
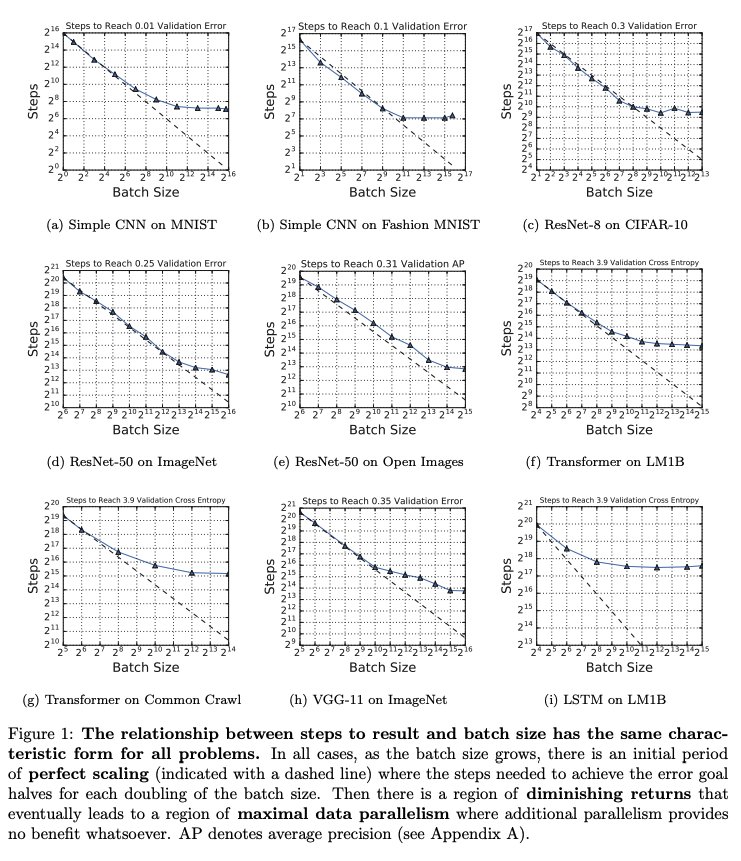
Important paper from Google on large batch optimization. They do impressively careful experiments measuring # iterations needed to achieve target validation error at various batch sizes. The main "surprise" is the lack of surprises. [thread]
https://t.co/7QIx5CFdfJ
More from Machine learning

This is a Twitter series on #FoundationsOfML.
❓ Today, I want to start discussing the different types of Machine Learning flavors we can find.
This is a very high-level overview. In later threads, we'll dive deeper into each paradigm... 👇🧵
Last time we talked about how Machine Learning works.
Basically, it's about having some source of experience E for solving a given task T, that allows us to find a program P which is (hopefully) optimal w.r.t. some metric
According to the nature of that experience, we can define different formulations, or flavors, of the learning process.
A useful distinction is whether we have an explicit goal or desired output, which gives rise to the definitions of 1️⃣ Supervised and 2️⃣ Unsupervised Learning 👇
1️⃣ Supervised Learning
In this formulation, the experience E is a collection of input/output pairs, and the task T is defined as a function that produces the right output for any given input.
👉 The underlying assumption is that there is some correlation (or, in general, a computable relation) between the structure of an input and its corresponding output and that it is possible to infer that function or mapping from a sufficiently large number of examples.
❓ Today, I want to start discussing the different types of Machine Learning flavors we can find.
This is a very high-level overview. In later threads, we'll dive deeper into each paradigm... 👇🧵
Last time we talked about how Machine Learning works.
Basically, it's about having some source of experience E for solving a given task T, that allows us to find a program P which is (hopefully) optimal w.r.t. some metric
I'm starting a Twitter series on #FoundationsOfML. Today, I want to answer this simple question.
— Alejandro Piad Morffis (@AlejandroPiad) January 12, 2021
\u2753 What is Machine Learning?
This is my preferred way of explaining it... \U0001f447\U0001f9f5
According to the nature of that experience, we can define different formulations, or flavors, of the learning process.
A useful distinction is whether we have an explicit goal or desired output, which gives rise to the definitions of 1️⃣ Supervised and 2️⃣ Unsupervised Learning 👇
1️⃣ Supervised Learning
In this formulation, the experience E is a collection of input/output pairs, and the task T is defined as a function that produces the right output for any given input.
👉 The underlying assumption is that there is some correlation (or, in general, a computable relation) between the structure of an input and its corresponding output and that it is possible to infer that function or mapping from a sufficiently large number of examples.


