If you're not aware about what a Dataframe is, It's an optimized data structure for loading data, analysing it, manipulating data in it, and Mostly gathering insights.
It uses Cython backend which transpiles into C for optimized code.
Here's how a dataframe looks like,
Before we start, You need to ensure, you have pandas installed. If you don't, Do that before moving ahead!
Here are the tips, Let's go!
1/ Convert PD series to Dataframe
We all have struggled, when we deal with pandas series. It's always easier to work with Dataframes, rather than series. Here is how you can convert series to dataframe easily.
2/ How to create dummy Dataframe for testing
We always need dataframes for testing and analysing normally, if we do not have data ready. Here is how you can use Pandas API to generate different types of data.
3/ Remove a column from the current DF and Convert it as separate series
We sometimes need to remove a column from dataframe, and use it separately for other use. Here is how you can do that!
4/ Easily renaming columns
In order to rename specific columns, or Override everything, or just change things a bit easily, Here is how you can do renaming in 2 major ways, along with a tip to lowercase column names.
5/ Add prefix / suffix to column names
Sometimes, We need to add specific naming patterns to the columns names in a dataframe, such as adding `_train` to end, or `test_` in front. Here's the easiest way to do that!
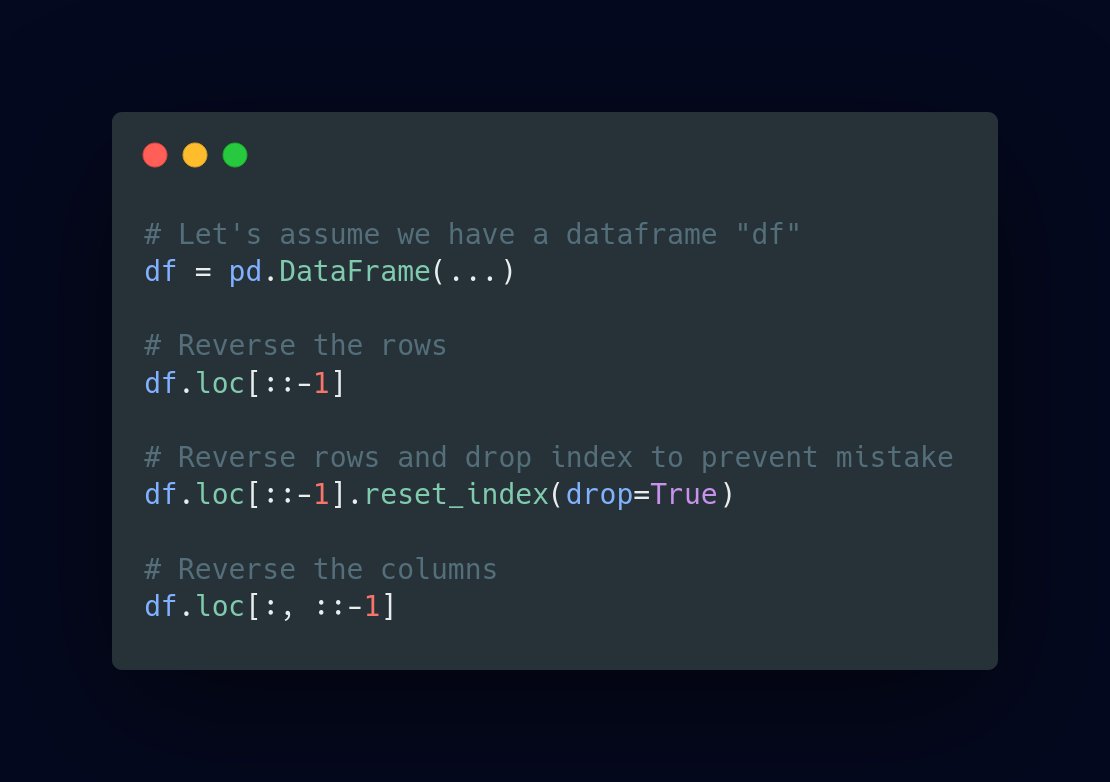
6/ Reversing a Dataframe in different orders
Sometimes, We have the need to reverse a dataframe, either by columns, or rows. This is the perfect way to do it!
