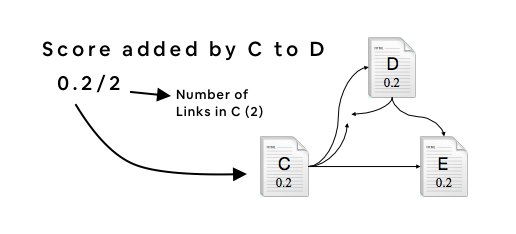
If you're interested in DB internals, stop what you're doing and watch @CMUDB Quarantine Talk from Nico+Cesar about @SQLServer's Cascades query optimizer: https://t.co/FCdsbHHEaD
Many talks this semester were good. This one is the best. My thread provides key takeaways
Answer: @cosmosdb is using it. @SQLServer is more conservative and using a minor form of it.
More from Internet











We’ve spent the last ten months building #CitizenBrowser, a project that aims to peek inside the Black Box of social media algorithms, by building a nationwide panel to share data with us. Today, we are publishing our first story from the project. /1
.@corintxt crunched the numbers and found that after Facebook flipped the switch for political ads, partisan content elbowed out reputable news outlets in our panelists’ news feeds. https://t.co/Z0kibSBeQZ /2
You can learn more in our methodology, where we describe how we did this and what steps we took to ensure that we preserved the panelists' privacy. https://t.co/UYbTXAjy5i /3
Personally, this project is the culmination of years of experiments trying to figure out how to collect data from social media platforms in a way that can lead to meaningful reporting. I’ve described a couple of highlights below 👇 /4
My first attempt was in 2016 at Propublica, when I was working with @JuliaAngwin . We were interested in seeing if there was a difference in the Ad interests FB disclosed to users in their settings and the interests they showed to marketers. /5
.@corintxt crunched the numbers and found that after Facebook flipped the switch for political ads, partisan content elbowed out reputable news outlets in our panelists’ news feeds. https://t.co/Z0kibSBeQZ /2
You can learn more in our methodology, where we describe how we did this and what steps we took to ensure that we preserved the panelists' privacy. https://t.co/UYbTXAjy5i /3
Personally, this project is the culmination of years of experiments trying to figure out how to collect data from social media platforms in a way that can lead to meaningful reporting. I’ve described a couple of highlights below 👇 /4
My first attempt was in 2016 at Propublica, when I was working with @JuliaAngwin . We were interested in seeing if there was a difference in the Ad interests FB disclosed to users in their settings and the interests they showed to marketers. /5
You May Also Like




Recently, the @CNIL issued a decision regarding the GDPR compliance of an unknown French adtech company named "Vectaury". It may seem like small fry, but the decision has potential wide-ranging impacts for Google, the IAB framework, and today's adtech. It's thread time! 👇
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.