

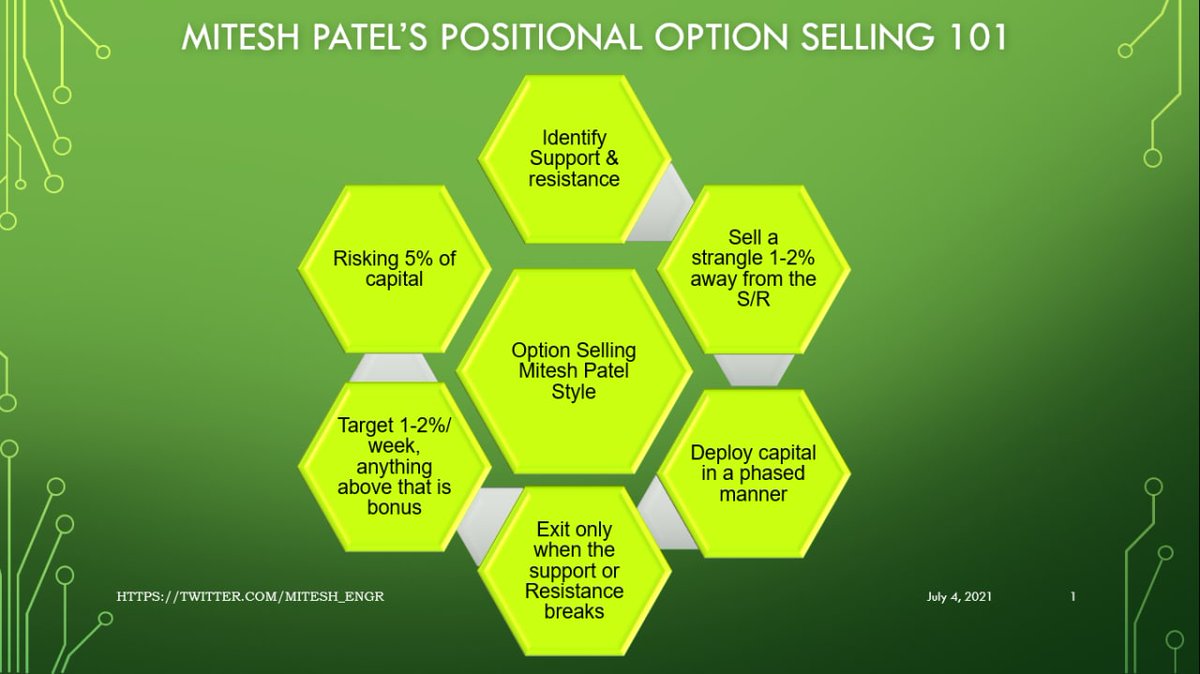
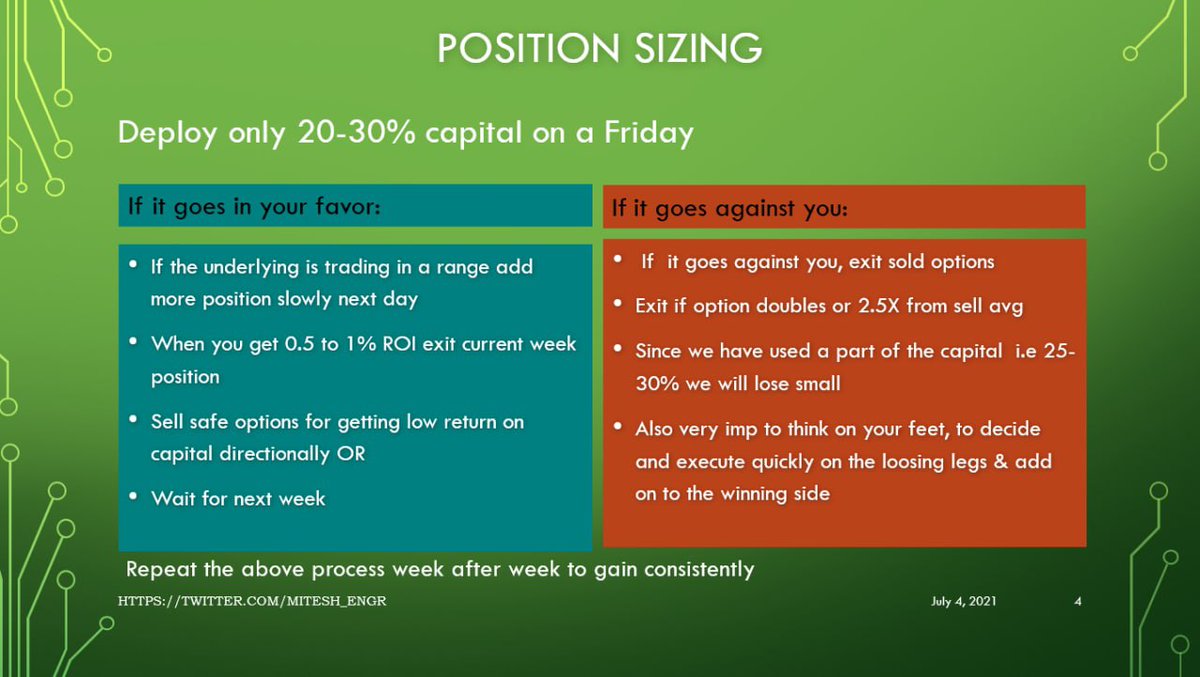
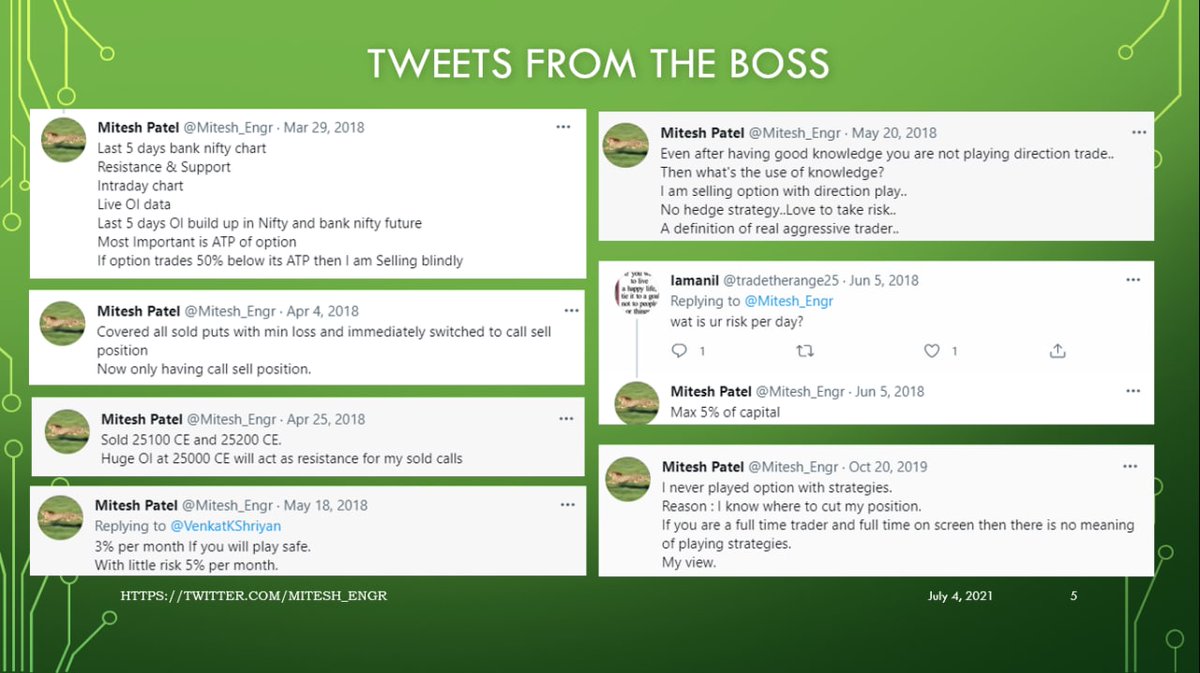
1/ questions raised by linked thread: What are some other significant traits of liberal thinking? One is the tendency to think WEIRDly. Another is the tendency to employ only 1/2 of the evolved psychological mechanisms of social cognition (and of those mostly just care/harm)
1/n Two interesting findings thus far from my analysis of Pew's March 2020 COVID-19 survey. First, white (and especially 'very') liberals are far more likely than all other ideological-racial subgroups to report being diagnosed with a mental health condition. pic.twitter.com/RynS9lk0jR
— Zach Goldberg (@ZachG932) April 11, 2020