Really enjoyed digging into recent innovations in the football analytics industry.
>10 hours of interviews for this w/ a dozen or so of top firms in the game. Really grateful to everyone who gave up time & insights, even those that didnt make final cut 🙇♂️ https://t.co/9YOSrl8TdN
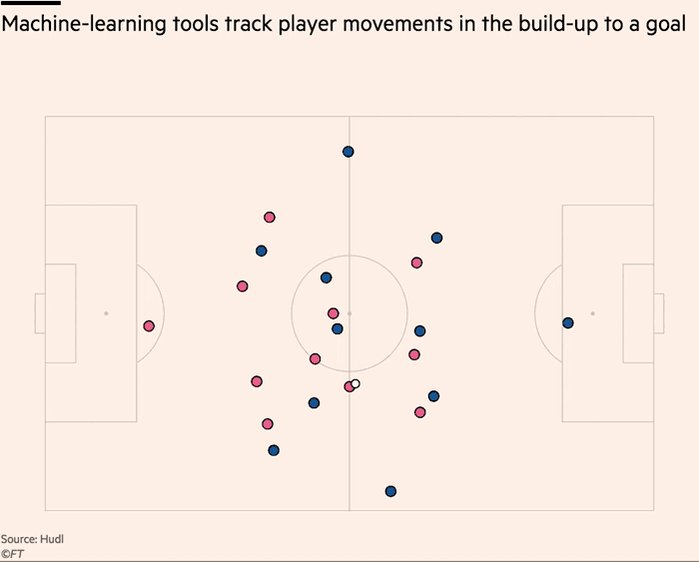
For avoidance of doubt, leading tracking analytics firms are now well beyond voronoi diagrams, using more granular measures to assess control and value of space.
This @JaviOnData & @LukeBornn paper from 2018 referenced in the piece demonstrates one method https://t.co/Hx8XTUMpJ5

Bit of this that I nerded out on the most is "ghosting" — technique used by @counterattack9 & co @stats_insights, among others.
Deep learning models predict how specific players — operating w/in specific setups — will move & execute actions. A paper here: https://t.co/9qrKvJ70EN
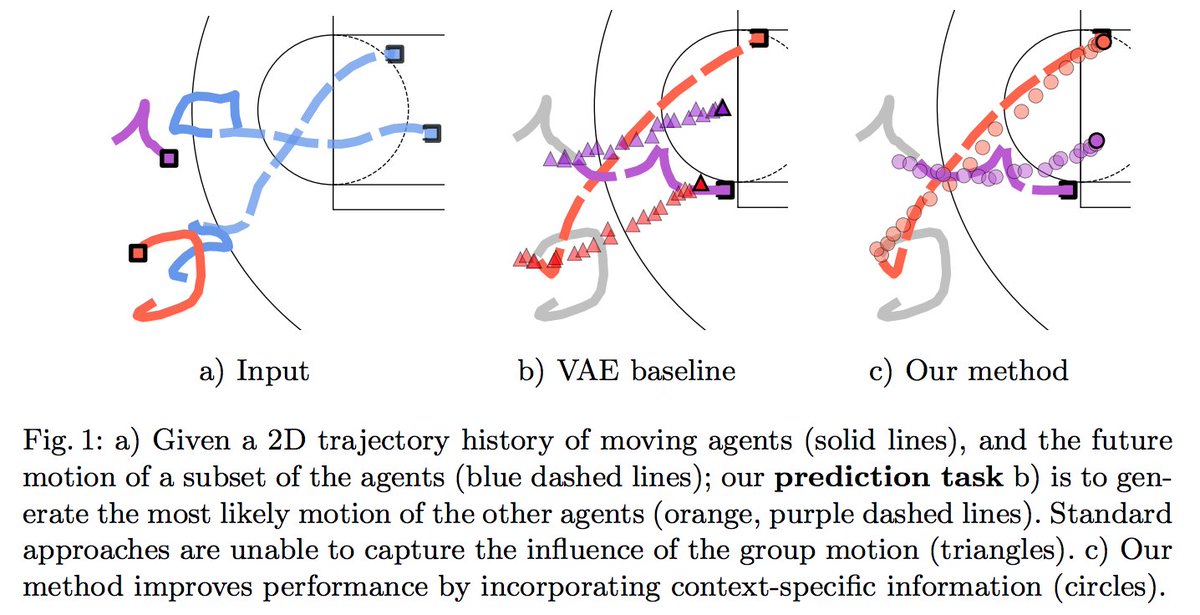
So many use-cases:
1/ Quickly & automatically spot situations where opponent's defence is abnormally vulnerable. Drill those to death in training.
2/ Swap target player B in for current player A, and simulate. How does target player strengthen/weaken team? In specific situations?
>10 hours of interviews for this w/ a dozen or so of top firms in the game. Really grateful to everyone who gave up time & insights, even those that didnt make final cut 🙇♂️ https://t.co/9YOSrl8TdN
For avoidance of doubt, leading tracking analytics firms are now well beyond voronoi diagrams, using more granular measures to assess control and value of space.
This @JaviOnData & @LukeBornn paper from 2018 referenced in the piece demonstrates one method https://t.co/Hx8XTUMpJ5
Bit of this that I nerded out on the most is "ghosting" — technique used by @counterattack9 & co @stats_insights, among others.
Deep learning models predict how specific players — operating w/in specific setups — will move & execute actions. A paper here: https://t.co/9qrKvJ70EN
So many use-cases:
1/ Quickly & automatically spot situations where opponent's defence is abnormally vulnerable. Drill those to death in training.
2/ Swap target player B in for current player A, and simulate. How does target player strengthen/weaken team? In specific situations?


