

With Black History Month in full swing, I was reminded recently of an odd “documentary” (really more of a time capsule piece) that I first watched over a decade ago now.
A thread on Black Power Mixtape.

Obama was still in his first term. We had been sold the notion of a golden age of American racial recompense.
A film pushed through the festival circuit with a clear sentiment of “so far to go” seemed like an activist gaslight. As we have come to learn, the tenor of the conversation was being nudged.












More from All















You May Also Like

Fake chats claiming to be from the Irish African community are being disseminated by the far right in order to suggest that violence is imminent from #BLM supporters. This is straight out of the QAnon and Proud Boys playbook. Spread the word. Protest safely. #georgenkencho

There is co-ordination across the far right in Ireland now to stir both left and right in the hopes of creating a race war. Think critically! Fascists see the tragic killing of #georgenkencho, the grief of his community and pending investigation as a flashpoint for action.
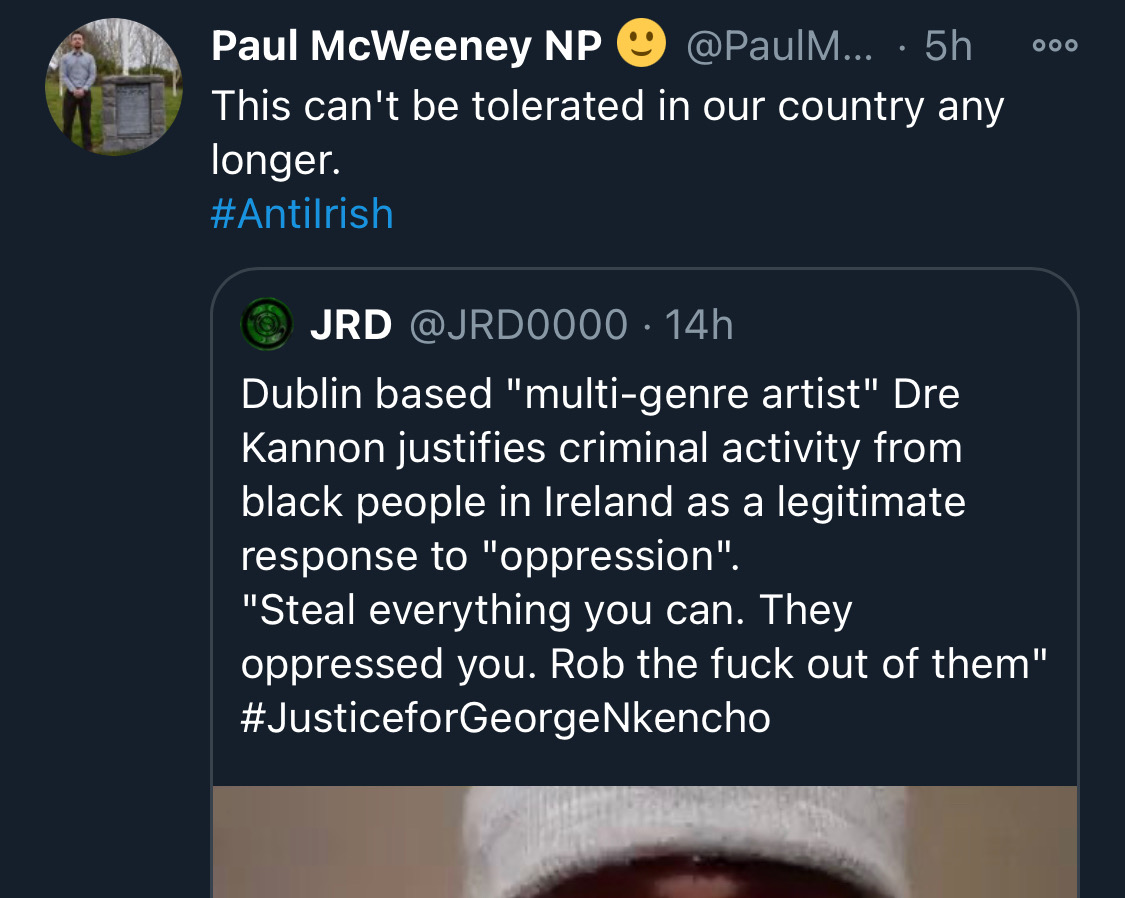
Across Telegram, Twitter and Facebook disinformation is being peddled on the back of these tragic events. From false photographs to the tactics ofwhite supremacy, the far right is clumsily trying to drive hate against minority groups and figureheads.
Declan Ganley’s Burkean group and the incel wing of National Party (Gearóid Murphy, Mick O’Keeffe & Co.) as well as all the usuals are concerted in their efforts to demonstrate their white supremacist cred. The quiet parts are today being said out loud.
The best thing you can do is challenge disinformation and report posts where engagement isn’t appropriate. Many of these are blatantly racist posts designed to drive recruitment to NP and other Nationalist groups. By all means protest but stay safe.
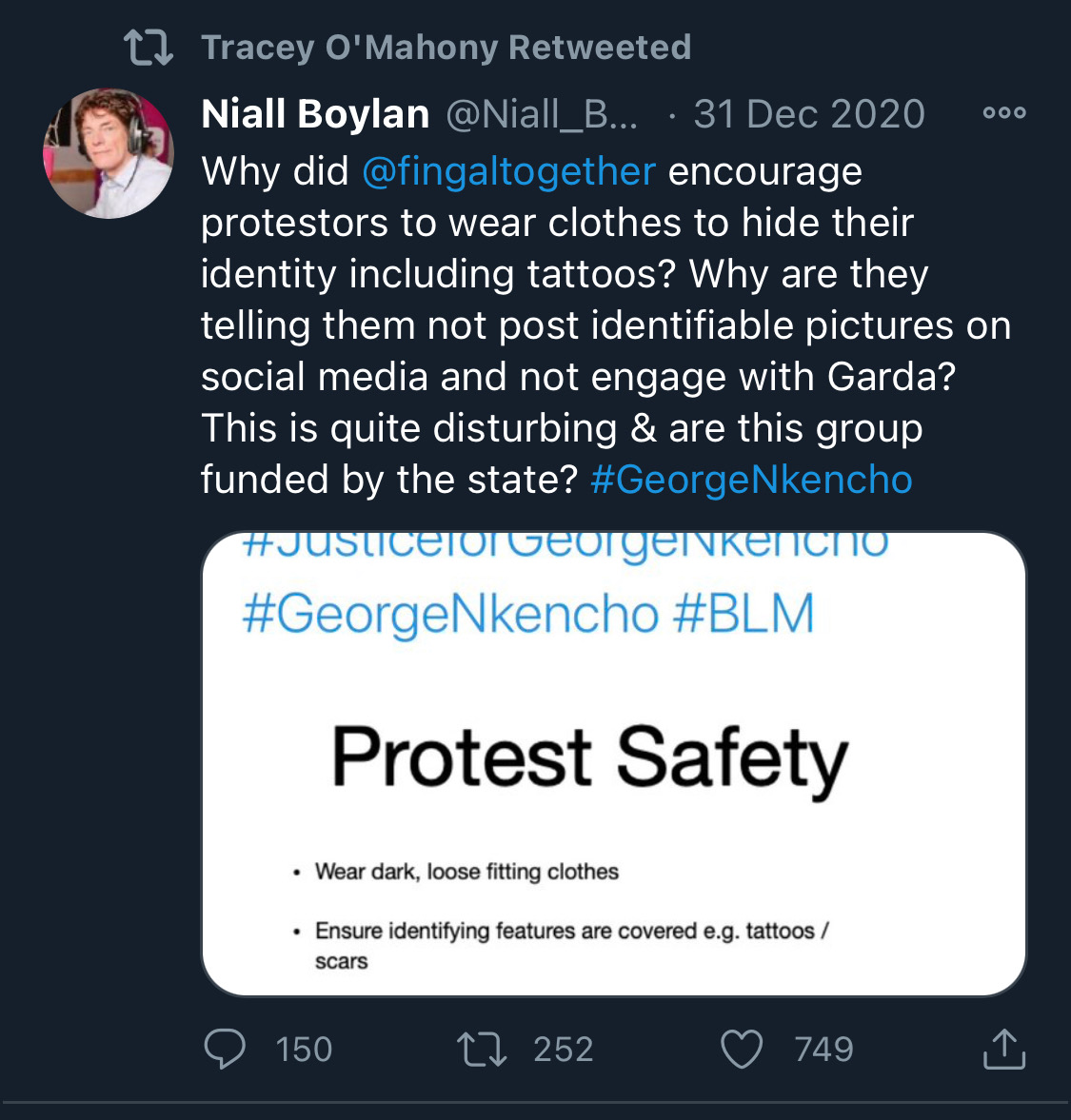
There is co-ordination across the far right in Ireland now to stir both left and right in the hopes of creating a race war. Think critically! Fascists see the tragic killing of #georgenkencho, the grief of his community and pending investigation as a flashpoint for action.
