
They sure will. Here's a quick analysis of how, from my perspective as someone who studies societal impacts of natural language technology:
I have no idea how, but these will end up being racist https://t.co/pjZN0WXnnE
— Michael Hobbes (@RottenInDenmark) December 16, 2020
More from Tech





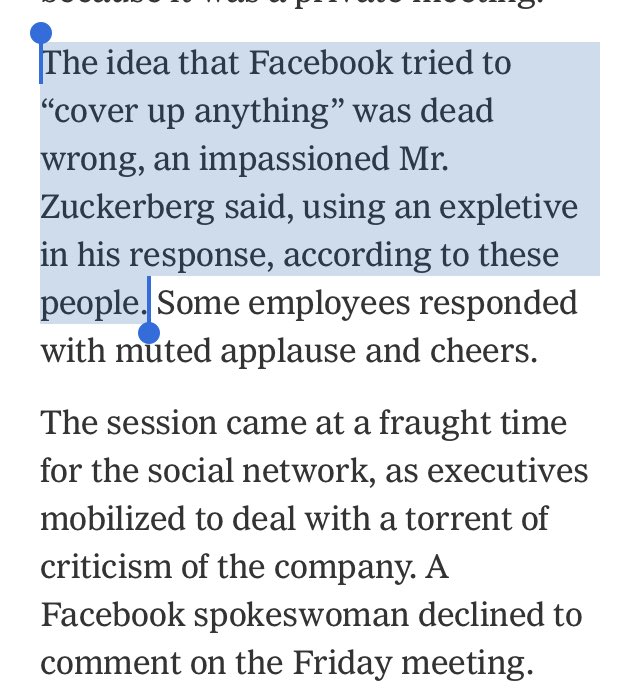
I could create an entire twitter feed of things Facebook has tried to cover up since 2015. Where do you want to start, Mark and Sheryl? https://t.co/1trgupQEH9
Ok, here. Just one of the 236 mentions of Facebook in the under read but incredibly important interim report from Parliament. ht @CommonsCMS https://t.co/gfhHCrOLeU

Let’s do another, this one to Senate Intel. Question: “Were you or CEO Mark Zuckerberg aware of the hiring of Joseph Chancellor?"
Answer "Facebook has over 30,000 employees. Senior management does not participate in day-today hiring decisions."

Or to @CommonsCMS: Question: "When did Mark Zuckerberg know about Cambridge Analytica?"
Answer: "He did not become aware of allegations CA may not have deleted data about FB users obtained through Dr. Kogan's app until March of 2018, when
these issues were raised in the media."

If you prefer visuals, watch this short clip after @IanCLucas rightly expresses concern about a Facebook exec failing to disclose info.
Ok, here. Just one of the 236 mentions of Facebook in the under read but incredibly important interim report from Parliament. ht @CommonsCMS https://t.co/gfhHCrOLeU
Let’s do another, this one to Senate Intel. Question: “Were you or CEO Mark Zuckerberg aware of the hiring of Joseph Chancellor?"
Answer "Facebook has over 30,000 employees. Senior management does not participate in day-today hiring decisions."
Or to @CommonsCMS: Question: "When did Mark Zuckerberg know about Cambridge Analytica?"
Answer: "He did not become aware of allegations CA may not have deleted data about FB users obtained through Dr. Kogan's app until March of 2018, when
these issues were raised in the media."
If you prefer visuals, watch this short clip after @IanCLucas rightly expresses concern about a Facebook exec failing to disclose info.
A company as powerful as @facebook should be subject to proper scrutiny. Mike Schroepfer, its CTO, told us that the buck stops with Mark Zuckerberg on the Cambridge Analytica scandal, which is why he should come and answer our questions @DamianCollins @IanCLucas pic.twitter.com/0H4VMhtIFu
— Digital, Culture, Media and Sport Committee (@CommonsCMS) May 23, 2018

After getting good feedback on yesterday's thread on #routemobile I think it is logical to do a bit in-depth technical study. Place #twilio at center, keep #routemobile & #tanla at the periphery & see who is each placed.
This thread is inspired by one of the articles I read on the-ken about #postman API & how they are transforming & expediting software product delivery & consumption, leading to enhanced developer productivity.
We all know that #Twilio offers host of APIs that can be readily used for faster integration by anyone who wants to have communication capabilities. Before we move ahead, let's get a few things cleared out.
Can anyone build the programming capability to process payments or communication capabilities? Yes, but will they, the answer is NO. Companies prefer to consume APIs offered by likes of #Stripe #twilio #Shopify #razorpay etc.
This offers two benefits - faster time to market, of course that means no need to re-invent the wheel + not worrying of compliance around payment process or communication regulations. This makes entire ecosystem extremely agile
So I have been studying this entire communication layer as its relevance is ever growing with more devices coming online, staying connected, and relying on real-time communication. Not that this domain under penetrated, but there is a change underway.
— Ameya (@Finstor85) February 10, 2021
This thread is inspired by one of the articles I read on the-ken about #postman API & how they are transforming & expediting software product delivery & consumption, leading to enhanced developer productivity.
We all know that #Twilio offers host of APIs that can be readily used for faster integration by anyone who wants to have communication capabilities. Before we move ahead, let's get a few things cleared out.
Can anyone build the programming capability to process payments or communication capabilities? Yes, but will they, the answer is NO. Companies prefer to consume APIs offered by likes of #Stripe #twilio #Shopify #razorpay etc.
This offers two benefits - faster time to market, of course that means no need to re-invent the wheel + not worrying of compliance around payment process or communication regulations. This makes entire ecosystem extremely agile

