
If you're interested in DB internals, stop what you're doing and watch @CMUDB Quarantine Talk from Nico+Cesar about @SQLServer's Cascades query optimizer: https://t.co/FCdsbHHEaD
Many talks this semester were good. This one is the best. My thread provides key takeaways
Answer: @cosmosdb is using it. @SQLServer is more conservative and using a minor form of it.
More from Internet




🚨 🦮 Seven ways to test for accessibility using only what is already in browser developer tools of Chromium browsers https://t.co/C7kdbigHGE
@MSEdgeDev @EdgeDevTools @ChromiumDev
#tools #accessibility #browsers
Also, a thread: 👇🏼
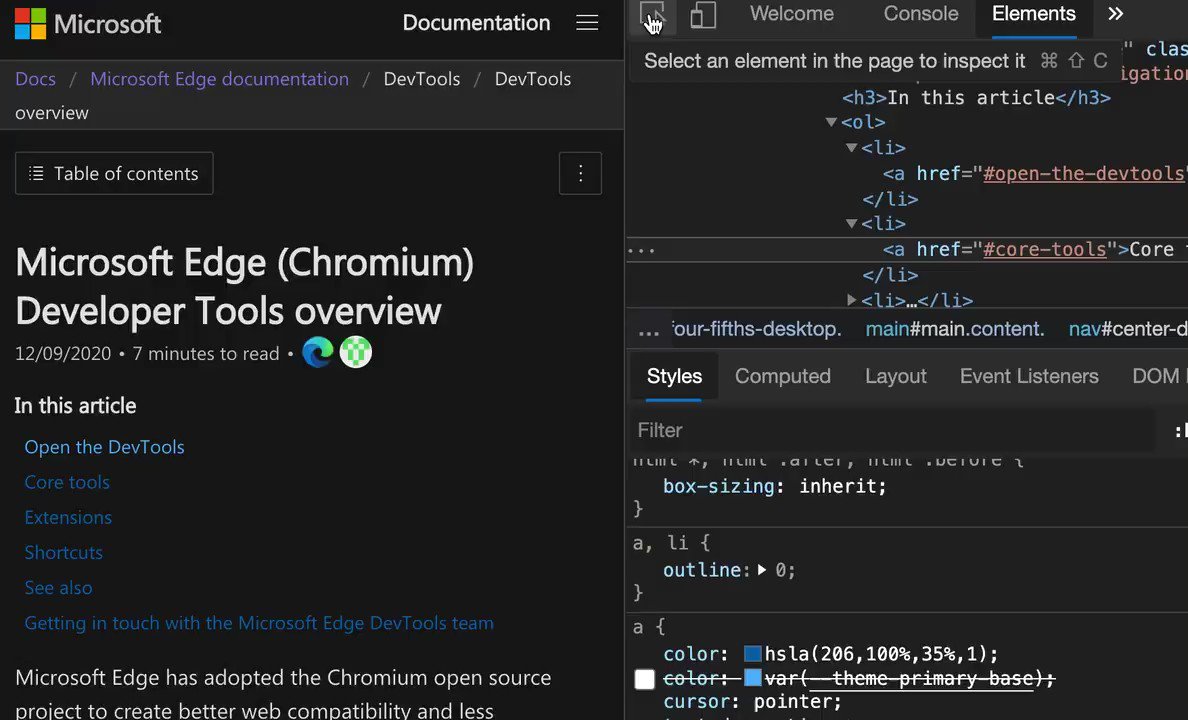
