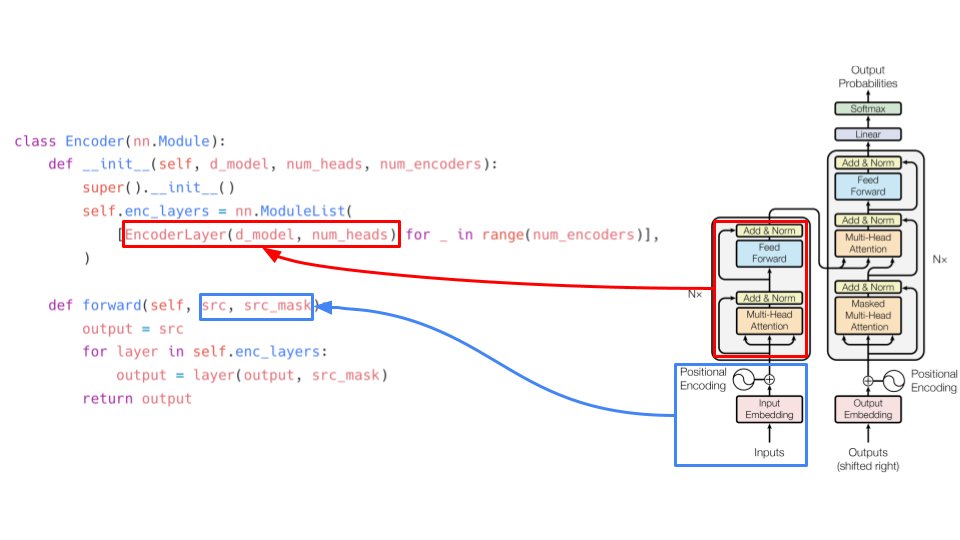
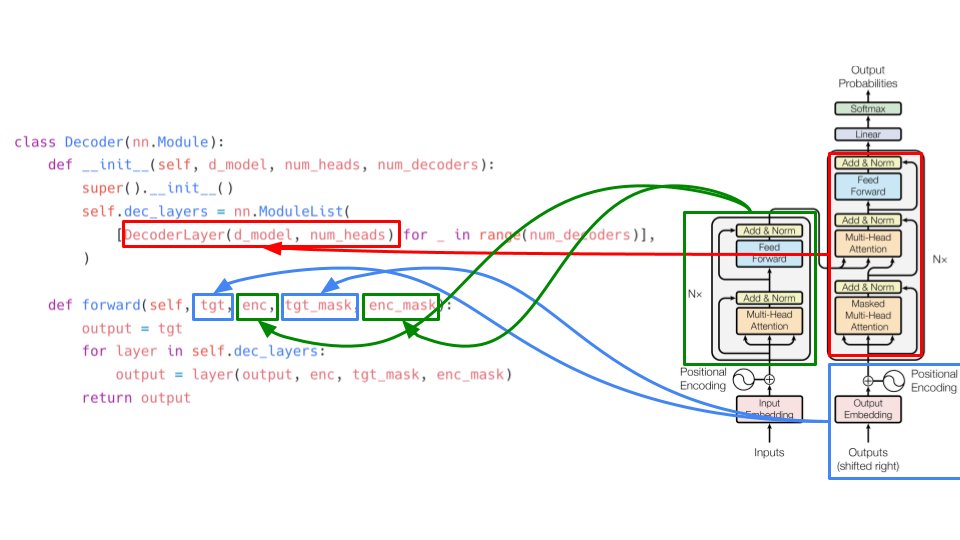
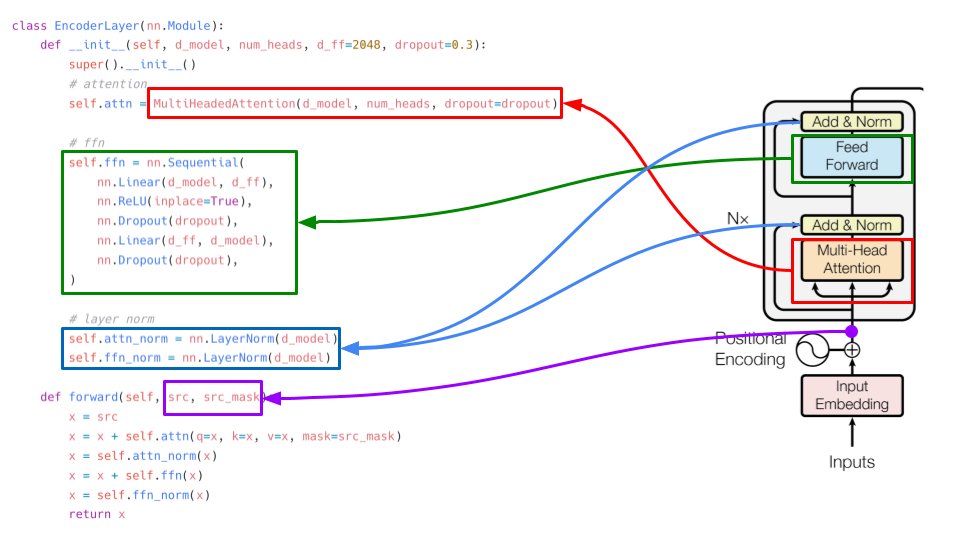
"Attention is all you need" implementation from scratch in PyTorch. A Twitter thread:
1/