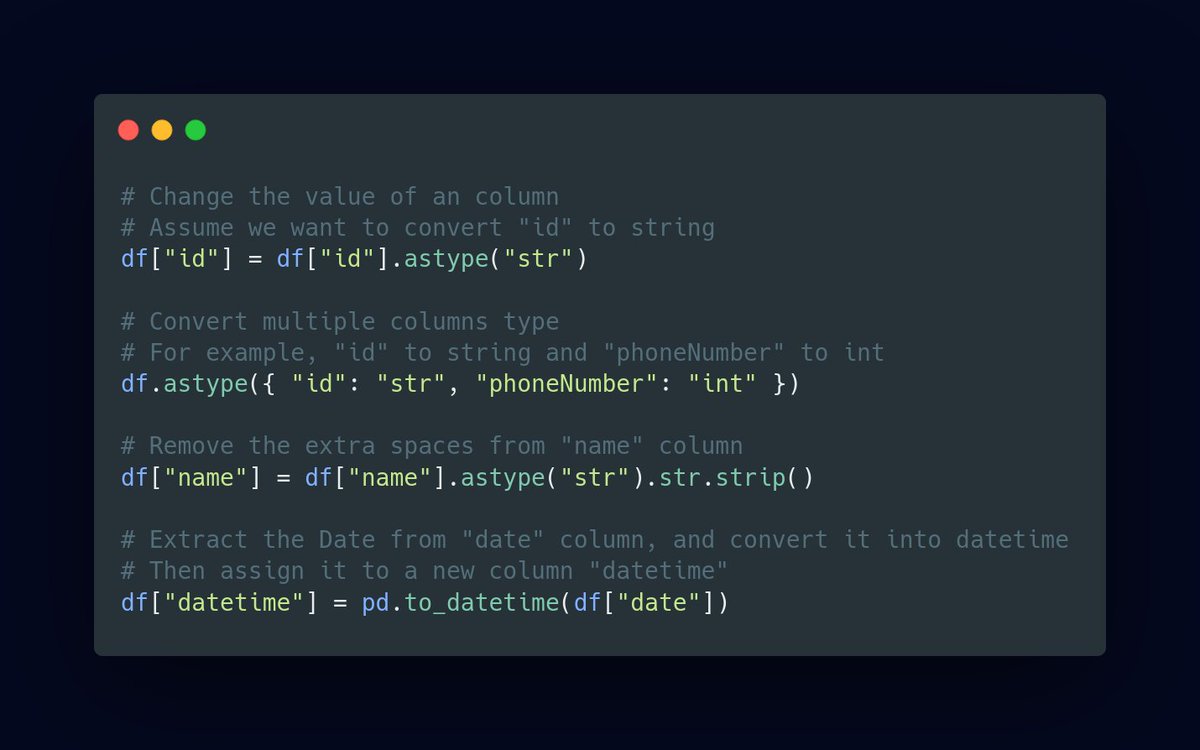
7/ Fixing data types and Making columns as needed
Sometimes columns are in the wrong data type which needs to be fixed, and We need to create a column from existing ones for several purpose.
