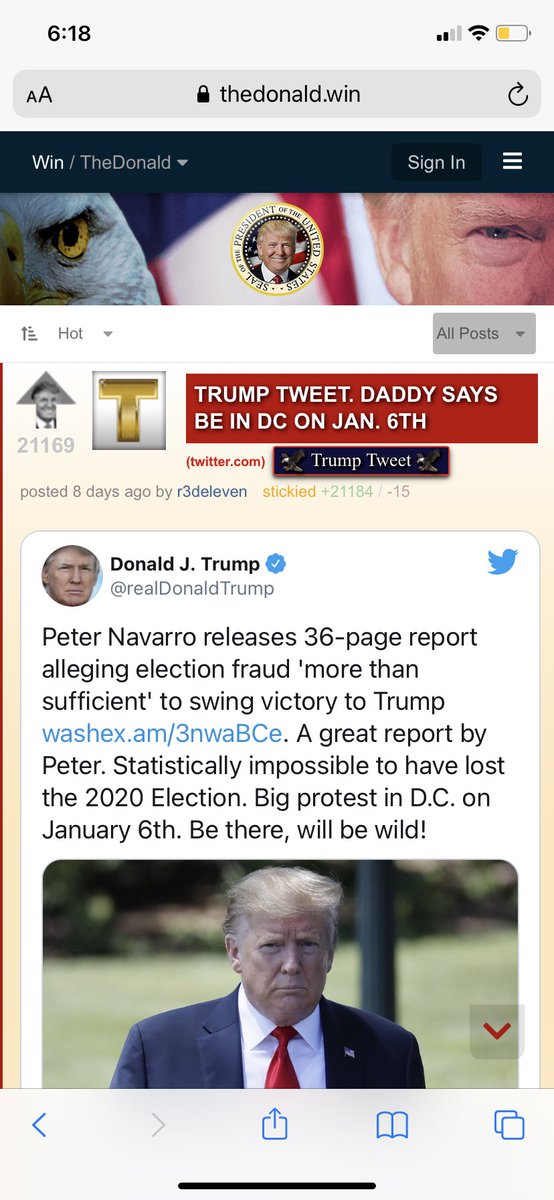
Okay, here we go.
Neural Volume Rendering for Dynamic Scenes
NeRF has shown incredible view synthesis results, but it requires multi-view captures for STATIC scenes.
How can we achieve view synthesis for DYNAMIC scenes from a single video? Here is what I learned from several recent efforts.
Okay, here we go.
NeRF represents the scene as a 5D continuous volumetric scene function that maps the spatial position and viewing direction to color and density. It then projects the colors/densities to form an image with volume rendering.
Volumetric + Implicit -> Awesome!
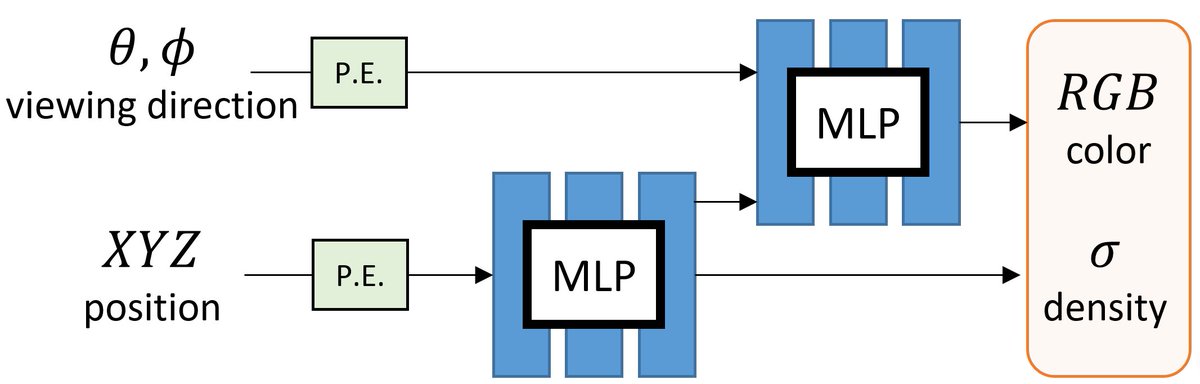
Building on NeRF, one can extend it for handling dynamic scenes with two types of approaches.
A) 4D (or 6D with views) function.
