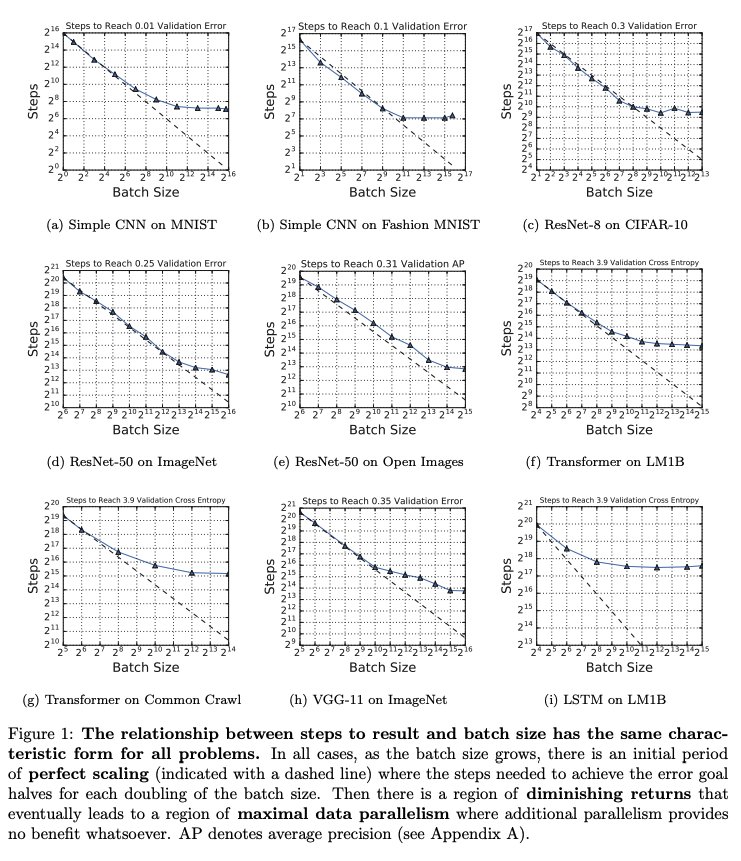
Before starting, remember that, if you follow me, one of your enemies will be immediately destroyed (and you'll get to read more of these threads, of course.)
And if you don't follow me, well, you just hurt my feelings.
😜


SUMMARY: the Oxford/Astra trial examined dosing with gaps between 4-12 wks- although longer gaps appear to be limited mostly to younger participants. There was no difference reported in published data between these & efficacy from the 1st dose seems high for severe disease.
— Deepti Gurdasani (@dgurdasani1) December 31, 2020
Discussions of 1 vs 2 doses suggest many are not aware of Pfizer's trials which evaluated 1 vs 2 dose immunogenicity, assessed multiple formulations (BNT162b1 BNT162b2 etc) & conducted dose-ranging in both young & old adults at the start. Saw "clear benefit of booster at day 21" pic.twitter.com/mpyxu9xFSF
— Dr Nicole E Basta (@IDEpiPhD) December 31, 2020
Bad ballot design led to a lot of undervotes for Bill Nelson in Broward Co., possibly even enough to cost him his Senate seat. They do appear to be real undervotes, though, instead of tabulation errors. He doesn't really seem to have a path to victory. https://t.co/utUhY2KTaR
— Nate Silver (@NateSilver538) November 16, 2018