
We just launched a fun little tool called Phantom Analyzer. It’s a 100% serverless tool that scans websites for hidden tracking pixels.
I want to talk about how we built it 👇
> Laravel Vapor
> ChipperCI for deployment
> SQS for queues
> DynamoDB for the database
We went with DynamoDB as we don’t want to worry about our database scaling!
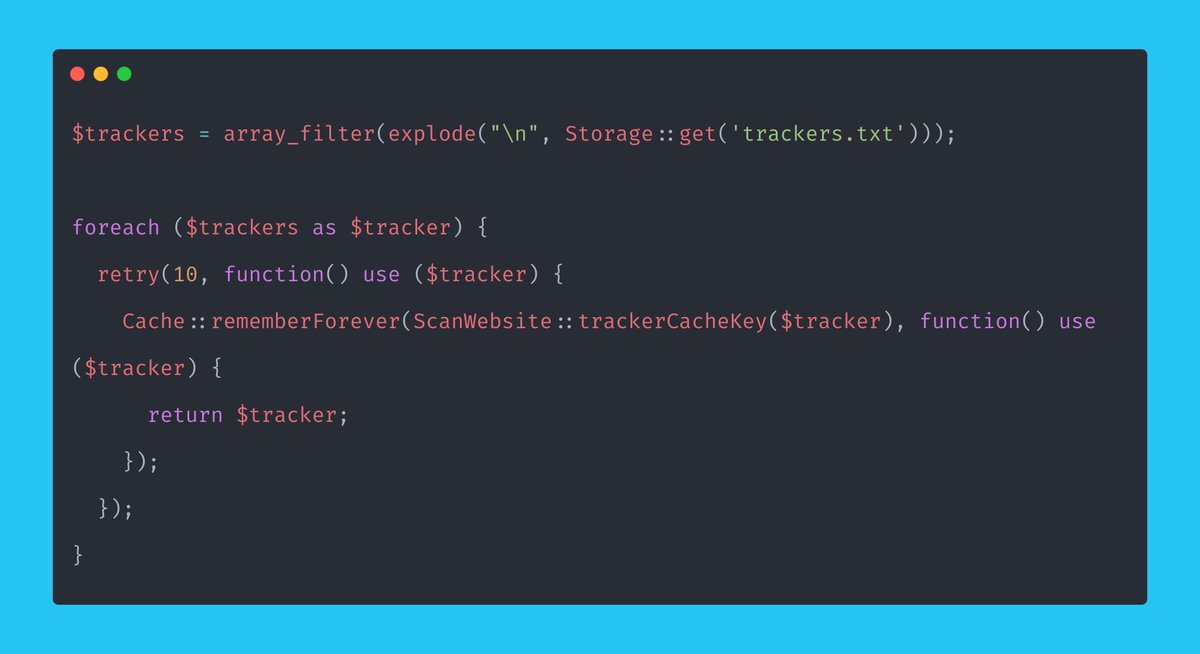
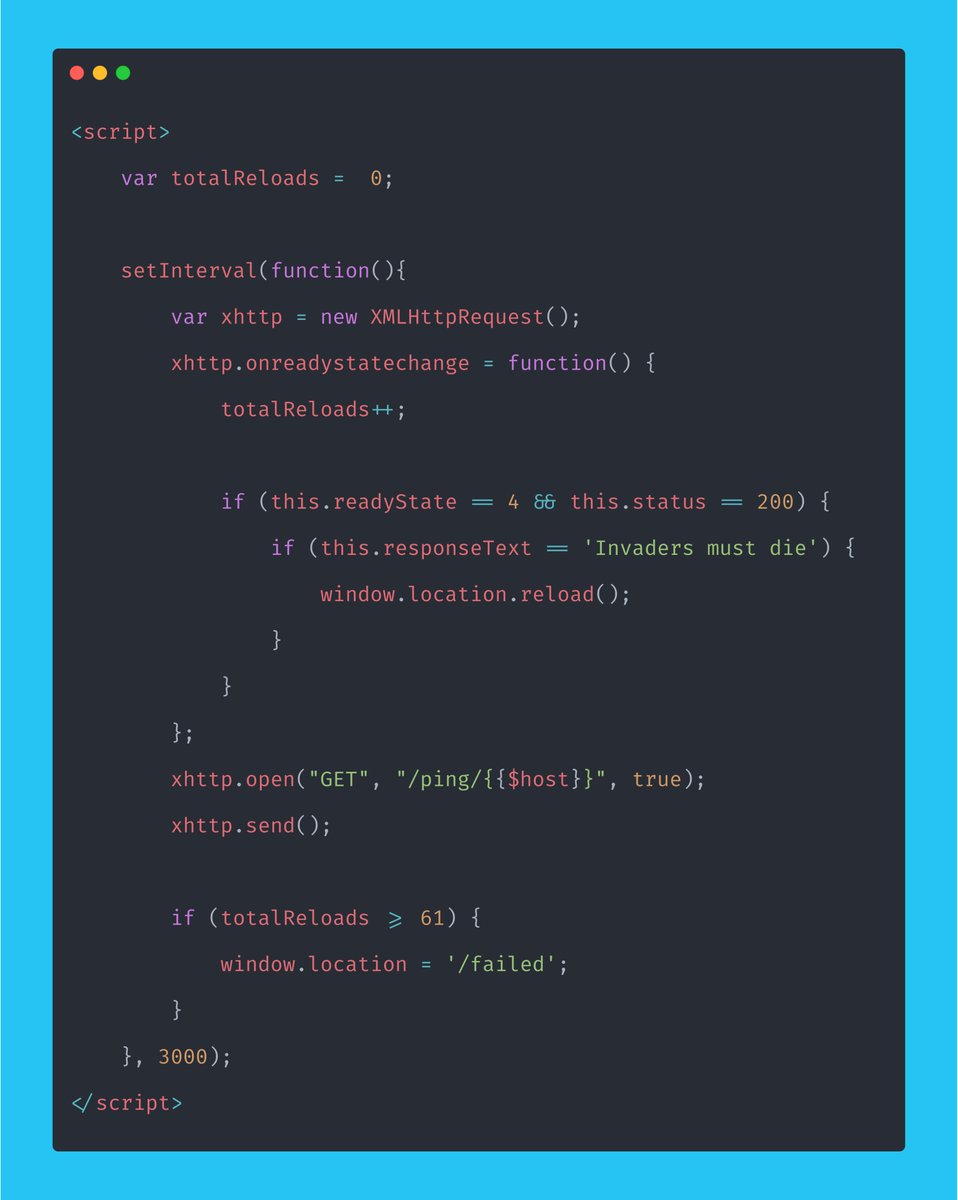
> How will we scan websites for tracking pixels?
> How will we utilize the queue and check the job is done?