An easy way to do it, is this,
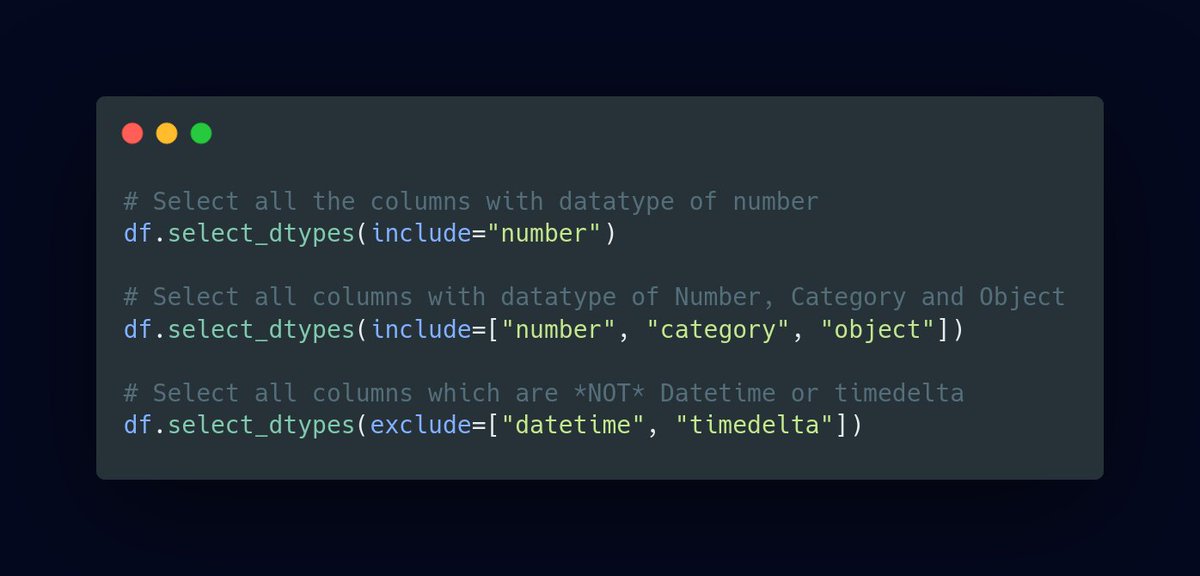
8/ Selecting columns by data type
There are several instances, where we need to select column by data type. For example, processing and cleaning categorical and numerical variables separately. Here is how to select them differently, really easily!
9/ Check the datatypes in a column, when annotated as "object"
When a column is given the type of "object", It may or may not have multiple types of data. Here is an easy way to check that!
10/ Converting columns from Continuous to categorical
There are a lot of instances, where we need to organize continuous variable into categories. Such as age column can be organized by Giving categories.
0-18: Child
18-66: Adult
66-100: Seniors
Here's how to do it,
11/ Combine dates spread across multiple columns
Sometimes, When we have Date, Month and Year as different columns, It can get pretty hard, since it's Time-Series data. In order to combine them, Here is how that can be done.
12/ Comparing if 2 series / dataframes are same
There are a lot of times, When we need to compare between pandas Series, or Dataframes, and Check if they're same. Here is the right way to do it!
13/ Plotting using Pandas
Pandas provides a REALLY EASY way to perform plotting and create graphs combined with matplotlib library. Matplotlib's a story, for another day.
Here is the link to official docs for tutorial on that:
https://t.co/Embc3jwD8u Let's see how to!
14/ Get memory usage of dataframe
A lot of instances, Large data when loaded, take up a lot of memory. Here is an easy and quick way to analyse the memory usage.
15/ Impute missing values in Time-Series data
Real world, does have a lot of missing data. Time-Series is a one type of data, which has that too! Pandas makes it really easy to impute and fill them. Here's how to
16/ Shuffle rows in Pandas
Shuffling rows is really useful, especially when randomizing the dataset before Splitting and feeding into model to ensure randomness. Here's the easiest way to do.
17/ Split the dataset into 2 Random sets
When working with ML or Data science, Usually we need to split data into 2 sets, Training and Test. Sometimes even validation.
Here is how you can do that using Pandas.
PS: Scikit learn can do this too using train_test_split
18/ Ignoring warnings easily [PYTHON]
Warnings are usually redundant, except some cases. So, Here is how you can directly ignore them from Python.
BONUS, Auto EDA!
There are some libraries which can perform auto EDA, gather insights automatically from the dataset, and Display it! This is effective when you have done a lot of EDA, Analyze rest of it easily, and quickly.
We'll be using Pandas profiling. Here's how to do it.
You have reached the end! 👋
Really enjoyed sharing these useful functions in Pandas with you! More amazing content, Coming soon, next time!
Let me know, what you think! And If you're feeling generous, Do retweet to share with everyone else!
It's time for me to leave.
Don't forget to follow me at
@JanaSunrise, I keep making such amazing content!
If you don't know me, I'm Sunrit & I make amazing content on ML, Python, Startups & More! 🤗
Stay safe and take care! Thank you for everything, See you next time ❤️ Bye!