
Now, a more technical tweet thread to give updates on the science - which is moving fast. Again, I recommend following @arambaut, @firefoxx66, @EBIgoldman, @The_Soup_Dragon, @pathogenomenick and @jcbarret along with others to stay on the cutting edge of this
MK LHL testing data showing increasing prevalence of H69/V70 variant in positive test data - which is detected incidentally by the commonly used 3-gene PCR test. pic.twitter.com/1U0pVR9Bhs
— Tony Cox (@The_Soup_Dragon) December 19, 2020
More from Science


Hard agree. And if this is useful, let me share something that often gets omitted (not by @kakape).
Variants always emerge, & are not good or bad, but expected. The challenge is figuring out which variants are bad, and that can't be done with sequence alone.
You can't just look at a sequence and say, "Aha! A mutation in spike. This must be more transmissible or can evade antibody neutralization." Sure, we can use computational models to try and predict the functional consequence of a given mutation, but models are often wrong.
The virus acquires mutations randomly every time it replicates. Many mutations don't change the virus at all. Others may change it in a way that have no consequences for human transmission or disease. But you can't tell just looking at sequence alone.
In order to determine the functional impact of a mutation, you need to actually do experiments. You can look at some effects in cell culture, but to address questions relating to transmission or disease, you have to use animal models.
The reason people were concerned initially about B.1.1.7 is because of epidemiological evidence showing that it rapidly became dominant in one area. More rapidly that could be explained unless it had some kind of advantage that allowed it to outcompete other circulating variants.
Variants always emerge, & are not good or bad, but expected. The challenge is figuring out which variants are bad, and that can't be done with sequence alone.
Feels like the next thing we're going to need is a ranking system for how concerning "variants of concern\u201d actually are.
— Kai Kupferschmidt (@kakape) January 15, 2021
A lot of constellations of mutations are concerning, but people are lumping together variants with vastly different levels of evidence that we need to worry.
You can't just look at a sequence and say, "Aha! A mutation in spike. This must be more transmissible or can evade antibody neutralization." Sure, we can use computational models to try and predict the functional consequence of a given mutation, but models are often wrong.
The virus acquires mutations randomly every time it replicates. Many mutations don't change the virus at all. Others may change it in a way that have no consequences for human transmission or disease. But you can't tell just looking at sequence alone.
In order to determine the functional impact of a mutation, you need to actually do experiments. You can look at some effects in cell culture, but to address questions relating to transmission or disease, you have to use animal models.
The reason people were concerned initially about B.1.1.7 is because of epidemiological evidence showing that it rapidly became dominant in one area. More rapidly that could be explained unless it had some kind of advantage that allowed it to outcompete other circulating variants.

1. I find it remarkable that some medics and scientists aren’t raising their voices to make children as safe as possible. The comment about children being less infectious than adults is unsupported by evidence.
2. @c_drosten has talked about this extensively and @dgurdasani1 and @DrZoeHyde have repeatedly pointed out flaws in the studies which have purported to show this. Now for the other assertion: children are very rarely ill with COVID19.
3. Children seem to suffer less with acute illness, but we have no idea of the long-term impact of infection. We do know #LongCovid affects some children. @LongCovidKids now speaks for 1,500 children struggling with a wide range of long-term symptoms.
4. 1,500 children whose parents found a small campaign group. How many more are out there? We don’t know. ONS data suggests there might be many, but the issue hasn’t been studied sufficiently well or long enough for a definitive answer.
5. Some people have talked about #COVID19 being this generation’s Polio. According to US CDC, Polio resulted in inapparent infection in more than 99% of people. Severe disease occurred in a tiny fraction of those infected. Source:
I find it remarkable that a section of society not rejoicing that children very rarely ill with COVID compared to other viruses and much less infectious than adults
— Michael Absoud \U0001f499 (@MAbsoud) February 12, 2021
Instead trying prove the opposite!
Why??
2. @c_drosten has talked about this extensively and @dgurdasani1 and @DrZoeHyde have repeatedly pointed out flaws in the studies which have purported to show this. Now for the other assertion: children are very rarely ill with COVID19.
3. Children seem to suffer less with acute illness, but we have no idea of the long-term impact of infection. We do know #LongCovid affects some children. @LongCovidKids now speaks for 1,500 children struggling with a wide range of long-term symptoms.
4. 1,500 children whose parents found a small campaign group. How many more are out there? We don’t know. ONS data suggests there might be many, but the issue hasn’t been studied sufficiently well or long enough for a definitive answer.
5. Some people have talked about #COVID19 being this generation’s Polio. According to US CDC, Polio resulted in inapparent infection in more than 99% of people. Severe disease occurred in a tiny fraction of those infected. Source:

@mugecevik is an excellent scientist and a responsible professional. She likely read the paper more carefully than most. She grasped some of its strengths and weaknesses that are not apparent from a cursory glance. Below, I will mention a few points some may have missed.
1/
The paper does NOT evaluate the effect of school closures. Instead it conflates all ‘educational settings' into a single category, which includes universities.
2/
The paper primarily evaluates data from March and April 2020. The article is not particularly clear about this limitation, but the information can be found in the hefty supplementary material.
3/

The authors applied four different regression methods (some fancier than others) to the same data. The outcomes of the different regression models are correlated (enough to reach statistical significance), but they vary a lot. (heat map on the right below).
4/
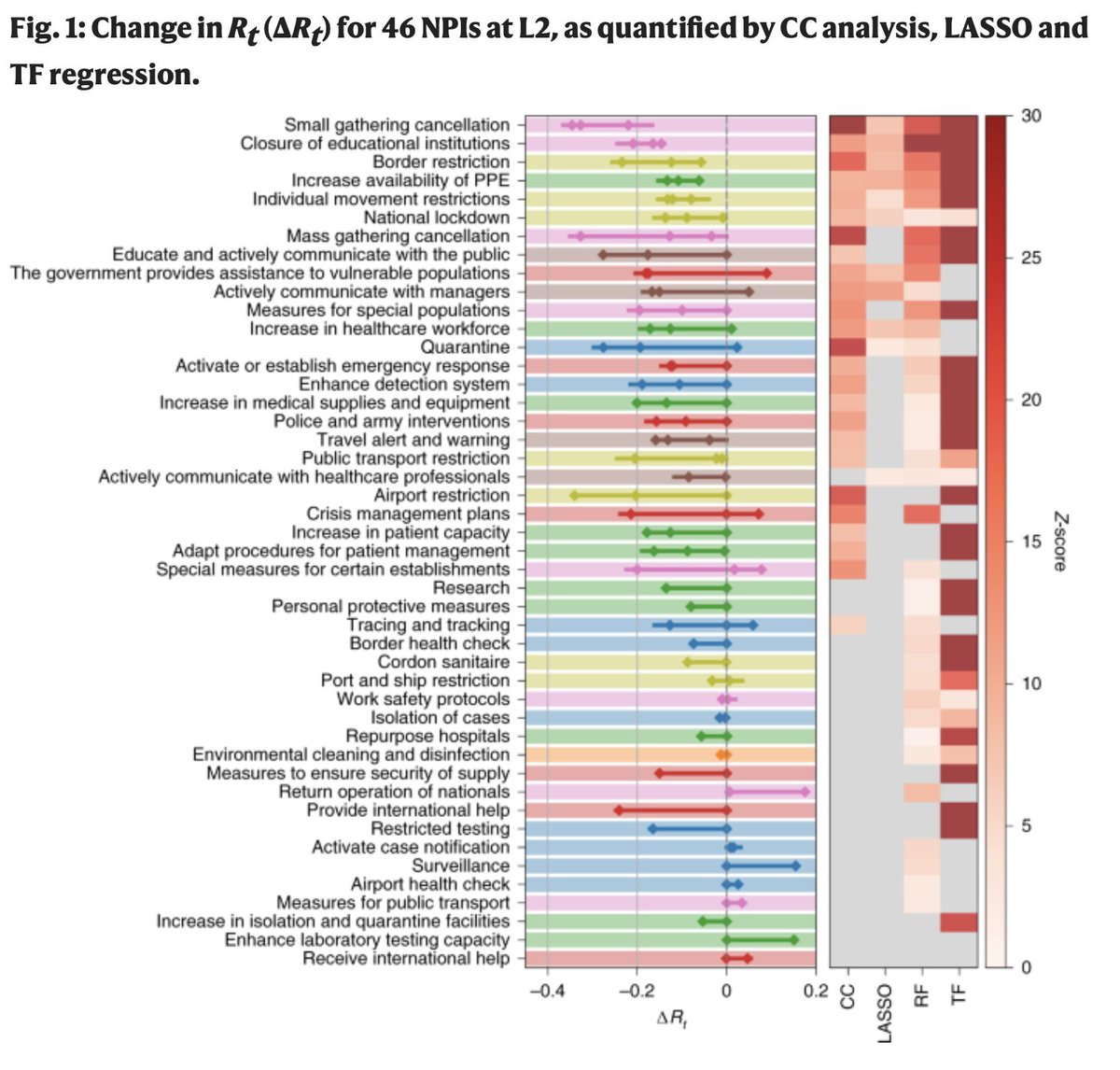
The effect of individual interventions is extremely difficult to disentangle as the authors stress themselves. There is a very large number of interventions considered and the model was run on 49 countries and 26 US States (and not >200 countries).
5/