You May Also Like

H was always unseen in S2NL :)
Those who exited at 1500 needed money. They can always come back near 969. Those who exited at 230 also needed money. They can come back near 95.
Those who sold L @ 660 can always come back at 360. Those who sold S last week can be back @ 301
Those who exited at 1500 needed money. They can always come back near 969. Those who exited at 230 also needed money. They can come back near 95.
Those who sold L @ 660 can always come back at 360. Those who sold S last week can be back @ 301
Sir, Log yahan.. 13 days patience nhi rakh sakte aur aap 2013 ki baat kar rahe ho. Even Aap Ready made portfolio banakar bhi de do to bhi wo 1 month me hi EXIT kar denge \U0001f602
— BhavinKhengarSuratGujarat (@IntradayWithBRK) September 19, 2021
Neuland 2700 se 1500 & Sequent 330 to 230 kya huwa.. 99% retailers/investors twitter par charcha n EXIT\U0001f602

This is NONSENSE. The people who take photos with their books on instagram are known to be voracious readers who graciously take time to review books and recommend them to their followers. Part of their medium is to take elaborate, beautiful photos of books. Die mad, Guardian.
THEY DO READ THEM, YOU JUDGY, RACOON-PICKED TRASH BIN

If you come for Bookstagram, i will fight you.
In appreciation, here are some of my favourite bookstagrams of my books: (photos by lit_nerd37, mybookacademy, bookswrotemystory, and scorpio_books)

Beautifully read: why bookselfies are all over Instagram https://t.co/pBQA3JY0xm
— Guardian Books (@GuardianBooks) October 30, 2018
THEY DO READ THEM, YOU JUDGY, RACOON-PICKED TRASH BIN
If you come for Bookstagram, i will fight you.
In appreciation, here are some of my favourite bookstagrams of my books: (photos by lit_nerd37, mybookacademy, bookswrotemystory, and scorpio_books)







https://t.co/6cRR2B3jBE
Viruses and other pathogens are often studied as stand-alone entities, despite that, in nature, they mostly live in multispecies associations called biofilms—both externally and within the host.
https://t.co/FBfXhUrH5d

Microorganisms in biofilms are enclosed by an extracellular matrix that confers protection and improves survival. Previous studies have shown that viruses can secondarily colonize preexisting biofilms, and viral biofilms have also been described.

...we raise the perspective that CoVs can persistently infect bats due to their association with biofilm structures. This phenomenon potentially provides an optimal environment for nonpathogenic & well-adapted viruses to interact with the host, as well as for viral recombination.

Biofilms can also enhance virion viability in extracellular environments, such as on fomites and in aquatic sediments, allowing viral persistence and dissemination.

Viruses and other pathogens are often studied as stand-alone entities, despite that, in nature, they mostly live in multispecies associations called biofilms—both externally and within the host.
https://t.co/FBfXhUrH5d
Microorganisms in biofilms are enclosed by an extracellular matrix that confers protection and improves survival. Previous studies have shown that viruses can secondarily colonize preexisting biofilms, and viral biofilms have also been described.
...we raise the perspective that CoVs can persistently infect bats due to their association with biofilm structures. This phenomenon potentially provides an optimal environment for nonpathogenic & well-adapted viruses to interact with the host, as well as for viral recombination.
Biofilms can also enhance virion viability in extracellular environments, such as on fomites and in aquatic sediments, allowing viral persistence and dissemination.
