
1/ A ∞-wide NN of *any architecture* is a Gaussian process (GP) at init. The NN in fact evolves linearly in function space under SGD, so is a GP at *any time* during training. https://t.co/v1b6kndqCk With Tensor Programs, we can calculate this time-evolving GP w/o trainin any NN
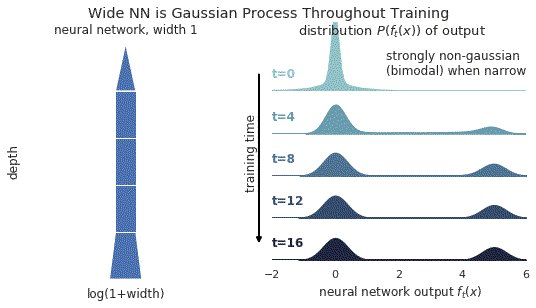
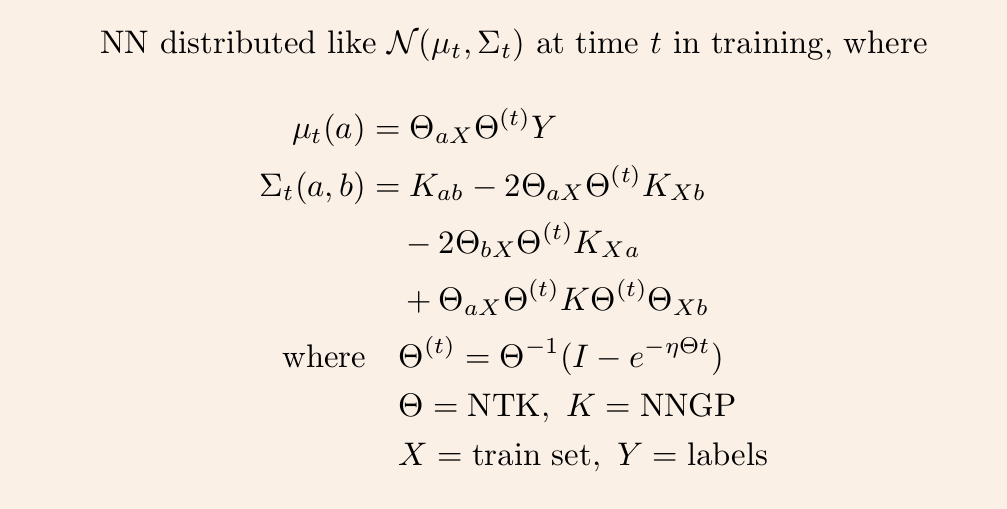
https://t.co/6RO7VZDQNZ
https://t.co/OOoOMdPOsR
More from Data science

✨✨ BIG NEWS: We are hiring!! ✨✨
Amazing Research Software Engineer / Research Data Scientist positions within the @turinghut23 group at the @turinginst, at Standard (permanent) and Junior levels 🤩
👇 Here below a thread on who we are and what we
We are a highly diverse and interdisciplinary group of around 30 research software engineers and data scientists 😎💻 👉 https://t.co/KcSVMb89yx #RSEng
We value expertise across many domains - members of our group have backgrounds in psychology, mathematics, digital humanities, biology, astrophysics and many other areas 🧬📖🧪📈🗺️⚕️🪐
https://t.co/zjoQDGxKHq
/ @DavidBeavan @LivingwMachines
In our everyday job we turn cutting edge research into professionally usable software tools. Check out @evelgab's #LambdaDays 👩💻 presentation for some examples:
We create software packages to analyse data in a readable, reliable and reproducible fashion and contribute to the #opensource community, as @drsarahlgibson highlights in her contributions to @mybinderteam and @turingway: https://t.co/pRqXtFpYXq #ResearchSoftwareHour
Amazing Research Software Engineer / Research Data Scientist positions within the @turinghut23 group at the @turinginst, at Standard (permanent) and Junior levels 🤩
👇 Here below a thread on who we are and what we
We are a highly diverse and interdisciplinary group of around 30 research software engineers and data scientists 😎💻 👉 https://t.co/KcSVMb89yx #RSEng
We value expertise across many domains - members of our group have backgrounds in psychology, mathematics, digital humanities, biology, astrophysics and many other areas 🧬📖🧪📈🗺️⚕️🪐
https://t.co/zjoQDGxKHq
/ @DavidBeavan @LivingwMachines
In our everyday job we turn cutting edge research into professionally usable software tools. Check out @evelgab's #LambdaDays 👩💻 presentation for some examples:
We create software packages to analyse data in a readable, reliable and reproducible fashion and contribute to the #opensource community, as @drsarahlgibson highlights in her contributions to @mybinderteam and @turingway: https://t.co/pRqXtFpYXq #ResearchSoftwareHour

