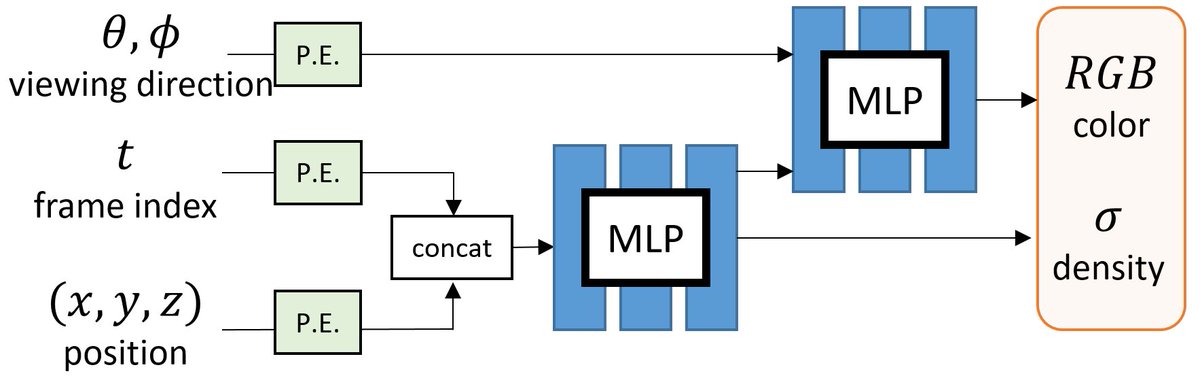
One direct approach is to include TIME as an additional input to learn a DYNAMIC radiance field.
e.g., Video-NeRF, NSFF, NeRFlow
Inspired by non-rigid reconstruction methods, this type of approach learns a radiance field in a canonical frame (template) and predicts deformation for each frame to account for dynamics over time.
e.g., Nerfie, NR-NeRF, D-NeRF
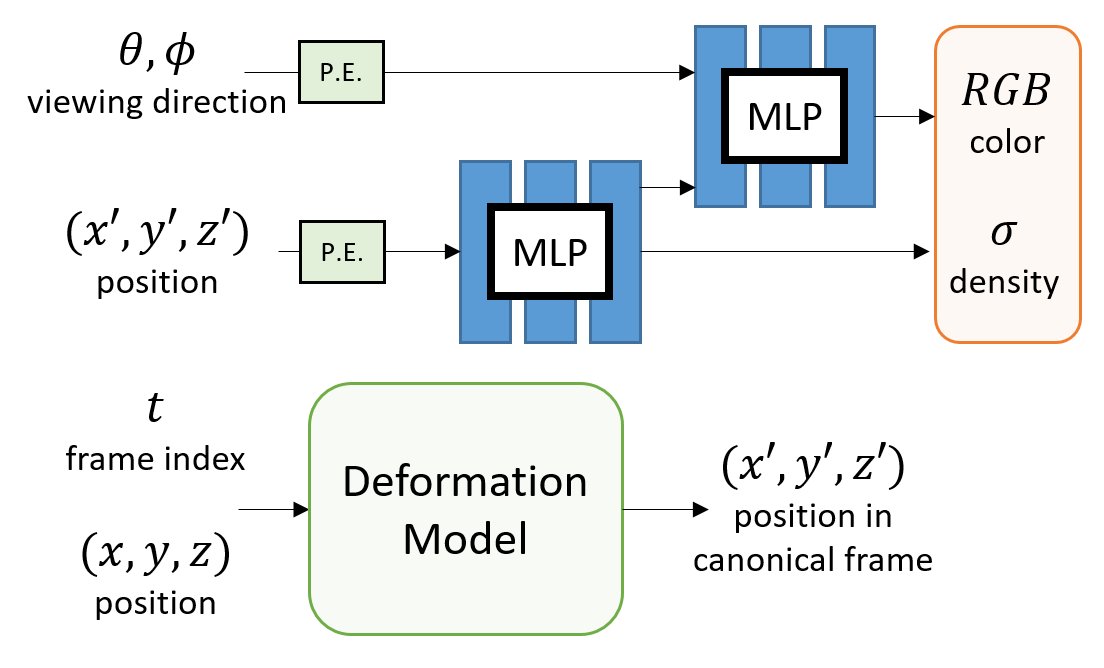
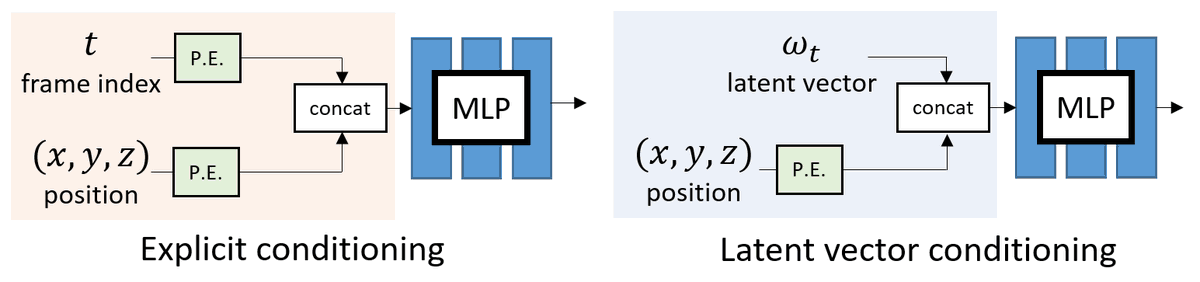
All the methods use an MLP to encode the deformation field. But, how do they differ?