More from All





#ஆதித்தியஹ்ருதயம் ஸ்தோத்திரம்
இது சூரிய குலத்தில் உதித்த இராமபிரானுக்கு தமிழ் முனிவர் அகத்தியர் உபதேசித்ததாக வால்மீகி இராமாயணத்தில் வருகிறது. ஆதித்ய ஹ்ருதயத்தைத் தினமும் ஓதினால் பெரும் பயன் பெறலாம் என மகான்களும் ஞானிகளும் காலம் காலமாகக் கூறி வருகின்றனர். ராம-ராவண யுத்தத்தை

தேவர்களுடன் சேர்ந்து பார்க்க வந்திருந்த அகத்தியர், அப்போது போரினால் களைத்து, கவலையுடன் காணப்பட்ட ராமபிரானை அணுகி, மனிதர்களிலேயே சிறந்தவனான ராமா போரில் எந்த மந்திரத்தைப் பாராயணம் செய்தால் எல்லா பகைவர்களையும் வெல்ல முடியுமோ அந்த ரகசிய மந்திரத்தை, வேதத்தில் சொல்லப்பட்டுள்ளதை உனக்கு
நான் உபதேசிக்கிறேன், கேள் என்று கூறி உபதேசித்தார். முதல் இரு சுலோகங்கள் சூழ்நிலையை விவரிக்கின்றன. மூன்றாவது சுலோகம் அகத்தியர் இராமபிரானை விளித்துக் கூறுவதாக அமைந்திருக்கிறது. நான்காவது சுலோகம் முதல் முப்பதாம் சுலோகம் வரை ஆதித்ய ஹ்ருதயம் என்னும் நூல். முப்பத்தி ஒன்றாம் சுலோகம்
இந்தத் துதியால் மகிழ்ந்த சூரியன் இராமனை வாழ்த்துவதைக் கூறுவதாக அமைந்திருக்கிறது.
ஐந்தாவது ஸ்லோகம்:
ஸர்வ மங்கள் மாங்கல்யம் ஸர்வ பாப ப்ரநாசனம்
சிந்தா சோக ப்ரசமனம் ஆயுர் வர்த்தனம் உத்தமம்
பொருள்: இந்த அதித்ய ஹ்ருதயம் என்ற துதி மங்களங்களில் சிறந்தது, பாவங்களையும் கவலைகளையும்