So we had to develop technologies like this to barely manage control over limited areas in Iraq's few urban centers. Only ~8 in 100 Iraqi adults owns a personal vehicle. That rate is > 1 car/adult in America yet I have never seen any doctrine paper or work of fiction address this
We've seen and struggled in civil conflicts with instant, local, universal, distributed communications (cell phone era, basically every conflict since 2000). We've seen and struggled in conflicts with instant, global, universal distributed communications (everything since 2011).
The world's most overfunded military and glow in the dark agencies struggle and largely fail to contain conflicts where fhe vast, vast majority of people are locked into a ~5mi radius of their home.
How can they possibly contain a conflict in a nation with universal car ownership and the most developed road network in the world? The average car can travel over 400 miles on one tank of gas, how can you contain the potential of that kind of mobility?
I think that's partially why the system was so freaked out by 1/6. Yes, most of it is histrionics but you don't decide to indefinitely turn your capital into the Baghdad Green Zone with fortifications and 25k troops over histrionics alone.
Hey guys, just a friendly reminder. We're watching you. pic.twitter.com/bGwi1uJBwT
— CIA Metadata Analyst with 8 kids (@CiaKids) September 23, 2019
We've seen and struggled in civil conflicts with instant, local, universal, distributed communications (cell phone era, basically every conflict since 2000). We've seen and struggled in conflicts with instant, global, universal distributed communications (everything since 2011).
The world's most overfunded military and glow in the dark agencies struggle and largely fail to contain conflicts where fhe vast, vast majority of people are locked into a ~5mi radius of their home.
How can they possibly contain a conflict in a nation with universal car ownership and the most developed road network in the world? The average car can travel over 400 miles on one tank of gas, how can you contain the potential of that kind of mobility?
I think that's partially why the system was so freaked out by 1/6. Yes, most of it is histrionics but you don't decide to indefinitely turn your capital into the Baghdad Green Zone with fortifications and 25k troops over histrionics alone.
You May Also Like
12 TRADING SETUPS which experts are using.
These setups I found from the following 4 accounts:
1. @Pathik_Trader
2. @sourabhsiso19
3. @ITRADE191
4. @DillikiBiili
Share for the benefit of everyone.
Here are the setups from @Pathik_Trader Sir first.
1. Open Drive (Intraday Setup explained)
Bactesting results of Open Drive
2. Two Price Action setups to get good long side trade for intraday.
1. PDC Acts as Support
2. PDH Acts as
Example of PDC/PDH Setup given
These setups I found from the following 4 accounts:
1. @Pathik_Trader
2. @sourabhsiso19
3. @ITRADE191
4. @DillikiBiili
Share for the benefit of everyone.
Here are the setups from @Pathik_Trader Sir first.
1. Open Drive (Intraday Setup explained)
#OpenDrive#intradaySetup
— Pathik (@Pathik_Trader) April 16, 2019
Sharing one high probability trending setup for intraday.
Few conditions needs to be met
1. Opening should be above/below previous day high/low for buy/sell setup.
2. Open=low (for buy)
Open=high (for sell)
(1/n)
Bactesting results of Open Drive
Already explained strategy of #opendrive
— Pathik (@Pathik_Trader) May 27, 2020
Backtested results in 30 stocks and nifty, banknifty.
Success ratio : approx 40-45%
RR average 1:2
Entry as per strategy
Stoploss = Open level
Exit 3:15 PM Or SL
39 months 14 months -ve, 25 +ve
Yearly all 4 years +ve performance. pic.twitter.com/nGqhzMKGVy
2. Two Price Action setups to get good long side trade for intraday.
1. PDC Acts as Support
2. PDH Acts as
So today we will discuss two more price action setups to get good long side trade for intraday.
— Pathik (@Pathik_Trader) June 20, 2020
1. PDC Acts as Support
2. PDH Acts as Support
Example of PDC/PDH Setup given
#nifty
— Pathik (@Pathik_Trader) June 23, 2020
This is how it created long setup by taking support at PDC.
hopefully shared setup on last weekend helped. pic.twitter.com/2mduSUpMn5






Recently, the @CNIL issued a decision regarding the GDPR compliance of an unknown French adtech company named "Vectaury". It may seem like small fry, but the decision has potential wide-ranging impacts for Google, the IAB framework, and today's adtech. It's thread time! 👇
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.
