

Recently I learned something about DNA that blew my mind, and in this thread, I'll attempt to blow your mind as well. Behold: Chargaff's 2nd Parity Rule for DNA N-Grams.
If you are into cryptography or reverse engineering, you should love this.
Thread:

T G T C A G T
A C A G T C A
(note how the other strand is upside down - this matters!)

This is called Chargaff's 1st parity rule.
https://t.co/jD4cMt0PJ0

This is called Chargaff's 2nd parity rule.


For N=2, this says that percentage of CC (%CC) and %GG are also equal, as are %AG and %CT (complemented AND reversed) etc.



More from Science

@mugecevik is an excellent scientist and a responsible professional. She likely read the paper more carefully than most. She grasped some of its strengths and weaknesses that are not apparent from a cursory glance. Below, I will mention a few points some may have missed.
1/
The paper does NOT evaluate the effect of school closures. Instead it conflates all ‘educational settings' into a single category, which includes universities.
2/
The paper primarily evaluates data from March and April 2020. The article is not particularly clear about this limitation, but the information can be found in the hefty supplementary material.
3/

The authors applied four different regression methods (some fancier than others) to the same data. The outcomes of the different regression models are correlated (enough to reach statistical significance), but they vary a lot. (heat map on the right below).
4/
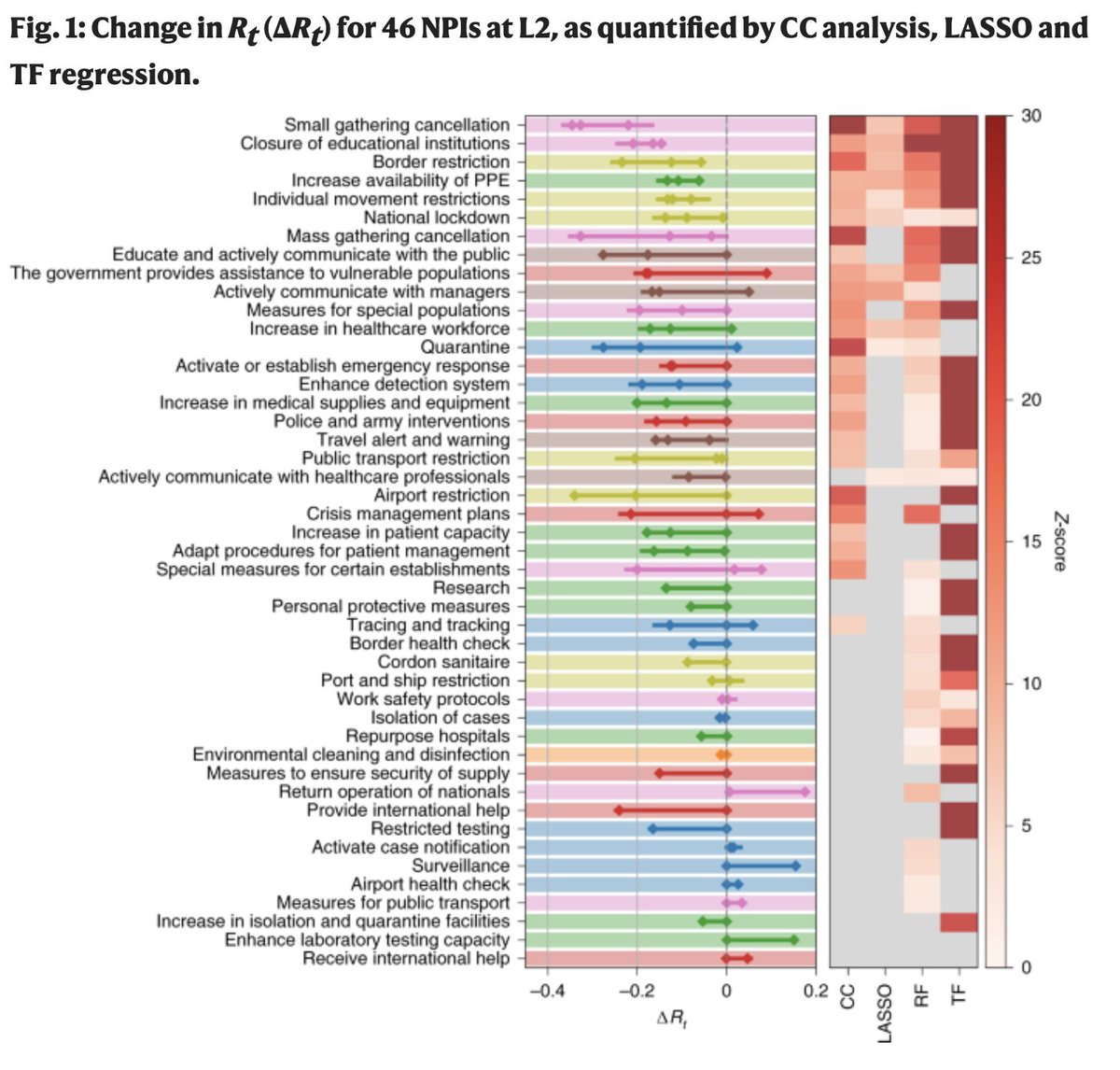
The effect of individual interventions is extremely difficult to disentangle as the authors stress themselves. There is a very large number of interventions considered and the model was run on 49 countries and 26 US States (and not >200 countries).
5/

