
✨✨ BIG NEWS: We are hiring!! ✨✨
Amazing Research Software Engineer / Research Data Scientist positions within the @turinghut23 group at the @turinginst, at Standard (permanent) and Junior levels 🤩
👇 Here below a thread on who we are and what we
https://t.co/zjoQDGxKHq
/ @DavidBeavan @LivingwMachines
https://t.co/1KPERqj7If
Hi everyone! I'm Louise Bowler, a Research Data Scientist from @turinginst's Research Engineering Group @turinghut23. I'm borrowing the account for the day to show you all a day in the life of a Research Data Scientist! \U0001f469\u200d\U0001f4bb
— Research Engineering at the Turing (@turinghut23) March 10, 2020
https://t.co/KknkBtl6bg / @CamilaRangelS @radka_jersak @louise_a_bowler
Today this account is being taken over by Kevin Xu, from the civil service fast stream program that is doing a placement in our team for the next 6 months. He will be talking about the projects he is working on and how is to join a new team fully remote. pic.twitter.com/3ULLODPuDV
— Research Engineering at the Turing (@turinghut23) July 1, 2020

https://t.co/PaYng3c5Qa
Today it\u2019s \U0001f389 graduation time \U0001f389 for @openlifesci. @CamilaRangelS Sam Van Stroud @Kevinzhangxu and myself have worked so hard to get here with @TuringDStories \U0001f4ac\U0001f4ca\U0001f4c8\U0001f9e0. If you want to learn how to maximise your open research, then apply for the next cohort https://t.co/t7GUZxP9Fl
— David Beavan (@DavidBeavan) December 15, 2020


https://t.co/0jPjUXvtOu

https://t.co/dgkK45JzN6 #HPC
📨 https://t.co/3e4b0dsEDJ
👉 https://t.co/LnGW7JNQX5

More from Data science

1/ A ∞-wide NN of *any architecture* is a Gaussian process (GP) at init. The NN in fact evolves linearly in function space under SGD, so is a GP at *any time* during training. https://t.co/v1b6kndqCk With Tensor Programs, we can calculate this time-evolving GP w/o trainin any NN
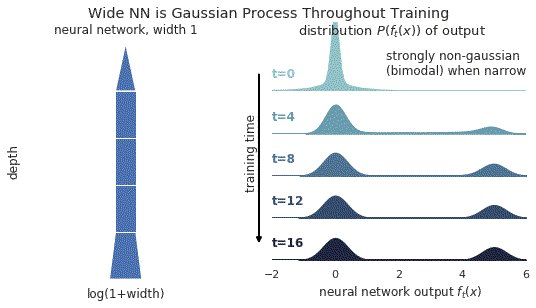
2/ In this gif, narrow relu networks have high probability of initializing near the 0 function (because of relu) and getting stuck. This causes the function distribution to become multi-modal over time. However, for wide relu networks this is not an issue.
3/ This time-evolving GP depends on two kernels: the kernel describing the GP at init, and the kernel describing the linear evolution of this GP. The former is the NNGP kernel, and the latter is the Neural Tangent Kernel (NTK).
4/ Once we have these two kernels, we can derive the GP mean and covariance at any time t via straightforward linear algebra.
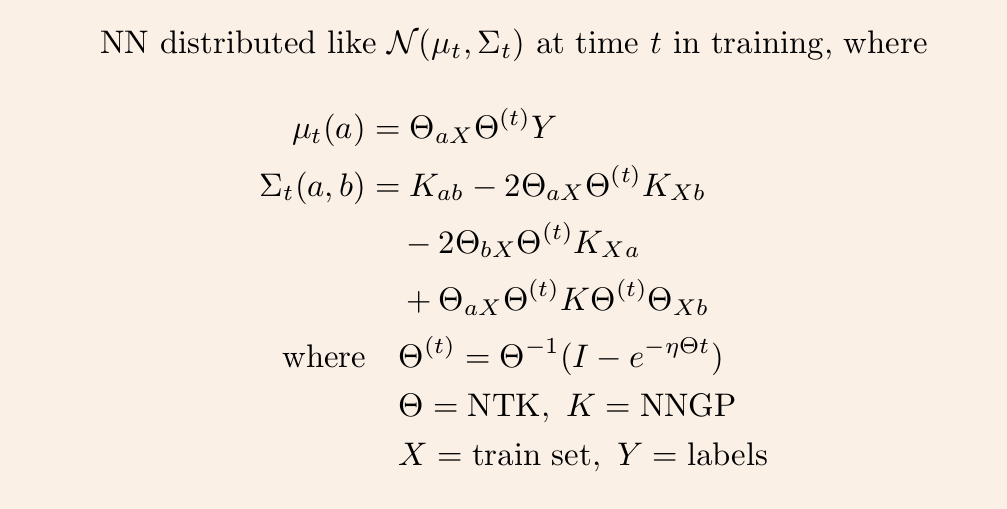
5/ So it remains to calculate the NNGP kernel and NT kernel for any given architecture. The first is described in https://t.co/cFWfNC5ALC and in this thread
2/ In this gif, narrow relu networks have high probability of initializing near the 0 function (because of relu) and getting stuck. This causes the function distribution to become multi-modal over time. However, for wide relu networks this is not an issue.
3/ This time-evolving GP depends on two kernels: the kernel describing the GP at init, and the kernel describing the linear evolution of this GP. The former is the NNGP kernel, and the latter is the Neural Tangent Kernel (NTK).
4/ Once we have these two kernels, we can derive the GP mean and covariance at any time t via straightforward linear algebra.
5/ So it remains to calculate the NNGP kernel and NT kernel for any given architecture. The first is described in https://t.co/cFWfNC5ALC and in this thread
