Issues pane, powered by @webhintio, listing accessibility issues with explanations why these are problems, links to more info and direct links to the tools where to fix the problem. https://t.co/4K5RynHhbg
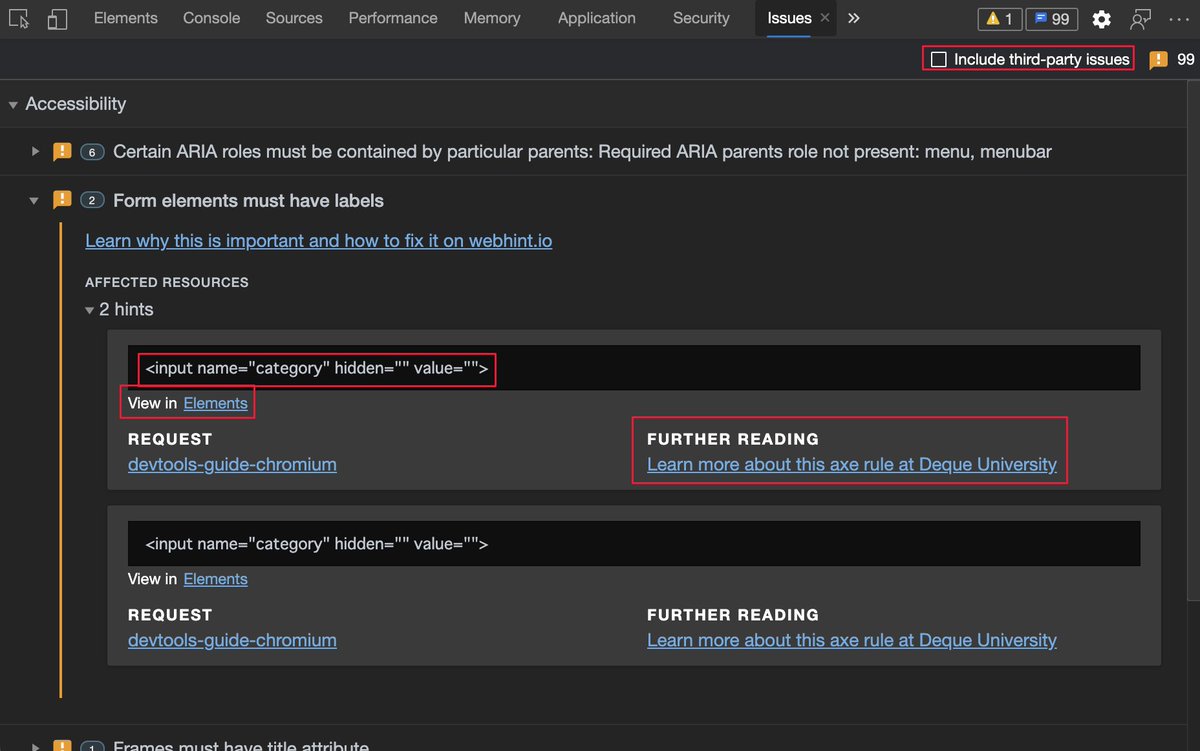
The inspect element overlay showing accessibility relevant information of the element, including contrast information, ARIA name, role and if it can be focused via keyboard.
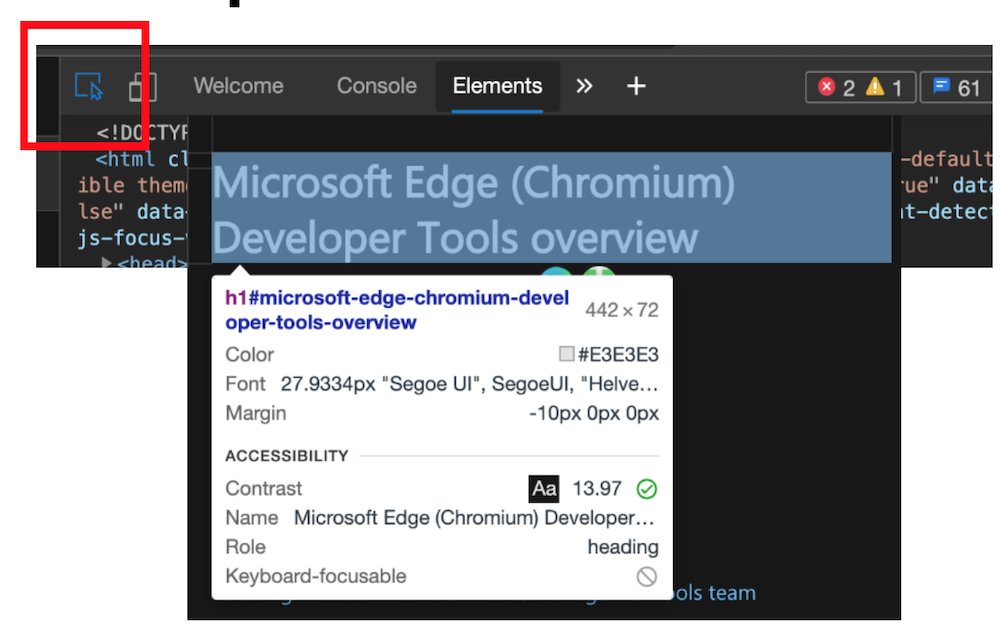
Colour picker with contrast information offering colours that are AA/AAA compliant. You can also see compliant colours indicated by a line on the colour patch.
Note: the current algorithm fails to take font weight into consideration, that's why there will be a new one.

