
https://t.co/ZRWYnnu5Ss
10 Google courses with FREE Certifications
📌 Programming
📌 Data Structures and Algorithm
📌 Web Development and Android Development
📌 Digital Marketing
📌 Data Science and Artificial Intelligence and many more
A Thread🧵👇
➡ Follow me
@adiig7
➡ Retweet the first tweet
Happy Learning!🚀
More from All

















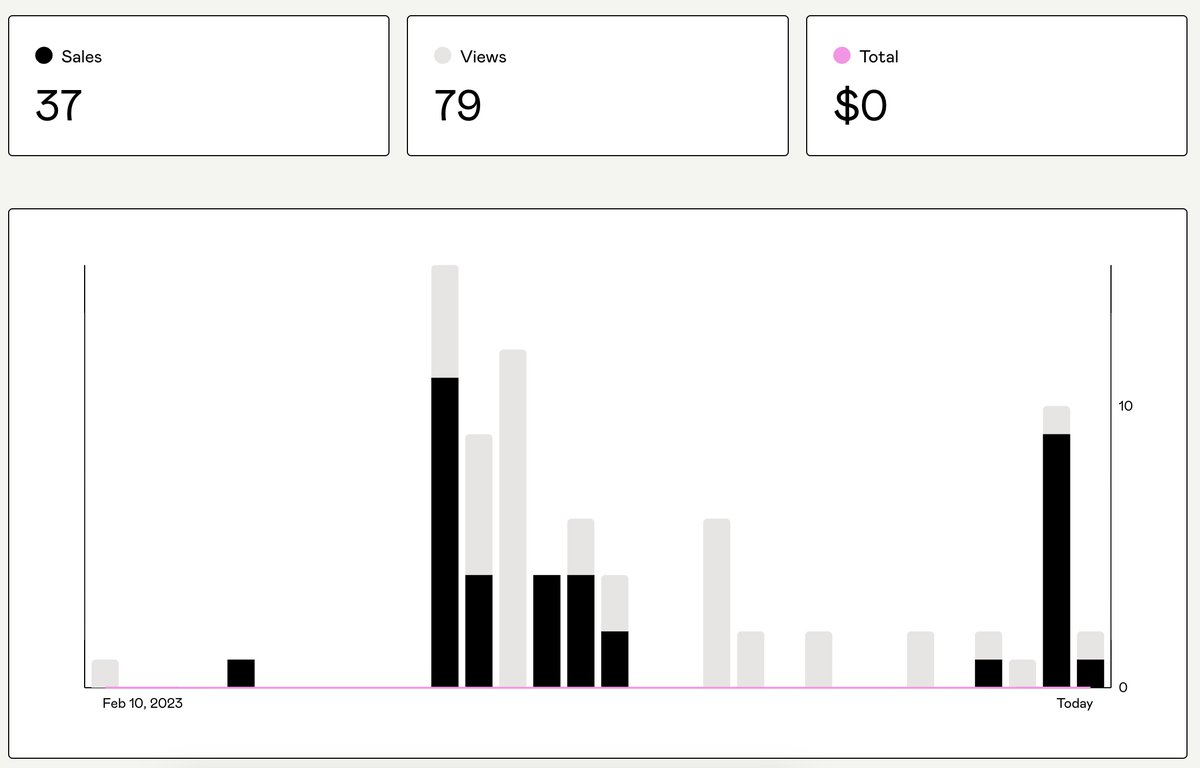
You May Also Like


Keep dwelling on this:
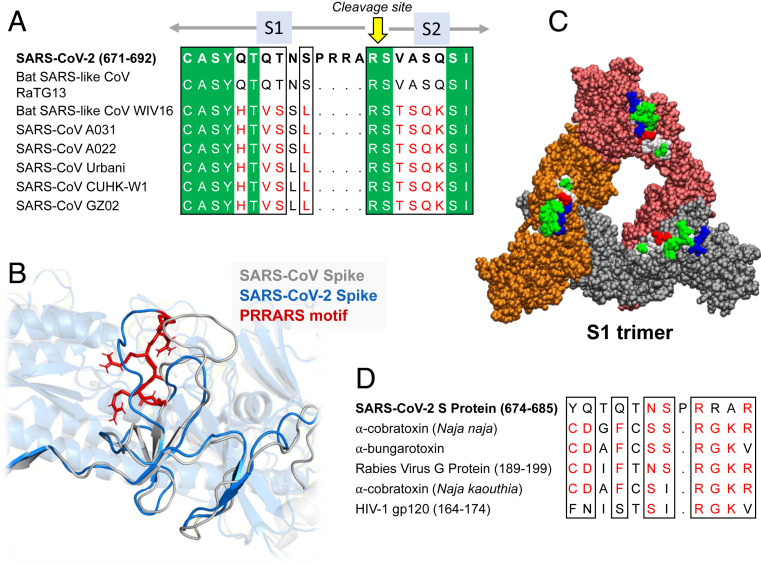
Further Examination of the Motif near PRRA Reveals Close Structural Similarity to the SEB Superantigen as well as Sequence Similarities to Neurotoxins and a Viral SAg.
The insertion PRRA together with 7 sequentially preceding residues & succeeding R685 (conserved in β-CoVs) form a motif, Y674QTQTNSPRRAR685, homologous to those of neurotoxins from Ophiophagus (cobra) and Bungarus genera, as well as neurotoxin-like regions from three RABV strains
(20) (Fig. 2D). We further noticed that the same segment bears close similarity to the HIV-1 glycoprotein gp120 SAg motif F164 to V174.
https://t.co/EwwJOSa8RK
In (B), the segment S680PPRAR685 including the PRRA insert and highly conserved cleavage site *R685* is shown in van der Waals representation (black labels) and nearby CDR residues of the TCRVβ domain are labeled in blue/white
https://t.co/BsY8BAIzDa
Sequence Identity %
https://t.co/BsY8BAIzDa
Y674 - QTQTNSPRRA - R685
Similar to neurotoxins from Ophiophagus (cobra) & Bungarus genera & neurotoxin-like regions from three RABV strains
T678 - NSPRRA- R685
Superantigenic core, consistently aligned against bacterial or viral SAgs

Further Examination of the Motif near PRRA Reveals Close Structural Similarity to the SEB Superantigen as well as Sequence Similarities to Neurotoxins and a Viral SAg.
The insertion PRRA together with 7 sequentially preceding residues & succeeding R685 (conserved in β-CoVs) form a motif, Y674QTQTNSPRRAR685, homologous to those of neurotoxins from Ophiophagus (cobra) and Bungarus genera, as well as neurotoxin-like regions from three RABV strains
(20) (Fig. 2D). We further noticed that the same segment bears close similarity to the HIV-1 glycoprotein gp120 SAg motif F164 to V174.
https://t.co/EwwJOSa8RK
In (B), the segment S680PPRAR685 including the PRRA insert and highly conserved cleavage site *R685* is shown in van der Waals representation (black labels) and nearby CDR residues of the TCRVβ domain are labeled in blue/white
https://t.co/BsY8BAIzDa
Sequence Identity %
https://t.co/BsY8BAIzDa
Y674 - QTQTNSPRRA - R685
Similar to neurotoxins from Ophiophagus (cobra) & Bungarus genera & neurotoxin-like regions from three RABV strains
T678 - NSPRRA- R685
Superantigenic core, consistently aligned against bacterial or viral SAgs