Have we been looking at the partisan divide all wrong all along?
Aren’t all of these merely symptoms of deeper causes? Shouldn’t we be looking for THEM?
What we know now is that if the 1st principle of social psychology is “Intuitions come first, strategic reasoning follows,” then
“Psychology (or psychological profile) comes first, intuitions follow.”
We ARE wrong to be thinking, categorizing, analyzing, and concluding based on outdated anachronisms based on which side of the room proponents sat (i.e., left or right),
What if, they asked, reason DIDN’T evolve to help us find truth?
What if, instead, it DID evolve to help us WIN ARGUMENTS; persuade others that OUR intuitions are the RIGHT ones?
More from All







You May Also Like




1/Politics thread time.
To me, the most important aspect of the 2018 midterms wasn't even about partisan control, but about democracy and voting rights. That's the real battle.
2/The good news: It's now an issue that everyone's talking about, and that everyone cares about.
3/More good news: Florida's proposition to give felons voting rights won. But it didn't just win - it won with substantial support from Republican voters.
That suggests there is still SOME grassroots support for democracy that transcends
4/Yet more good news: Michigan made it easier to vote. Again, by plebiscite, showing broad support for voting rights as an
5/OK, now the bad news.
We seem to have accepted electoral dysfunction in Florida as a permanent thing. The 2000 election has never really
To me, the most important aspect of the 2018 midterms wasn't even about partisan control, but about democracy and voting rights. That's the real battle.
2/The good news: It's now an issue that everyone's talking about, and that everyone cares about.
3/More good news: Florida's proposition to give felons voting rights won. But it didn't just win - it won with substantial support from Republican voters.
That suggests there is still SOME grassroots support for democracy that transcends
4/Yet more good news: Michigan made it easier to vote. Again, by plebiscite, showing broad support for voting rights as an
5/OK, now the bad news.
We seem to have accepted electoral dysfunction in Florida as a permanent thing. The 2000 election has never really
Bad ballot design led to a lot of undervotes for Bill Nelson in Broward Co., possibly even enough to cost him his Senate seat. They do appear to be real undervotes, though, instead of tabulation errors. He doesn't really seem to have a path to victory. https://t.co/utUhY2KTaR
— Nate Silver (@NateSilver538) November 16, 2018