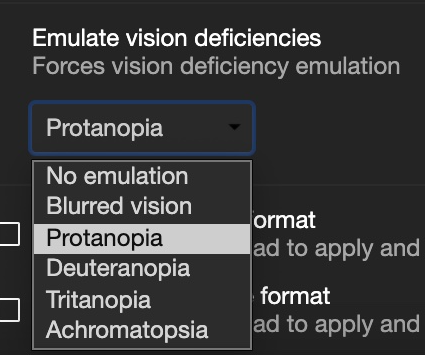
Vision deficit ("colour blindness") emulation. You can see what your product looks like for different visitors.
https://t.co/bxj1vySCAb
@MSEdgeDev @EdgeDevTools @ChromiumDev
#tools #accessibility #browsers
Also, a thread: 👇🏼
Issues pane, powered by @webhintio, listing accessibility issues with explanations why these are problems, links to more info and direct links to the tools where to fix the problem. https://t.co/4K5RynHhbg
The inspect element overlay showing accessibility relevant information of the element, including contrast information, ARIA name, role and if it can be focused via keyboard.
Colour picker with contrast information offering colours that are AA/AAA compliant. You can also see compliant colours indicated by a line on the colour patch.
Note: the current algorithm fails to take font weight into consideration, that's why there will be a new one.
Vision deficit ("colour blindness") emulation. You can see what your product looks like for different visitors.
https://t.co/bxj1vySCAb


You May Also Like





1/x Fort Detrick History
Mr. Patrick, one of the chief scientists at the Army Biological Warfare Laboratories at Fort Detrick in Frederick, Md., held five classified US patents for the process of weaponizing anthrax.
2/x
Under Mr. Patrick’s direction, scientists at Fort Detrick developed a tularemia agent that, if disseminated by airplane, could cause casualties & sickness over 1000s mi². In a 10,000 mi² range, it had 90% casualty rate & 50% fatality rate

3/x His team explored Q fever, plague, & Venezuelan equine encephalitis, testing more than 20 anthrax strains to discern most lethal variety. Fort Detrick scientists used aerosol spray systems inside fountain pens, walking sticks, light bulbs, & even in 1953 Mercury exhaust pipes

4/x After retiring in 1986, Mr. Patrick remained one of the world’s foremost specialists on biological warfare & was a consultant to the CIA, FBI, & US military. He debriefed Soviet defector Ken Alibek, the deputy chief of the Soviet biowarfare program
https://t.co/sHqSaTSqtB

5/x Back in Time
In 1949 the Army created a small team of chemists at "Camp Detrick" called Special Operations Division. Its assignment was to find military uses for toxic bacteria. The coercive use of toxins was a new field, which fascinated Allen Dulles, later head of the CIA

Mr. Patrick, one of the chief scientists at the Army Biological Warfare Laboratories at Fort Detrick in Frederick, Md., held five classified US patents for the process of weaponizing anthrax.
2/x
Under Mr. Patrick’s direction, scientists at Fort Detrick developed a tularemia agent that, if disseminated by airplane, could cause casualties & sickness over 1000s mi². In a 10,000 mi² range, it had 90% casualty rate & 50% fatality rate
3/x His team explored Q fever, plague, & Venezuelan equine encephalitis, testing more than 20 anthrax strains to discern most lethal variety. Fort Detrick scientists used aerosol spray systems inside fountain pens, walking sticks, light bulbs, & even in 1953 Mercury exhaust pipes
4/x After retiring in 1986, Mr. Patrick remained one of the world’s foremost specialists on biological warfare & was a consultant to the CIA, FBI, & US military. He debriefed Soviet defector Ken Alibek, the deputy chief of the Soviet biowarfare program
https://t.co/sHqSaTSqtB
5/x Back in Time
In 1949 the Army created a small team of chemists at "Camp Detrick" called Special Operations Division. Its assignment was to find military uses for toxic bacteria. The coercive use of toxins was a new field, which fascinated Allen Dulles, later head of the CIA





