
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
How can we use language supervision to learn better visual representations for robotics?
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)

Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The secret is *balance* (3/12)
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
Why is the ability to shape this balance important? (5/12)
How do we know?
Because we build an evaluation suite of 5 diverse robotics problem domains! (6/12)
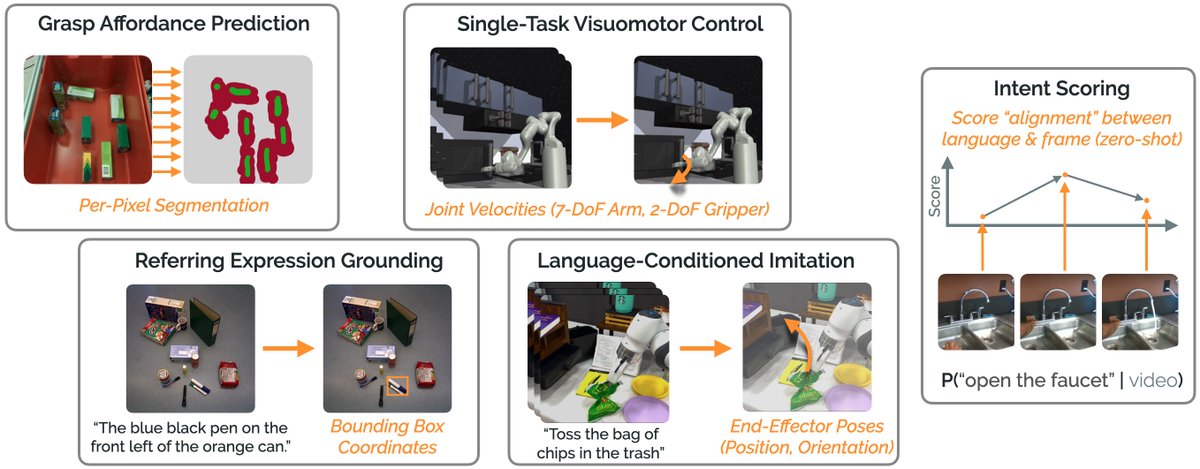
Evaluation: the ARC Grasping dataset (https://t.co/rRI4ya84DL) – CC @andyzengtweets @SongShuran. (7/12)

Modeling *multi-frame* contexts (easy with Voltron) is also high-impact!
Evaluation: Franka Kitchen & Adroit Manipulation domains from R3M – CC @aravindr93 @Vikashplus. (8/12)

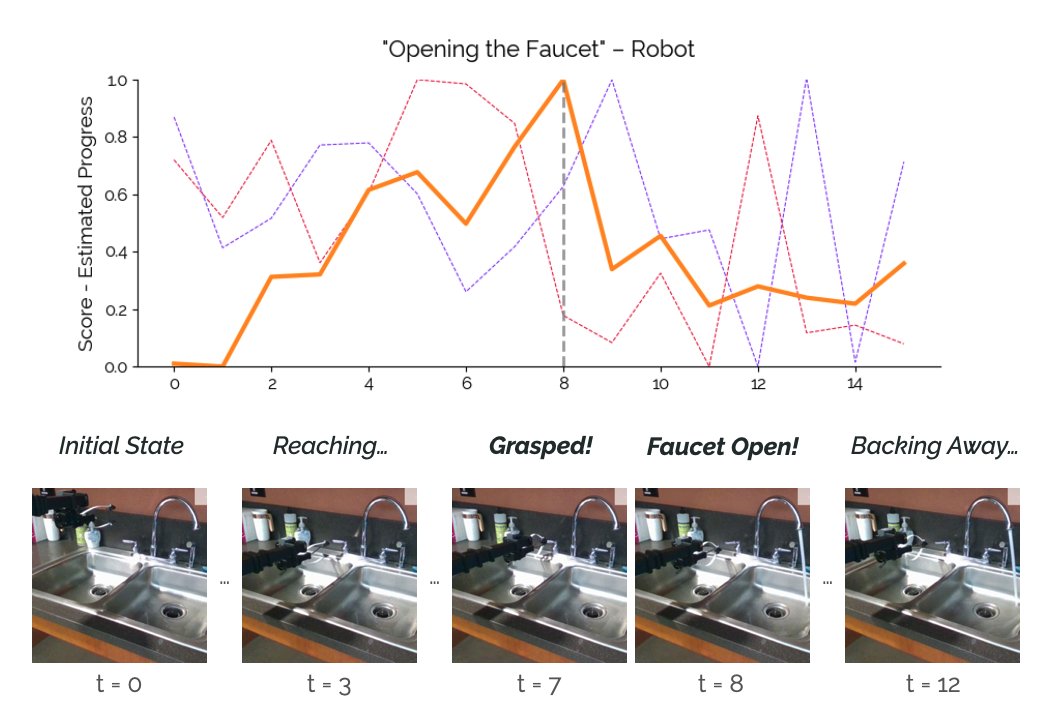
Given a video & language intent, we can score – in real time – how well the behavior in the video captures the intent.
Transfers to *robot data* – no robots during pretraining! (9/12)
Models & Pretraining: https://t.co/NOB3cpATYG
Evaluation Suite: https://t.co/aOzQu95J8z
Use our models: `pip install voltron-robotics` (10/12)