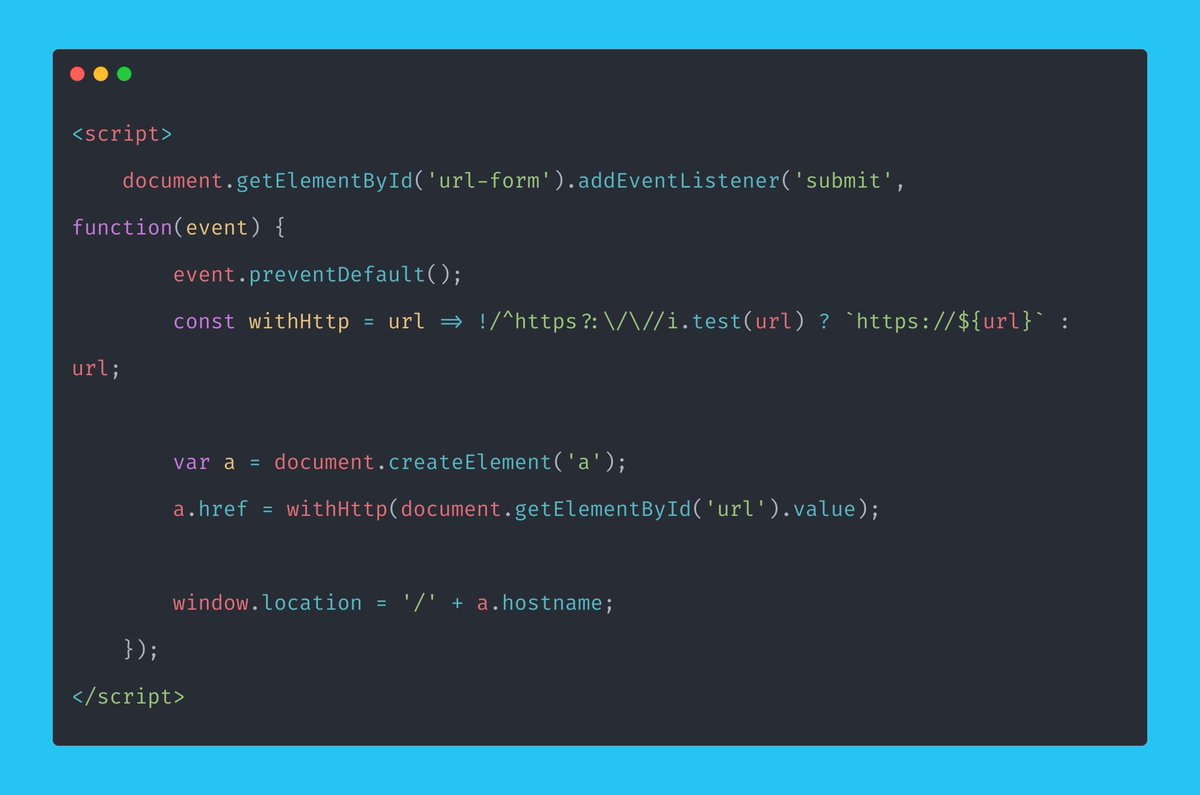
> How will we validate the URL?
Wait a minute...
Yes, out of the box, Browsershot already had what I needed. Are you kidding me?


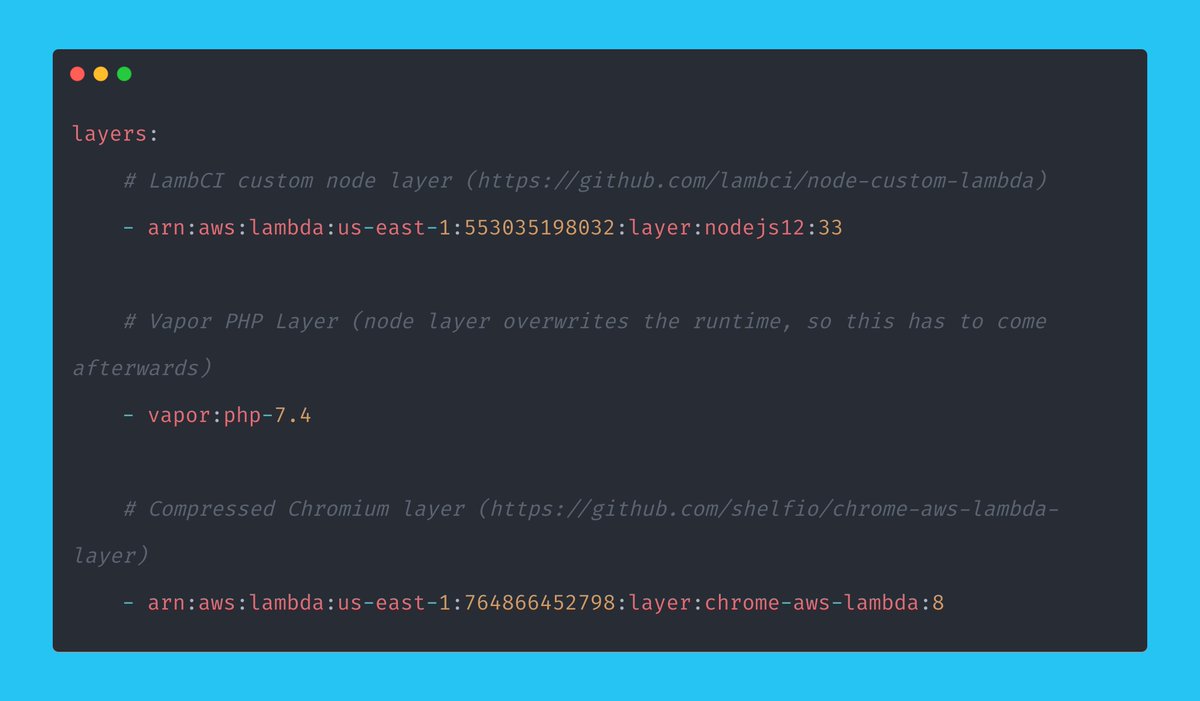
> 1024MB of RAM
> 2048 of RAM for the queue (could likely reduce!)
