
Learn for Free.
1. HTML ➩ https://t.co/jzoRx6AZil
2. CSS ➩ https://t.co/MCQl9wASvZ
3. Git ➩ https://t.co/80tP825Er5
5. JavaScript ➩ https://t.co/rrDhUN6xYN
6. React ➩ https://t.co/yHTPKtePur
7. Interview ➩ https://t.co/4F2nkAZEkL
Crack a Job.
More from All










ChatGPT is a phenomenal AI Tool.
But don't limit yourself to just ChatGPT.
Here're 8 AI-powered tools you should try in 2023:
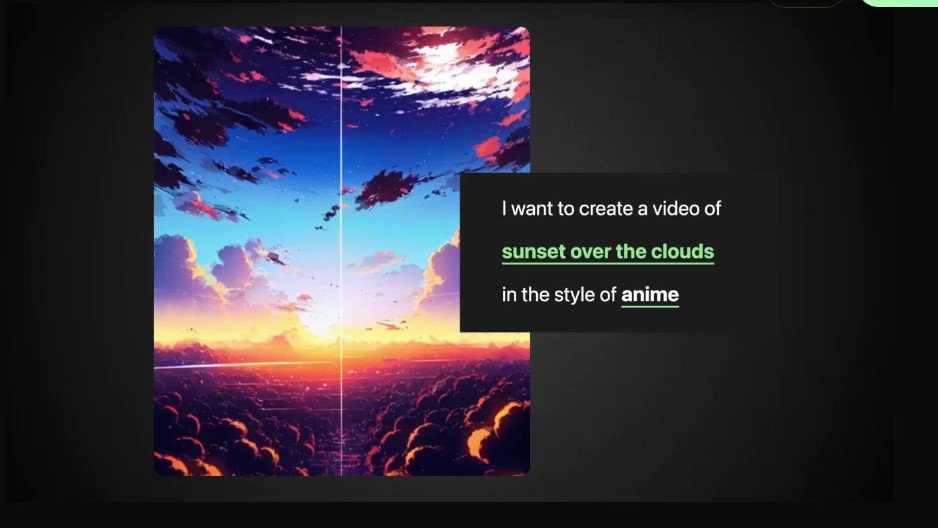
1. KaiberAI
@KaiberAI helps you generate beautiful videos in minutes.
Transform your ideas into the visual stories of your dreams with this Amazing Tool.
New features:
1. Upload your custom music
2. Prompt Templates
3. Camera Movements:
Check here
https://t.co/ivnDRf628L
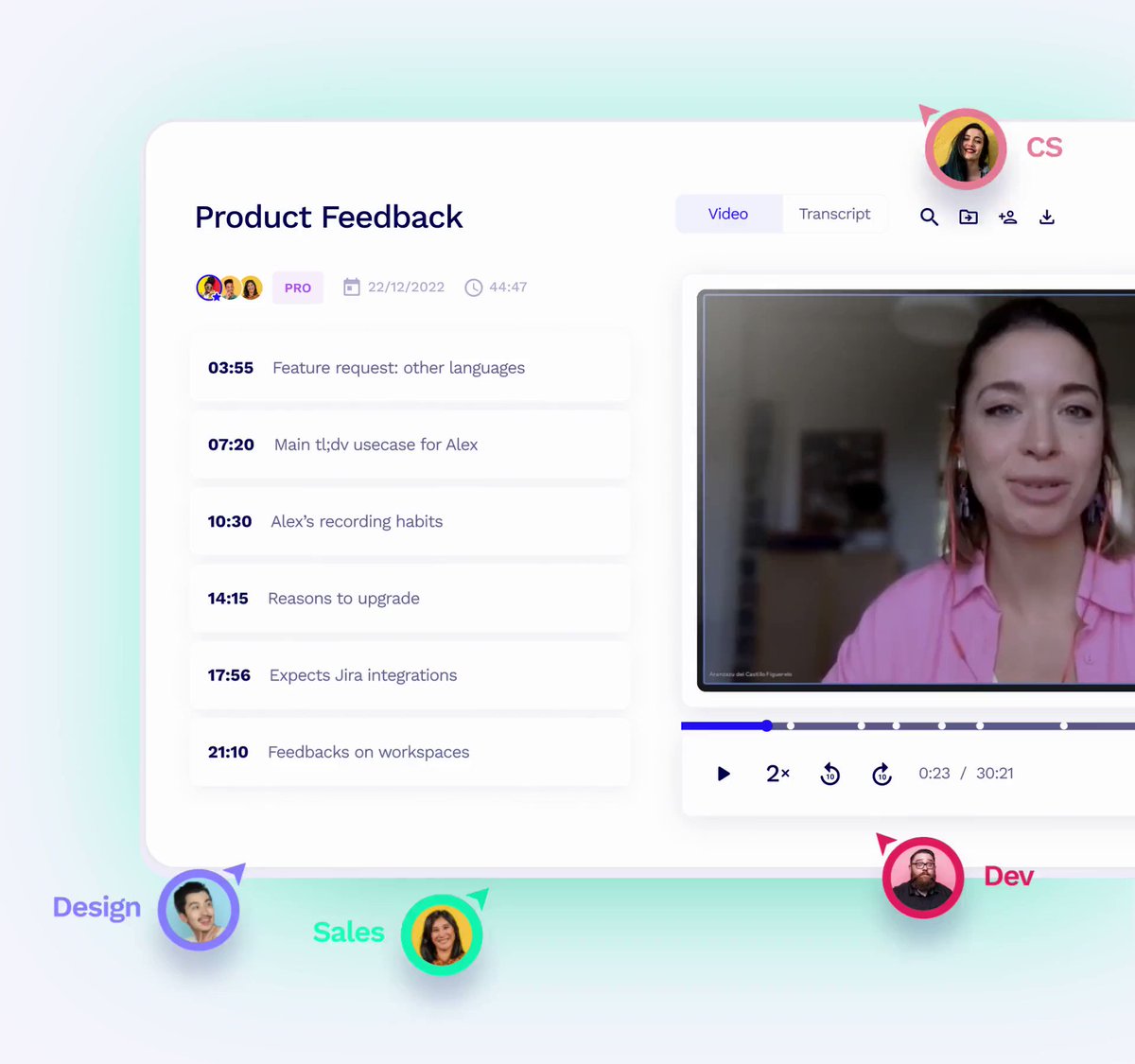
2. @tldview TLDV
Best ChatGPT Alternative for meetings.
Make your meetings 10X more productive with this amazing tool.
Try it now:
https://t.co/vOy3sS4QfJ
3. ComposeAI
Use ComposeAI for generating any text using AI.
It’s will help you write better content in seconds.
Try it here:
https://t.co/ksj5aop5ZI
4. Browser AI
Use this AI tool to extract and monitor data from any website.
Train a robot in 2 minutes to do your work.
No coding required.
https://t.co/nNiawtUMyO
But don't limit yourself to just ChatGPT.
Here're 8 AI-powered tools you should try in 2023:
1. KaiberAI
@KaiberAI helps you generate beautiful videos in minutes.
Transform your ideas into the visual stories of your dreams with this Amazing Tool.
New features:
1. Upload your custom music
2. Prompt Templates
3. Camera Movements:
Check here
https://t.co/ivnDRf628L
2. @tldview TLDV
Best ChatGPT Alternative for meetings.
Make your meetings 10X more productive with this amazing tool.
Try it now:
https://t.co/vOy3sS4QfJ
3. ComposeAI
Use ComposeAI for generating any text using AI.
It’s will help you write better content in seconds.
Try it here:
https://t.co/ksj5aop5ZI
4. Browser AI
Use this AI tool to extract and monitor data from any website.
Train a robot in 2 minutes to do your work.
No coding required.
https://t.co/nNiawtUMyO















