
They sure will. Here's a quick analysis of how, from my perspective as someone who studies societal impacts of natural language technology:
I have no idea how, but these will end up being racist https://t.co/pjZN0WXnnE
— Michael Hobbes (@RottenInDenmark) December 16, 2020
More from Tech









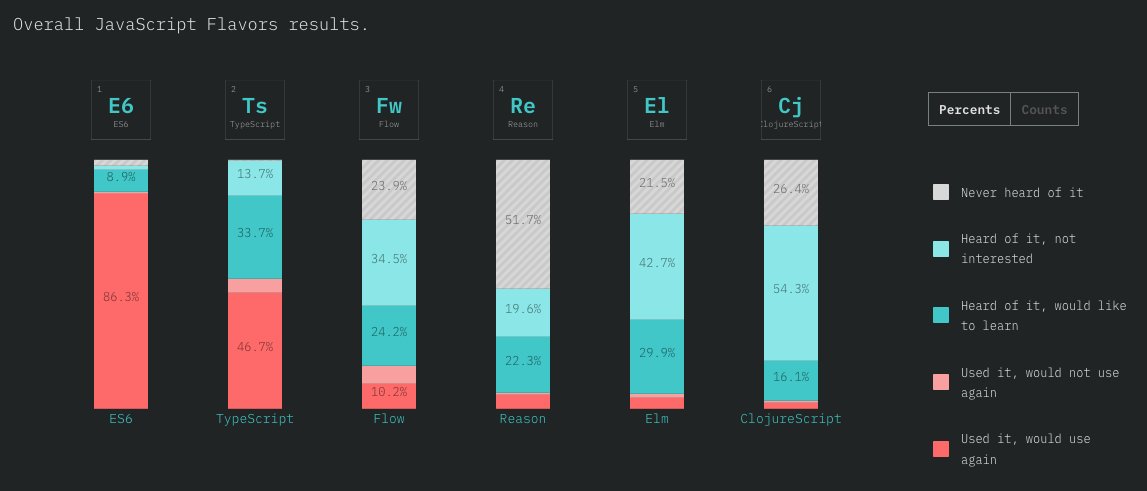
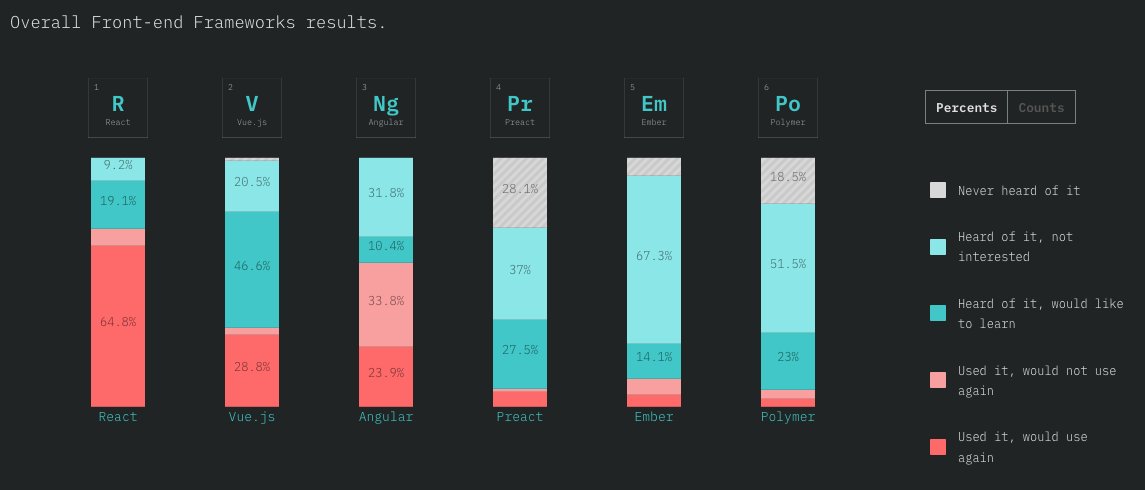
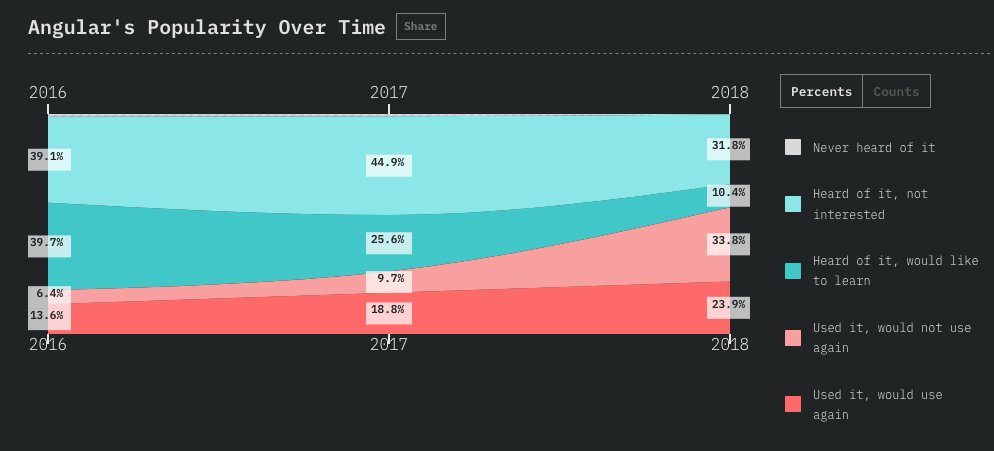



THREAD: How is it possible to train a well-performing, advanced Computer Vision model 𝗼𝗻 𝘁𝗵𝗲 𝗖𝗣𝗨? 🤔
At the heart of this lies the most important technique in modern deep learning - transfer learning.