> Warm of 500
> CLI Timeout of 180 seconds
Those settings all worked nicely.
More from Tech
















The 12 most important pieces of information and concepts I wish I knew about equity, as a software engineer.
A thread.
1. Equity is something Big Tech and high-growth companies award to software engineers at all levels. The more senior you are, the bigger the ratio can be:

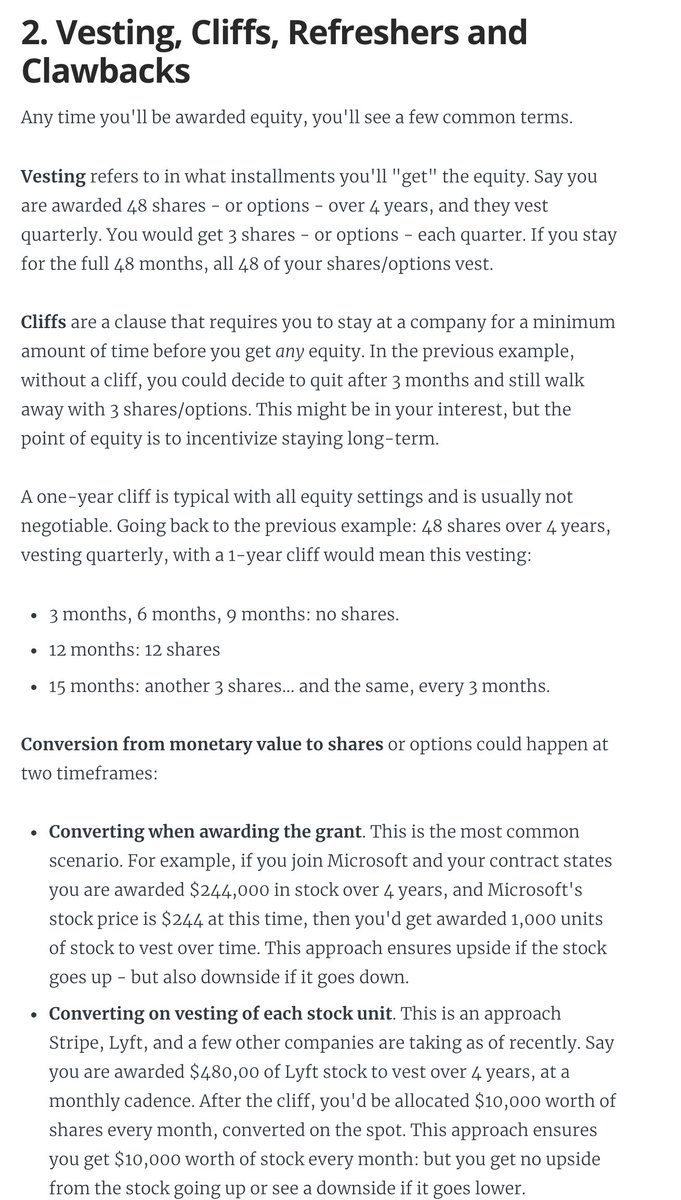
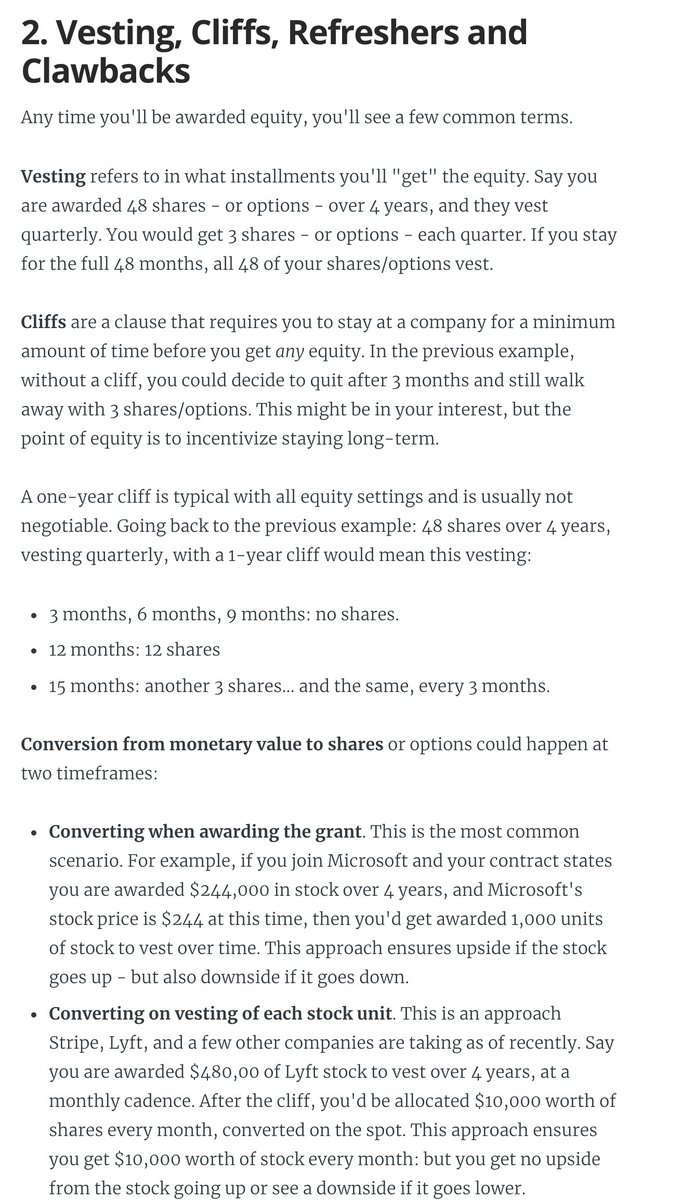
2. Vesting, cliffs, refreshers, and sign-on clawbacks.
If you get awarded equity, you'll want to understand vesting and cliffs. A 1-year cliff is pretty common in most places that award equity.
Read more in this blog post I wrote: https://t.co/WxQ9pQh2mY
3. Stock options / ESOPs.
The most common form of equity compensation at early-stage startups that are high-growth.
And there are *so* many pitfalls you'll want to be aware of. You need to do your research on this: I can't do justice in a tweet.