Further thanks to @ToyotaResearch, @stanfordnlp, and the @StanfordAILab ! (11/12)
More from All








1. Mini Thread on Conflicts of Interest involving the authors of the Nature Toilet Paper:
https://t.co/VUYbsKGncx
Kristian G. Andersen
Andrew Rambaut
Ian Lipkin
Edward C. Holmes
Robert F. Garry
2. Thanks to @newboxer007 for forwarding the link to the research by an Australian in Taiwan (not on
3. K.Andersen didn't mention "competing interests"
Only Garry listed Zalgen Labs, which we will look at later.
In acknowledgements, Michael Farzan, Wellcome Trust, NIH, ERC & ARC are mentioned.
Author affiliations listed as usual.
Note the 328 Citations!
https://t.co/nmOeohM89Q

4. Kristian Andersen (1)
Andersen worked with USAMRIID & Fort Detrick scientists on research, with Robert Garry, Jens Kuhn & Sina Bavari among
5. Kristian Andersen (2)
Works at Scripps Research Institute, which WAS in serious financial trouble, haemorrhaging 20 million $ a year.
But just when the first virus cases were emerging, they received great news.
They issued a press release dated November 27, 2019:
https://t.co/VUYbsKGncx
Kristian G. Andersen
Andrew Rambaut
Ian Lipkin
Edward C. Holmes
Robert F. Garry
2. Thanks to @newboxer007 for forwarding the link to the research by an Australian in Taiwan (not on
3. K.Andersen didn't mention "competing interests"
Only Garry listed Zalgen Labs, which we will look at later.
In acknowledgements, Michael Farzan, Wellcome Trust, NIH, ERC & ARC are mentioned.
Author affiliations listed as usual.
Note the 328 Citations!
https://t.co/nmOeohM89Q
4. Kristian Andersen (1)
Andersen worked with USAMRIID & Fort Detrick scientists on research, with Robert Garry, Jens Kuhn & Sina Bavari among
Our Hans Kristian Andersen working with Jens H. Kuhn, Sina Bavari, Robert F. Garry, Stuart T. Nichol,Gustavo Palacios, Sheli R. Radoshitzky from USAMRIID and Fort Detrick to tell more fairy tales? Full emails listed for queries...https://t.co/kLRoQTxiGD pic.twitter.com/uHNuGraPP2
— Billy Bostickson \U0001f3f4\U0001f441&\U0001f441 \U0001f193 (@BillyBostickson) August 26, 2020
5. Kristian Andersen (2)
Works at Scripps Research Institute, which WAS in serious financial trouble, haemorrhaging 20 million $ a year.
But just when the first virus cases were emerging, they received great news.
They issued a press release dated November 27, 2019:

You May Also Like

Took me 5 years to get the best Chartink scanners for Stock Market, but you’ll get it in 5 mminutes here ⏰
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times











1/ 👋 Excited to share what we’ve been building at https://t.co/GOQJ7LjQ2t + we are going to tweetstorm our progress every week!
Week 1 highlights: getting shortlisted for YC W2019🤞, acquiring a premium domain💰, meeting Substack's @hamishmckenzie and Stripe CEO @patrickc 🤩
2/ So what is Brew?
brew / bru : / to make (beer, coffee etc.) / verb: begin to develop 🌱
A place for you to enjoy premium content while supporting your favorite creators. Sort of like a ‘Consumer-facing Patreon’ cc @jackconte
(we’re still working on the pitch)
3/ So, why be so transparent? Two words: launch strategy.
jk 😅 a) I loooove doing something consistently for a long period of time b) limited downside and infinite upside (feedback, accountability, reach).
cc @altimor, @pmarca

4/ https://t.co/GOQJ7LjQ2t domain 🍻
It started with a cold email. Guess what? He was using BuyMeACoffee on his blog, and was excited to hear about what we're building next. Within 2w, we signed the deal at @Escrowcom's SF office. You’re a pleasure to work with @MichaelCyger!
5/ @ycombinator's invite for the in-person interview arrived that evening. Quite a day!
Thanks @patio11 for the thoughtful feedback on our YC application, and @gabhubert for your directions on positioning the product — set the tone for our pitch!

Week 1 highlights: getting shortlisted for YC W2019🤞, acquiring a premium domain💰, meeting Substack's @hamishmckenzie and Stripe CEO @patrickc 🤩
2/ So what is Brew?
brew / bru : / to make (beer, coffee etc.) / verb: begin to develop 🌱
A place for you to enjoy premium content while supporting your favorite creators. Sort of like a ‘Consumer-facing Patreon’ cc @jackconte
(we’re still working on the pitch)
3/ So, why be so transparent? Two words: launch strategy.
jk 😅 a) I loooove doing something consistently for a long period of time b) limited downside and infinite upside (feedback, accountability, reach).
cc @altimor, @pmarca
4/ https://t.co/GOQJ7LjQ2t domain 🍻
It started with a cold email. Guess what? He was using BuyMeACoffee on his blog, and was excited to hear about what we're building next. Within 2w, we signed the deal at @Escrowcom's SF office. You’re a pleasure to work with @MichaelCyger!
5/ @ycombinator's invite for the in-person interview arrived that evening. Quite a day!
Thanks @patio11 for the thoughtful feedback on our YC application, and @gabhubert for your directions on positioning the product — set the tone for our pitch!