1/
I've recently come across a disinformation around evidence relating to school closures and community transmission that's been platformed prominently. This arises from flawed understanding of the data that underlies this evidence, and the methodologies used in these studies. pic.twitter.com/VM7cVKghgj
— Deepti Gurdasani (@dgurdasani1) February 1, 2021
The paper does NOT evaluate the effect of school closures. Instead it conflates all ‘educational settings' into a single category, which includes universities.
2/
The paper primarily evaluates data from March and April 2020. The article is not particularly clear about this limitation, but the information can be found in the hefty supplementary material.
3/
The authors applied four different regression methods (some fancier than others) to the same data. The outcomes of the different regression models are correlated (enough to reach statistical significance), but they vary a lot. (heat map on the right below).
4/
The effect of individual interventions is extremely difficult to disentangle as the authors stress themselves. There is a very large number of interventions considered and the model was run on 49 countries and 26 US States (and not >200 countries).
5/





You May Also Like

A brief analysis and comparison of the CSS for Twitter's PWA vs Twitter's legacy desktop website. The difference is dramatic and I'll touch on some reasons why.
Legacy site *downloads* ~630 KB CSS per theme and writing direction.
6,769 rules
9,252 selectors
16.7k declarations
3,370 unique declarations
44 media queries
36 unique colors
50 unique background colors
46 unique font sizes
39 unique z-indices
https://t.co/qyl4Bt1i5x

PWA *incrementally generates* ~30 KB CSS that handles all themes and writing directions.
735 rules
740 selectors
757 declarations
730 unique declarations
0 media queries
11 unique colors
32 unique background colors
15 unique font sizes
7 unique z-indices
https://t.co/w7oNG5KUkJ

The legacy site's CSS is what happens when hundreds of people directly write CSS over many years. Specificity wars, redundancy, a house of cards that can't be fixed. The result is extremely inefficient and error-prone styling that punishes users and developers.
The PWA's CSS is generated on-demand by a JS framework that manages styles and outputs "atomic CSS". The framework can enforce strict constraints and perform optimisations, which is why the CSS is so much smaller and safer. Style conflicts and unbounded CSS growth are avoided.
Legacy site *downloads* ~630 KB CSS per theme and writing direction.
6,769 rules
9,252 selectors
16.7k declarations
3,370 unique declarations
44 media queries
36 unique colors
50 unique background colors
46 unique font sizes
39 unique z-indices
https://t.co/qyl4Bt1i5x
PWA *incrementally generates* ~30 KB CSS that handles all themes and writing directions.
735 rules
740 selectors
757 declarations
730 unique declarations
0 media queries
11 unique colors
32 unique background colors
15 unique font sizes
7 unique z-indices
https://t.co/w7oNG5KUkJ
The legacy site's CSS is what happens when hundreds of people directly write CSS over many years. Specificity wars, redundancy, a house of cards that can't be fixed. The result is extremely inefficient and error-prone styling that punishes users and developers.
The PWA's CSS is generated on-demand by a JS framework that manages styles and outputs "atomic CSS". The framework can enforce strict constraints and perform optimisations, which is why the CSS is so much smaller and safer. Style conflicts and unbounded CSS growth are avoided.






