

If you lack discipline, read these 10 quotes:
1.









If you enjoyed this thread, please:
1. Follow me @Art0fDiscipline to improve your life
2. Retweet the first tweet
Have an amazing day :)
More from All


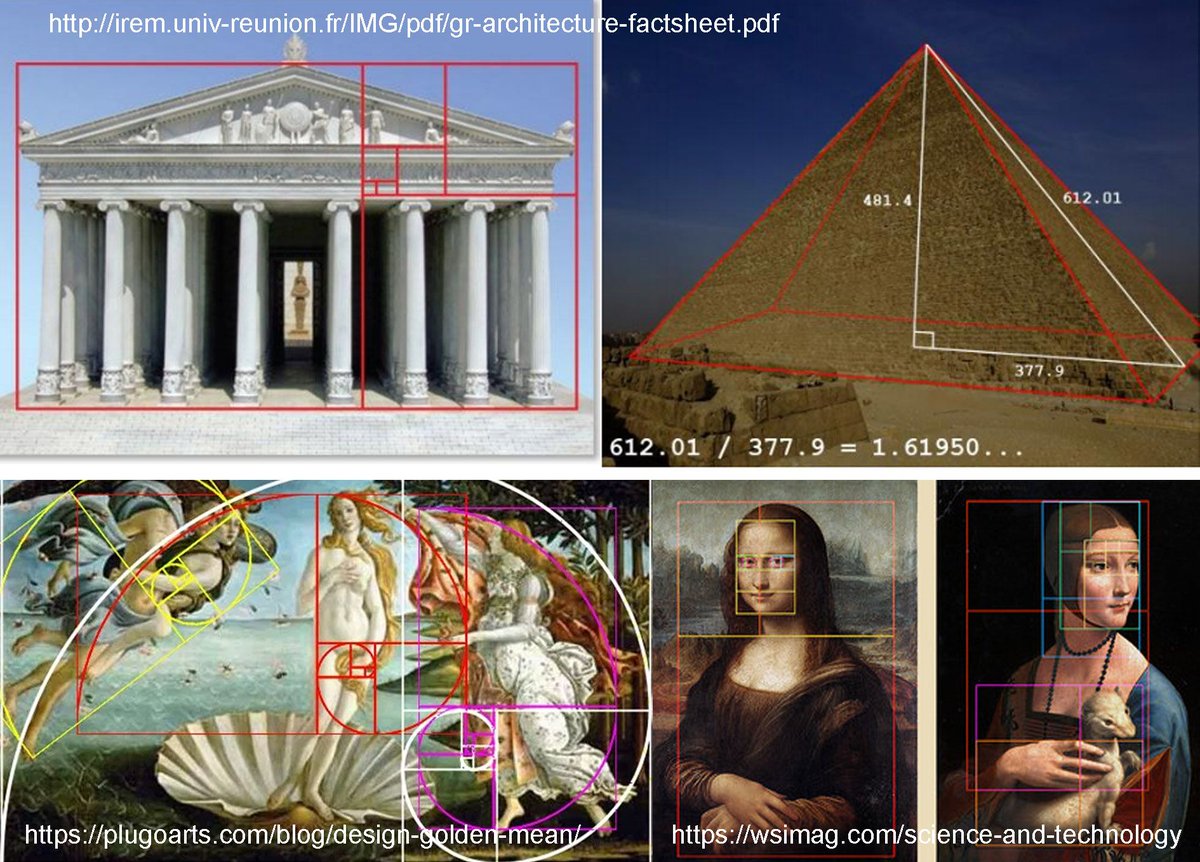
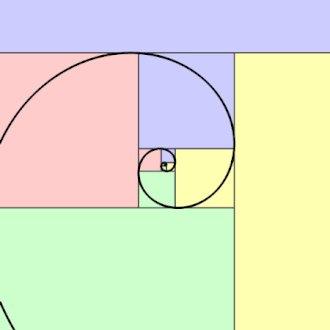
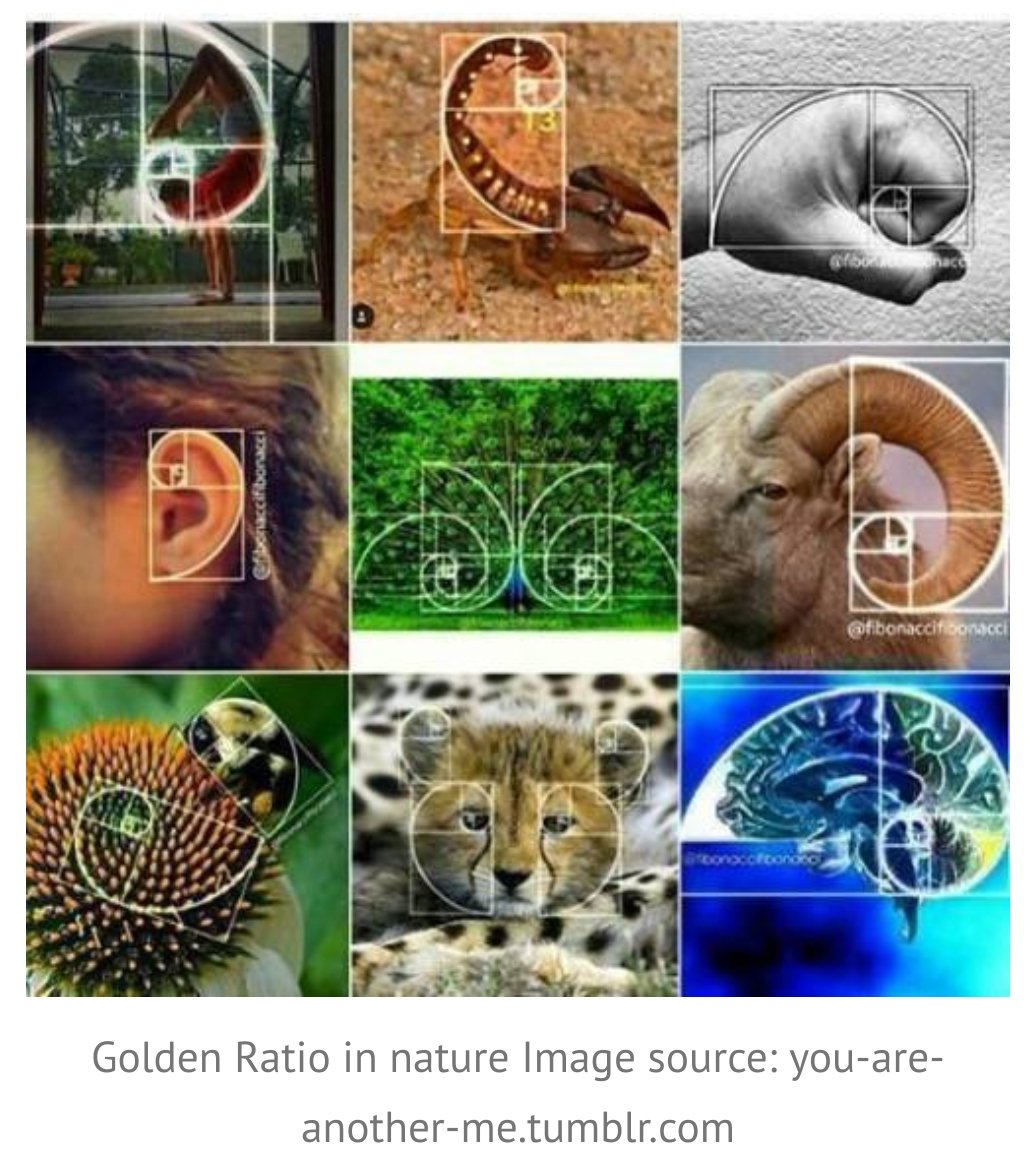