குழப்பங்களையும் நீக்குவது, வாழ்நாளை நீட்டிப்பது, மிகவும் சிறந்தது. இதயத்தில் வசிக்கும் பகவானுடைய அனுக்ரகத்தை அளிப்பதாகும்.
முழு ஸ்லோக லிங்க் பொருளுடன் இங்கே உள்ளது https://t.co/Q3qm1TfPmk
சூரியன் உலக இயக்கத்திற்கு மிக முக்கியமானவர். சூரிய சக்தியால்தான் ஜீவராசிகள், பயிர்கள்
இது சூரிய குலத்தில் உதித்த இராமபிரானுக்கு தமிழ் முனிவர் அகத்தியர் உபதேசித்ததாக வால்மீகி இராமாயணத்தில் வருகிறது. ஆதித்ய ஹ்ருதயத்தைத் தினமும் ஓதினால் பெரும் பயன் பெறலாம் என மகான்களும் ஞானிகளும் காலம் காலமாகக் கூறி வருகின்றனர். ராம-ராவண யுத்தத்தை
தேவர்களுடன் சேர்ந்து பார்க்க வந்திருந்த அகத்தியர், அப்போது போரினால் களைத்து, கவலையுடன் காணப்பட்ட ராமபிரானை அணுகி, மனிதர்களிலேயே சிறந்தவனான ராமா போரில் எந்த மந்திரத்தைப் பாராயணம் செய்தால் எல்லா பகைவர்களையும் வெல்ல முடியுமோ அந்த ரகசிய மந்திரத்தை, வேதத்தில் சொல்லப்பட்டுள்ளதை உனக்கு
நான் உபதேசிக்கிறேன், கேள் என்று கூறி உபதேசித்தார். முதல் இரு சுலோகங்கள் சூழ்நிலையை விவரிக்கின்றன. மூன்றாவது சுலோகம் அகத்தியர் இராமபிரானை விளித்துக் கூறுவதாக அமைந்திருக்கிறது. நான்காவது சுலோகம் முதல் முப்பதாம் சுலோகம் வரை ஆதித்ய ஹ்ருதயம் என்னும் நூல். முப்பத்தி ஒன்றாம் சுலோகம்
இந்தத் துதியால் மகிழ்ந்த சூரியன் இராமனை வாழ்த்துவதைக் கூறுவதாக அமைந்திருக்கிறது.
ஐந்தாவது ஸ்லோகம்:
ஸர்வ மங்கள் மாங்கல்யம் ஸர்வ பாப ப்ரநாசனம்
சிந்தா சோக ப்ரசமனம் ஆயுர் வர்த்தனம் உத்தமம்
பொருள்: இந்த அதித்ய ஹ்ருதயம் என்ற துதி மங்களங்களில் சிறந்தது, பாவங்களையும் கவலைகளையும்
குழப்பங்களையும் நீக்குவது, வாழ்நாளை நீட்டிப்பது, மிகவும் சிறந்தது. இதயத்தில் வசிக்கும் பகவானுடைய அனுக்ரகத்தை அளிப்பதாகும்.
முழு ஸ்லோக லிங்க் பொருளுடன் இங்கே உள்ளது https://t.co/Q3qm1TfPmk
சூரியன் உலக இயக்கத்திற்கு மிக முக்கியமானவர். சூரிய சக்தியால்தான் ஜீவராசிகள், பயிர்கள்







You May Also Like









1/ Here’s a list of conversational frameworks I’ve picked up that have been helpful.
Please add your own.
2/ The Magic Question: "What would need to be true for you
3/ On evaluating where someone’s head is at regarding a topic they are being wishy-washy about or delaying.
“Gun to the head—what would you decide now?”
“Fast forward 6 months after your sabbatical--how would you decide: what criteria is most important to you?”
4/ Other Q’s re: decisions:
“Putting aside a list of pros/cons, what’s the *one* reason you’re doing this?” “Why is that the most important reason?”
“What’s end-game here?”
“What does success look like in a world where you pick that path?”
5/ When listening, after empathizing, and wanting to help them make their own decisions without imposing your world view:
“What would the best version of yourself do”?
Please add your own.
2/ The Magic Question: "What would need to be true for you
1/\u201cWhat would need to be true for you to\u2026.X\u201d
— Erik Torenberg (@eriktorenberg) December 4, 2018
Why is this the most powerful question you can ask when attempting to reach an agreement with another human being or organization?
A thread, co-written by @deanmbrody: https://t.co/Yo6jHbSit9
3/ On evaluating where someone’s head is at regarding a topic they are being wishy-washy about or delaying.
“Gun to the head—what would you decide now?”
“Fast forward 6 months after your sabbatical--how would you decide: what criteria is most important to you?”
4/ Other Q’s re: decisions:
“Putting aside a list of pros/cons, what’s the *one* reason you’re doing this?” “Why is that the most important reason?”
“What’s end-game here?”
“What does success look like in a world where you pick that path?”
5/ When listening, after empathizing, and wanting to help them make their own decisions without imposing your world view:
“What would the best version of yourself do”?