IMPORTANCE, ADVANTAGES AND CHARACTERISTICS OF BHAGWAT PURAN
It was Ved Vyas who edited the eighteen thousand shlokas of Bhagwat. This book destroys all your sins. It has twelve parts which are like kalpvraksh.
In the first skandh, the importance of Vedvyas

and characters of Pandavas are described by the dialogues between Suutji and Shaunakji. Then there is the story of Parikshit.
Next there is a Brahm Narad dialogue describing the avtaar of Bhagwan. Then the characteristics of Puraan are mentioned.
It also discusses the evolution of universe.( https://t.co/2aK1AZSC79 )
Next is the portrayal of Vidur and his dialogue with Maitreyji. Then there is a mention of Creation of universe by Brahma and the preachings of Sankhya by Kapil Muni.
In the next section we find the portrayal of Sati, Dhruv, Pruthu, and the story of ancient King, Bahirshi.
In the next section we find the character of King Priyavrat and his sons, different types of loks in this universe, and description of Narak. ( https://t.co/gmDTkLktKS )
In the sixth part we find the portrayal of Ajaamil ( https://t.co/LdVSSNspa2 ), Daksh and the birth of Marudgans( https://t.co/tecNidVckj )
In the seventh section we find the story of Prahlad and the description of Varnashram dharma. This section is based on karma vaasna.
It was Ved Vyas who edited the eighteen thousand shlokas of Bhagwat. This book destroys all your sins. It has twelve parts which are like kalpvraksh.
In the first skandh, the importance of Vedvyas
and characters of Pandavas are described by the dialogues between Suutji and Shaunakji. Then there is the story of Parikshit.
Next there is a Brahm Narad dialogue describing the avtaar of Bhagwan. Then the characteristics of Puraan are mentioned.
It also discusses the evolution of universe.( https://t.co/2aK1AZSC79 )
Next is the portrayal of Vidur and his dialogue with Maitreyji. Then there is a mention of Creation of universe by Brahma and the preachings of Sankhya by Kapil Muni.
HOW LIFE EVOLVED IN THIS UNIVERSE AS PER OUR SCRIPTURES.
— Anshul Pandey (@Anshulspiritual) August 29, 2020
Well maximum of Living being are the Vansaj of Rishi Kashyap. I have tried to give stories from different-different Puran. So lets start.... pic.twitter.com/MrrTS4xORk
In the next section we find the portrayal of Sati, Dhruv, Pruthu, and the story of ancient King, Bahirshi.
In the next section we find the character of King Priyavrat and his sons, different types of loks in this universe, and description of Narak. ( https://t.co/gmDTkLktKS )
Thread on NARK(HELL) / \u0928\u0930\u094d\u0915
— Anshul Pandey (@Anshulspiritual) August 11, 2020
Well today i will take you to a journey where nobody wants to go i.e Nark. Hence beware of doing Adharma/Evil things. There are various mentions in Puranas about Nark, But my Thread is only as per Bhagwat puran(SS attached in below Thread)
1/8 pic.twitter.com/raHYWtB53Q
In the sixth part we find the portrayal of Ajaamil ( https://t.co/LdVSSNspa2 ), Daksh and the birth of Marudgans( https://t.co/tecNidVckj )
In the seventh section we find the story of Prahlad and the description of Varnashram dharma. This section is based on karma vaasna.
#THREAD
— Anshul Pandey (@Anshulspiritual) August 12, 2020
WHY PARENTS CHOOSE RELIGIOUS OR PARAMATMA'S NAMES FOR THEIR CHILDREN AND WHICH ARE THE EASIEST WAY TO WASH AWAY YOUR SINS.
Yesterday I had described the types of Naraka's and the Sin or Adharma for a person to be there.
1/8 pic.twitter.com/XjPB2hfnUC