
Student papers are overlooked, easy to understand, and have good compute constraints.
Tips for AI writers:
1. Spend 30% of your effort on skimming all student ML papers (e.g. Stanford NLP CS224n) the past 3 years and prototype your favorites
The idea is everything. Pick an area you are interested in and ideally something that has a visual aspect to it
Student papers are overlooked, easy to understand, and have good compute constraints.
Create an edge to the project. Apply it to something new and use FastAI or Keras to improve the accuracy with 5-30%.
Have a north star article in terms of structure and quality. Find something that stretches you to your utmost capability. I used @copingbear’s Style transfer article: https://t.co/OrR1B94t1w
Invest a week in studying the strategies to rank on sites like HN and Reddit, then use them. If you have an interesting result and a great article, you've done the hard work.
Articles will market you 24/7 worldwide. You want them to be relevant for a decade. High-quality articles increase your reputation and spread easier on the web.
cc @remiconnesson @mehtadata_
More from Data science


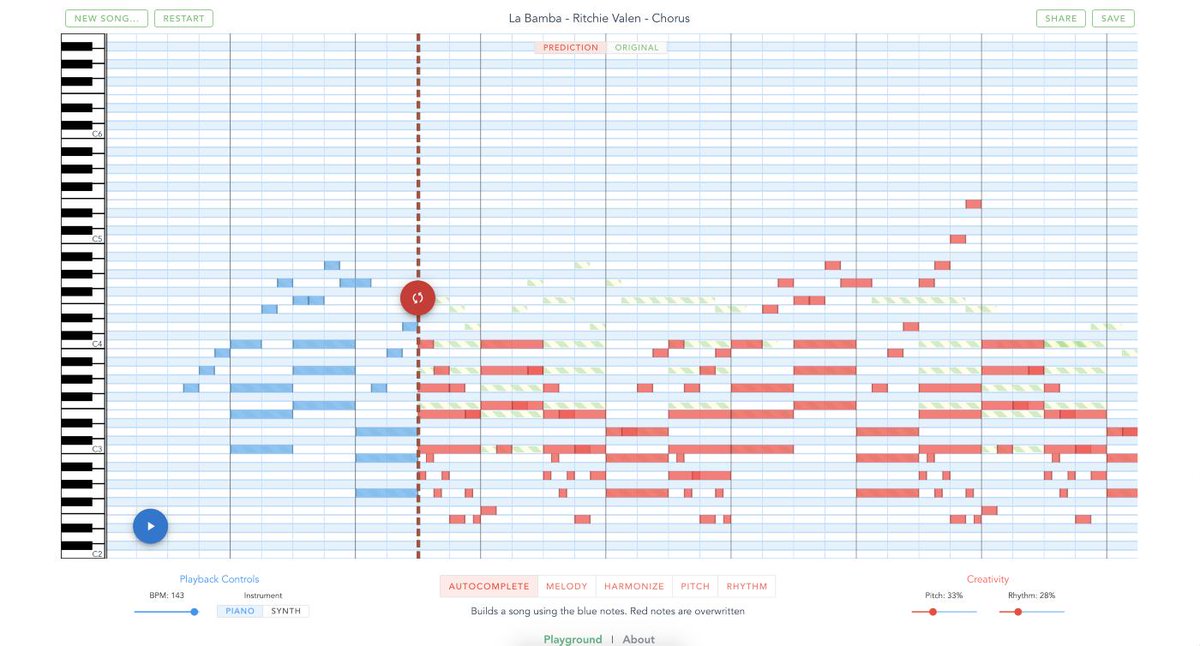
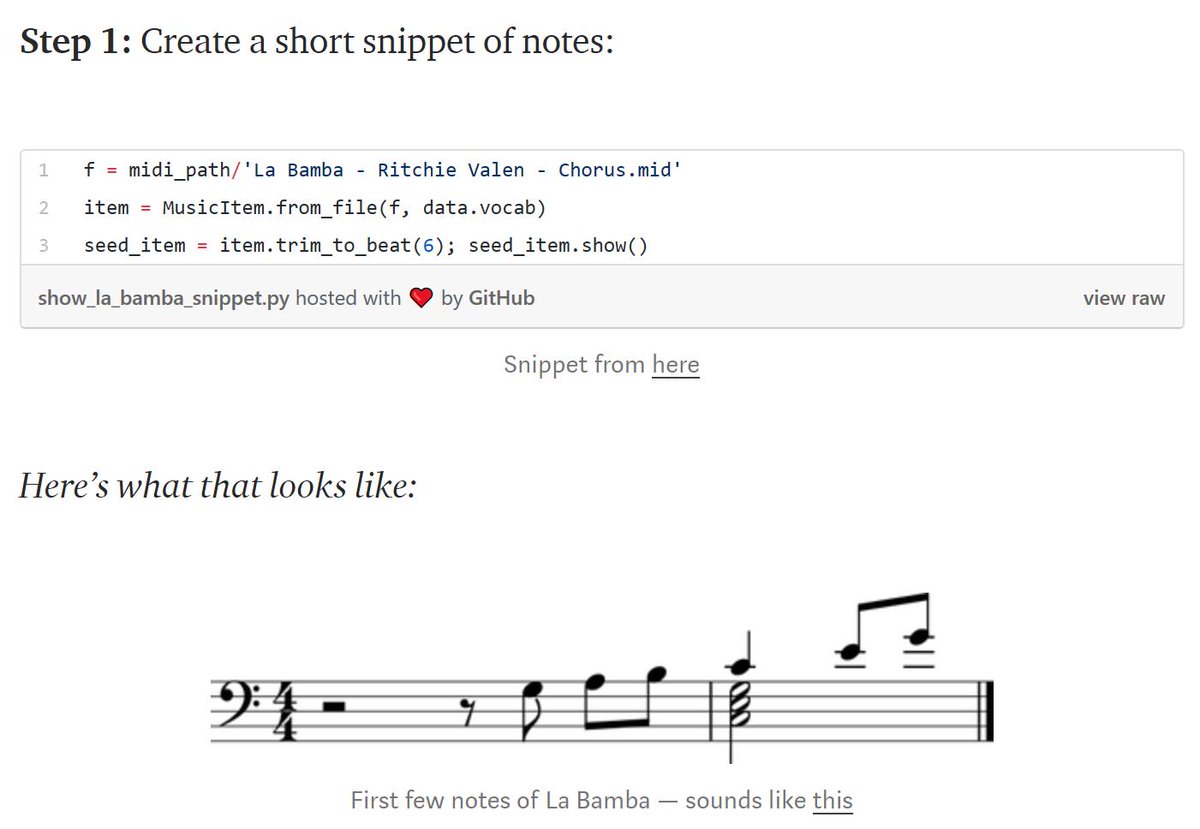


1/ A ∞-wide NN of *any architecture* is a Gaussian process (GP) at init. The NN in fact evolves linearly in function space under SGD, so is a GP at *any time* during training. https://t.co/v1b6kndqCk With Tensor Programs, we can calculate this time-evolving GP w/o trainin any NN
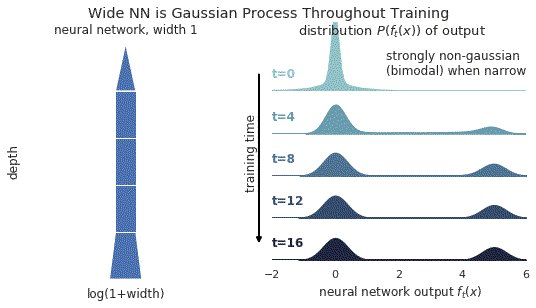