https://t.co/cudLn3ngqi
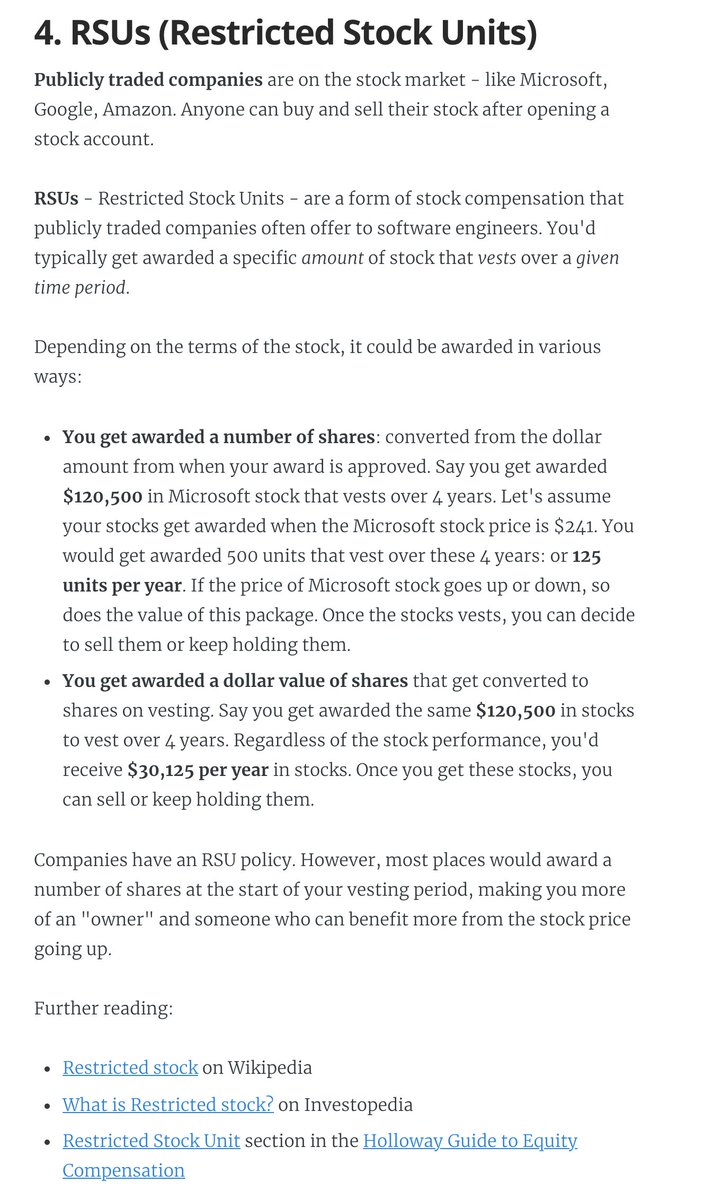
4. RSUs (Restricted Stock Units)
A common form of equity compensation for publicly traded companies and Big Tech. One of the easier types of equity to understand: https://t.co/a5xU1H9IHP
5. Double-trigger RSUs. Typically RSUs for pre-IPO companies. I got these at Uber.
6. ESPP: a (typically) amazing employee perk at publicly traded companies. There's always risk, but this plan can typically offer good upsides.
7. Phantom shares. An interesting setup similar to RSUs... but you don't own stocks. Not frequent, but e.g. Adyen goes with this plan.

A thread.
1. Equity is something Big Tech and high-growth companies award to software engineers at all levels. The more senior you are, the bigger the ratio can be:
2. Vesting, cliffs, refreshers, and sign-on clawbacks.
If you get awarded equity, you'll want to understand vesting and cliffs. A 1-year cliff is pretty common in most places that award equity.
Read more in this blog post I wrote: https://t.co/WxQ9pQh2mY
3. Stock options / ESOPs.
The most common form of equity compensation at early-stage startups that are high-growth.
And there are *so* many pitfalls you'll want to be aware of. You need to do your research on this: I can't do justice in a tweet.
https://t.co/cudLn3ngqi
4. RSUs (Restricted Stock Units)
A common form of equity compensation for publicly traded companies and Big Tech. One of the easier types of equity to understand: https://t.co/a5xU1H9IHP
5. Double-trigger RSUs. Typically RSUs for pre-IPO companies. I got these at Uber.
6. ESPP: a (typically) amazing employee perk at publicly traded companies. There's always risk, but this plan can typically offer good upsides.
7. Phantom shares. An interesting setup similar to RSUs... but you don't own stocks. Not frequent, but e.g. Adyen goes with this plan.