1/
I've recently come across a disinformation around evidence relating to school closures and community transmission that's been platformed prominently. This arises from flawed understanding of the data that underlies this evidence, and the methodologies used in these studies. pic.twitter.com/VM7cVKghgj
— Deepti Gurdasani (@dgurdasani1) February 1, 2021
The paper does NOT evaluate the effect of school closures. Instead it conflates all ‘educational settings' into a single category, which includes universities.
2/
The paper primarily evaluates data from March and April 2020. The article is not particularly clear about this limitation, but the information can be found in the hefty supplementary material.
3/
The authors applied four different regression methods (some fancier than others) to the same data. The outcomes of the different regression models are correlated (enough to reach statistical significance), but they vary a lot. (heat map on the right below).
4/
The effect of individual interventions is extremely difficult to disentangle as the authors stress themselves. There is a very large number of interventions considered and the model was run on 49 countries and 26 US States (and not >200 countries).
5/

You May Also Like






And here they are...
THE WINNERS OF THE 24 HOUR STARTUP CHALLENGE
Remember, this money is just fun. If you launched a product (or even attempted a launch) - you did something worth MUCH more than $1,000.
#24hrstartup
The winners 👇
#10
Lattes For Change - Skip a latte and save a life.
https://t.co/M75RAirZzs
@frantzfries built a platform where you can see how skipping your morning latte could do for the world.
A great product for a great cause.
Congrats Chris on winning $250!

#9
Instaland - Create amazing landing pages for your followers.
https://t.co/5KkveJTAsy
A team project! @bpmct and @BaileyPumfleet built a tool for social media influencers to create simple "swipe up" landing pages for followers.
Really impressive for 24 hours. Congrats!

#8
SayHenlo - Chat without distractions
https://t.co/og0B7gmkW6
Built by @DaltonEdwards, it's a platform for combatting conversation overload. This product was also coded exclusively from an iPad 😲
Dalton is a beast. I'm so excited he placed in the top 10.

#7
CoderStory - Learn to code from developers across the globe!
https://t.co/86Ay6nF4AY
Built by @jesswallaceuk, the project is focused on highlighting the experience of developers and people learning to code.
I wish this existed when I learned to code! Congrats on $250!!

THE WINNERS OF THE 24 HOUR STARTUP CHALLENGE
Remember, this money is just fun. If you launched a product (or even attempted a launch) - you did something worth MUCH more than $1,000.
#24hrstartup
The winners 👇
#10
Lattes For Change - Skip a latte and save a life.
https://t.co/M75RAirZzs
@frantzfries built a platform where you can see how skipping your morning latte could do for the world.
A great product for a great cause.
Congrats Chris on winning $250!
#9
Instaland - Create amazing landing pages for your followers.
https://t.co/5KkveJTAsy
A team project! @bpmct and @BaileyPumfleet built a tool for social media influencers to create simple "swipe up" landing pages for followers.
Really impressive for 24 hours. Congrats!
#8
SayHenlo - Chat without distractions
https://t.co/og0B7gmkW6
Built by @DaltonEdwards, it's a platform for combatting conversation overload. This product was also coded exclusively from an iPad 😲
Dalton is a beast. I'm so excited he placed in the top 10.
#7
CoderStory - Learn to code from developers across the globe!
https://t.co/86Ay6nF4AY
Built by @jesswallaceuk, the project is focused on highlighting the experience of developers and people learning to code.
I wish this existed when I learned to code! Congrats on $250!!