1. Mini Thread on Conflicts of Interest involving the authors of the Nature Toilet Paper:
https://t.co/VUYbsKGncx
Kristian G. Andersen
Andrew Rambaut
Ian Lipkin
Edward C. Holmes
Robert F. Garry
2. Thanks to @newboxer007 for forwarding the link to the research by an Australian in Taiwan (not on
3. K.Andersen didn't mention "competing interests"
Only Garry listed Zalgen Labs, which we will look at later.
In acknowledgements, Michael Farzan, Wellcome Trust, NIH, ERC & ARC are mentioned.
Author affiliations listed as usual.
Note the 328 Citations!
https://t.co/nmOeohM89Q

4. Kristian Andersen (1)
Andersen worked with USAMRIID & Fort Detrick scientists on research, with Robert Garry, Jens Kuhn & Sina Bavari among
5. Kristian Andersen (2)
Works at Scripps Research Institute, which WAS in serious financial trouble, haemorrhaging 20 million $ a year.
But just when the first virus cases were emerging, they received great news.
They issued a press release dated November 27, 2019:
https://t.co/VUYbsKGncx
Kristian G. Andersen
Andrew Rambaut
Ian Lipkin
Edward C. Holmes
Robert F. Garry
2. Thanks to @newboxer007 for forwarding the link to the research by an Australian in Taiwan (not on
3. K.Andersen didn't mention "competing interests"
Only Garry listed Zalgen Labs, which we will look at later.
In acknowledgements, Michael Farzan, Wellcome Trust, NIH, ERC & ARC are mentioned.
Author affiliations listed as usual.
Note the 328 Citations!
https://t.co/nmOeohM89Q
4. Kristian Andersen (1)
Andersen worked with USAMRIID & Fort Detrick scientists on research, with Robert Garry, Jens Kuhn & Sina Bavari among
Our Hans Kristian Andersen working with Jens H. Kuhn, Sina Bavari, Robert F. Garry, Stuart T. Nichol,Gustavo Palacios, Sheli R. Radoshitzky from USAMRIID and Fort Detrick to tell more fairy tales? Full emails listed for queries...https://t.co/kLRoQTxiGD pic.twitter.com/uHNuGraPP2
— Billy Bostickson \U0001f3f4\U0001f441&\U0001f441 \U0001f193 (@BillyBostickson) August 26, 2020
5. Kristian Andersen (2)
Works at Scripps Research Institute, which WAS in serious financial trouble, haemorrhaging 20 million $ a year.
But just when the first virus cases were emerging, they received great news.
They issued a press release dated November 27, 2019:

How can we use language supervision to learn better visual representations for robotics?
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)

Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)
Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)
You May Also Like












"I really want to break into Product Management"
make products.
"If only someone would tell me how I can get a startup to notice me."
Make Products.
"I guess it's impossible and I'll never break into the industry."
MAKE PRODUCTS.
Courtesy of @edbrisson's wonderful thread on breaking into comics – https://t.co/TgNblNSCBj – here is why the same applies to Product Management, too.
There is no better way of learning the craft of product, or proving your potential to employers, than just doing it.
You do not need anybody's permission. We don't have diplomas, nor doctorates. We can barely agree on a single standard of what a Product Manager is supposed to do.
But – there is at least one blindingly obvious industry consensus – a Product Manager makes Products.
And they don't need to be kept at the exact right temperature, given endless resource, or carefully protected in order to do this.
They find their own way.
make products.
"If only someone would tell me how I can get a startup to notice me."
Make Products.
"I guess it's impossible and I'll never break into the industry."
MAKE PRODUCTS.
Courtesy of @edbrisson's wonderful thread on breaking into comics – https://t.co/TgNblNSCBj – here is why the same applies to Product Management, too.
"I really want to break into comics"
— Ed Brisson (@edbrisson) December 4, 2018
make comics.
"If only someone would tell me how I can get an editor to notice me."
Make Comics.
"I guess it's impossible and I'll never break into the industry."
MAKE COMICS.
There is no better way of learning the craft of product, or proving your potential to employers, than just doing it.
You do not need anybody's permission. We don't have diplomas, nor doctorates. We can barely agree on a single standard of what a Product Manager is supposed to do.
But – there is at least one blindingly obvious industry consensus – a Product Manager makes Products.
And they don't need to be kept at the exact right temperature, given endless resource, or carefully protected in order to do this.
They find their own way.