Let's analyze how it
2/ For starters, let's look at what a neural network (NN for short) does.
An NN is like a stack of pancakes, with computation flowing up when we make predictions.
How does it all work?
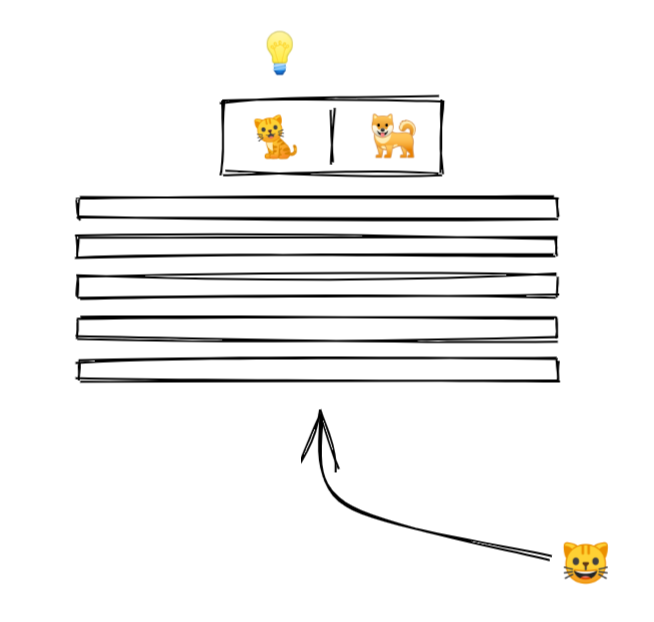
3/ We show an image to our model.
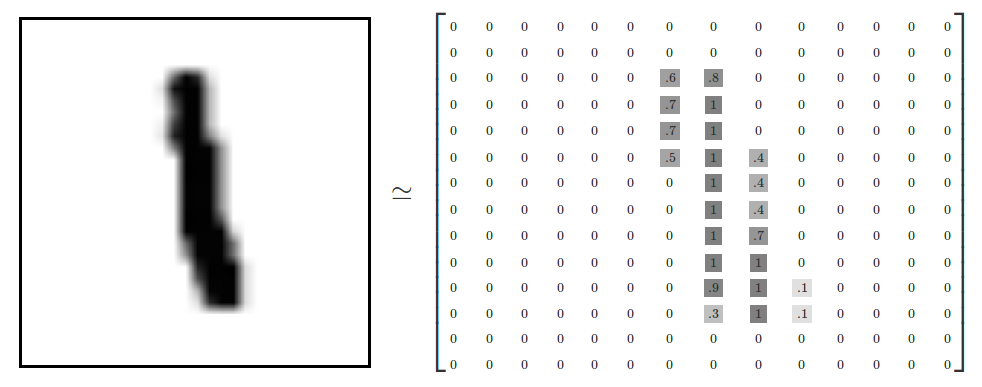
An image is a collection of pixels. Each pixel is just a bunch of numbers describing its color.