You May Also Like






IMPORTANCE, ADVANTAGES AND CHARACTERISTICS OF BHAGWAT PURAN
It was Ved Vyas who edited the eighteen thousand shlokas of Bhagwat. This book destroys all your sins. It has twelve parts which are like kalpvraksh.
In the first skandh, the importance of Vedvyas

and characters of Pandavas are described by the dialogues between Suutji and Shaunakji. Then there is the story of Parikshit.
Next there is a Brahm Narad dialogue describing the avtaar of Bhagwan. Then the characteristics of Puraan are mentioned.
It also discusses the evolution of universe.( https://t.co/2aK1AZSC79 )
Next is the portrayal of Vidur and his dialogue with Maitreyji. Then there is a mention of Creation of universe by Brahma and the preachings of Sankhya by Kapil Muni.
In the next section we find the portrayal of Sati, Dhruv, Pruthu, and the story of ancient King, Bahirshi.
In the next section we find the character of King Priyavrat and his sons, different types of loks in this universe, and description of Narak. ( https://t.co/gmDTkLktKS )
In the sixth part we find the portrayal of Ajaamil ( https://t.co/LdVSSNspa2 ), Daksh and the birth of Marudgans( https://t.co/tecNidVckj )
In the seventh section we find the story of Prahlad and the description of Varnashram dharma. This section is based on karma vaasna.
It was Ved Vyas who edited the eighteen thousand shlokas of Bhagwat. This book destroys all your sins. It has twelve parts which are like kalpvraksh.
In the first skandh, the importance of Vedvyas
and characters of Pandavas are described by the dialogues between Suutji and Shaunakji. Then there is the story of Parikshit.
Next there is a Brahm Narad dialogue describing the avtaar of Bhagwan. Then the characteristics of Puraan are mentioned.
It also discusses the evolution of universe.( https://t.co/2aK1AZSC79 )
Next is the portrayal of Vidur and his dialogue with Maitreyji. Then there is a mention of Creation of universe by Brahma and the preachings of Sankhya by Kapil Muni.
HOW LIFE EVOLVED IN THIS UNIVERSE AS PER OUR SCRIPTURES.
— Anshul Pandey (@Anshulspiritual) August 29, 2020
Well maximum of Living being are the Vansaj of Rishi Kashyap. I have tried to give stories from different-different Puran. So lets start.... pic.twitter.com/MrrTS4xORk
In the next section we find the portrayal of Sati, Dhruv, Pruthu, and the story of ancient King, Bahirshi.
In the next section we find the character of King Priyavrat and his sons, different types of loks in this universe, and description of Narak. ( https://t.co/gmDTkLktKS )
Thread on NARK(HELL) / \u0928\u0930\u094d\u0915
— Anshul Pandey (@Anshulspiritual) August 11, 2020
Well today i will take you to a journey where nobody wants to go i.e Nark. Hence beware of doing Adharma/Evil things. There are various mentions in Puranas about Nark, But my Thread is only as per Bhagwat puran(SS attached in below Thread)
1/8 pic.twitter.com/raHYWtB53Q
In the sixth part we find the portrayal of Ajaamil ( https://t.co/LdVSSNspa2 ), Daksh and the birth of Marudgans( https://t.co/tecNidVckj )
In the seventh section we find the story of Prahlad and the description of Varnashram dharma. This section is based on karma vaasna.
#THREAD
— Anshul Pandey (@Anshulspiritual) August 12, 2020
WHY PARENTS CHOOSE RELIGIOUS OR PARAMATMA'S NAMES FOR THEIR CHILDREN AND WHICH ARE THE EASIEST WAY TO WASH AWAY YOUR SINS.
Yesterday I had described the types of Naraka's and the Sin or Adharma for a person to be there.
1/8 pic.twitter.com/XjPB2hfnUC



Recently, the @CNIL issued a decision regarding the GDPR compliance of an unknown French adtech company named "Vectaury". It may seem like small fry, but the decision has potential wide-ranging impacts for Google, the IAB framework, and today's adtech. It's thread time! 👇
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.