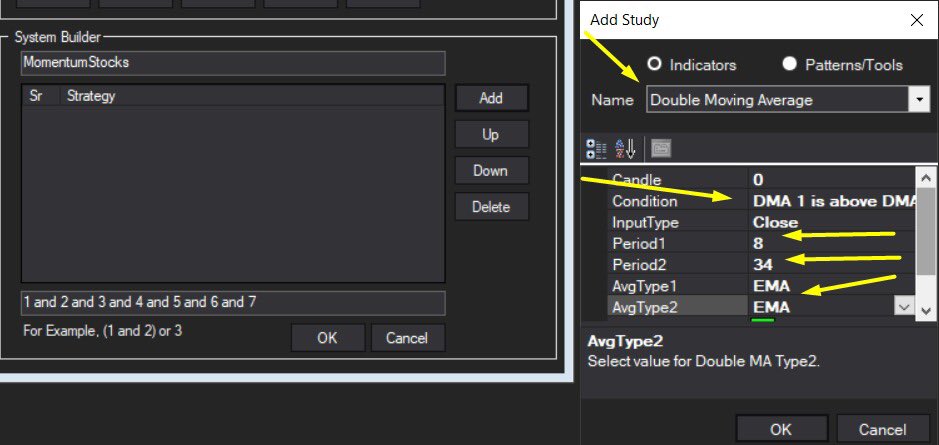
Took me 5 years to get the best Chartink scanners for Stock Market, but you’ll get it in 5 mminutes here ⏰
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times











Facebook originally a CIA program called "LifeLog".
LifeLog, via DARPA, terminated on Feb 4th, 2004.
Facebook was launched on Feb 4th, 2004.
Many of the LifeLog team became execs at FB.
Zuckerberg is a figurehead.
CIA allowed Cambridge to help Trump win
https://t.co/enzOXDCogV

Pentagon Kills LifeLog
LifeLog, via DARPA, terminated on Feb 4th, 2004.
Facebook was launched on Feb 4th, 2004.
Many of the LifeLog team became execs at FB.
Zuckerberg is a figurehead.
CIA allowed Cambridge to help Trump win
https://t.co/enzOXDCogV
Project: Lifelog
— Robert Horan (@Robby12692) December 13, 2018
Started by DARPA in 1999, the goal of Lifelog was to create a database on civilians without their knowledge, and track everything they do.
The project "ended" on Feb 4th, 2004.
Facebook began the exact same day.
The CIA funneled tens of millions into Facebook. pic.twitter.com/r7hwF0v9kh
Pentagon Kills LifeLog