2/ In this gif, narrow relu networks have high probability of initializing near the 0 function (because of relu) and getting stuck. This causes the function distribution to become multi-modal over time. However, for wide relu networks this is not an issue.
3/ This time-evolving GP depends on two kernels: the kernel describing the GP at init, and the kernel describing the linear evolution of this GP. The former is the NNGP kernel, and the latter is the Neural Tangent Kernel (NTK).
4/ Once we have these two kernels, we can derive the GP mean and covariance at any time t via straightforward linear algebra.
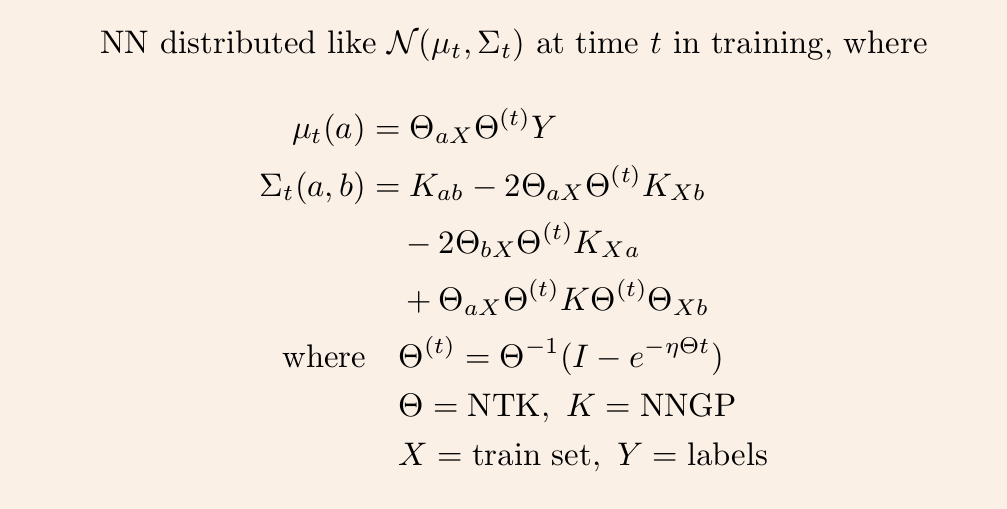
5/ So it remains to calculate the NNGP kernel and NT kernel for any given architecture. The first is described in https://t.co/cFWfNC5ALC and in this thread
2/ In this gif, narrow relu networks have high probability of initializing near the 0 function (because of relu) and getting stuck. This causes the function distribution to become multi-modal over time. However, for wide relu networks this is not an issue.
3/ This time-evolving GP depends on two kernels: the kernel describing the GP at init, and the kernel describing the linear evolution of this GP. The former is the NNGP kernel, and the latter is the Neural Tangent Kernel (NTK).
4/ Once we have these two kernels, we can derive the GP mean and covariance at any time t via straightforward linear algebra.
5/ So it remains to calculate the NNGP kernel and NT kernel for any given architecture. The first is described in https://t.co/cFWfNC5ALC and in this thread