A) INPUT: How to encode the additional time dimension as input?
B) OUTPUT: How to parametrize the deformation field?
One can choose to use EXPLICIT conditioning by treating the frame index t as input.
Alternatively, one can use a learnable LATENT vector for each frame.
We can either use the MLP to predict
- dense 3D translation vectors (aka scene flow) or
- dense rigid motion field
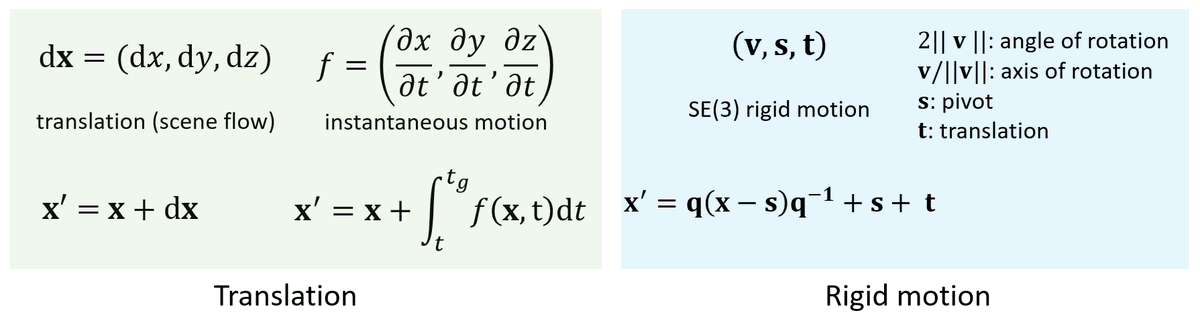

More from Tech


A common misunderstanding about Agile and “Big Design Up Front”:
There’s nothing in the Agile Manifesto or Principles that states you should never have any idea what you’re trying to build.
You’re allowed to think about a desired outcome from the beginning.
It’s not Big Design Up Front if you do in-depth research to understand the user’s problem.
It’s not BDUF if you spend detailed time learning who needs this thing and why they need it.
It’s not BDUF if you help every team member know what success looks like.
Agile is about reducing risk.
It’s not Agile if you increase risk by starting your sprints with complete ignorance.
It’s not Agile if you don’t research.
Don’t make the mistake of shutting down critical understanding by labeling it Bg Design Up Front.
It would be a mistake to assume this research should only be done by designers and researchers.
Product management and developers also need to be out with the team, conducting the research.
Shared Understanding is the key objective
Big Design Up Front is a thing to avoid.
Defining all the functionality before coding is BDUF.
Drawing every screen and every pixel is BDUF.
Promising functionality (or delivery dates) to customers before development starts is BDUF.
These things shouldn’t happen in Agile.
There’s nothing in the Agile Manifesto or Principles that states you should never have any idea what you’re trying to build.
You’re allowed to think about a desired outcome from the beginning.
It’s not Big Design Up Front if you do in-depth research to understand the user’s problem.
It’s not BDUF if you spend detailed time learning who needs this thing and why they need it.
It’s not BDUF if you help every team member know what success looks like.
Agile is about reducing risk.
It’s not Agile if you increase risk by starting your sprints with complete ignorance.
It’s not Agile if you don’t research.
Don’t make the mistake of shutting down critical understanding by labeling it Bg Design Up Front.
It would be a mistake to assume this research should only be done by designers and researchers.
Product management and developers also need to be out with the team, conducting the research.
Shared Understanding is the key objective
I\u2019d recommend that the devs participate directly in the research.
— Jared Spool (@jmspool) November 18, 2018
If the devs go into the first sprint with a thorough understanding of the user\u2019s problems, they are far more likely to solve it well.
Big Design Up Front is a thing to avoid.
Defining all the functionality before coding is BDUF.
Drawing every screen and every pixel is BDUF.
Promising functionality (or delivery dates) to customers before development starts is BDUF.
These things shouldn’t happen in Agile.