Here is what it might look like for a black and white image
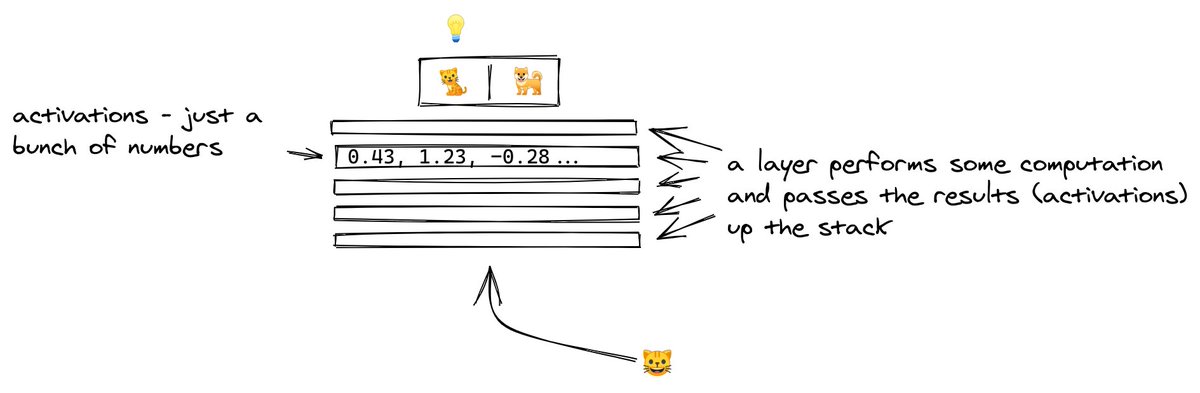
4/ The picture goes into the layer at the bottom.
Each layer performs computation on the image, transforming it and passing it upwards.
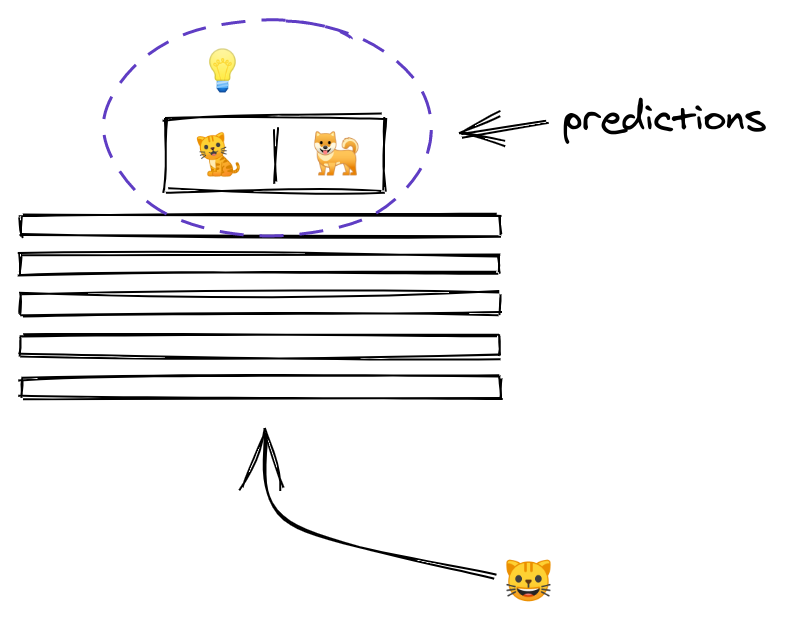
5/ By the time the image reaches the uppermost layer, it has been transformed to the point that it now consists of two numbers only.
The outputs of a layer are called activations, and the outputs of the last layer have a special meaning... they are the predictions!
At the heart of this lies the most important technique in modern deep learning - transfer learning.
Let's analyze how it
THREAD: Can you start learning cutting-edge deep learning without specialized hardware? \U0001f916
— Radek Osmulski (@radekosmulski) February 11, 2021
In this thread, we will train an advanced Computer Vision model on a challenging dataset. \U0001f415\U0001f408 Training completes in 25 minutes on my 3yrs old Ryzen 5 CPU.
Let me show you how...
2/ For starters, let's look at what a neural network (NN for short) does.
An NN is like a stack of pancakes, with computation flowing up when we make predictions.
How does it all work?
3/ We show an image to our model.
An image is a collection of pixels. Each pixel is just a bunch of numbers describing its color.
Here is what it might look like for a black and white image
4/ The picture goes into the layer at the bottom.
Each layer performs computation on the image, transforming it and passing it upwards.
5/ By the time the image reaches the uppermost layer, it has been transformed to the point that it now consists of two numbers only.
The outputs of a layer are called activations, and the outputs of the last layer have a special meaning... they are the predictions!