Across Telegram, Twitter and Facebook disinformation is being peddled on the back of these tragic events. From false photographs to the tactics ofwhite supremacy, the far right is clumsily trying to drive hate against minority groups and figureheads.
Be aware, the images the #farright are sharing in the hopes of starting a race war, are not of the SPAR employee that was punched. They\u2019re older photos of a Everton fan. Be aware of the information you\u2019re sharing and that it may be false. Always #factcheck #GeorgeNkencho pic.twitter.com/4c9w4CMk5h
— antifa.drone (@antifa_drone) December 31, 2020
Declan Ganley’s Burkean group and the incel wing of National Party (Gearóid Murphy, Mick O’Keeffe & Co.) as well as all the usuals are concerted in their efforts to demonstrate their white supremacist cred. The quiet parts are today being said out loud.
There is a concerted effort in far-right Telegram groups to try and incite violence on street by targetting people for racist online abuse following the killing of George Nkencho
— Mark Malone (@soundmigration) January 1, 2021
This follows on and is part of a misinformation campaign to polarise communities at this time.
The best thing you can do is challenge disinformation and report posts where engagement isn’t appropriate. Many of these are blatantly racist posts designed to drive recruitment to NP and other Nationalist groups. By all means protest but stay safe.




MDZS is laden with buddhist references. As a South Asian person, and history buff, it is so interesting to see how Buddhism, which originated from India, migrated, flourished & changed in the context of China. Here's some research (🙏🏼 @starkjeon for CN insight + citations)
1. LWJ’s sword Bichen ‘is likely an abbreviation for the term 躲避红尘 (duǒ bì hóng chén), which can be translated as such: 躲避: shunning or hiding away from 红尘 (worldly affairs; which is a buddhist teaching.) (https://t.co/zF65W3roJe) (abbrev. TWX)
2. Sandu (三 毒), Jiang Cheng’s sword, refers to the three poisons (triviṣa) in Buddhism; desire (kāma-taṇhā), delusion (bhava-taṇhā) and hatred (vibhava-taṇhā).
These 3 poisons represent the roots of craving (tanha) and are the cause of Dukkha (suffering, pain) and thus result in rebirth.
Interesting that MXTX used this name for one of the characters who suffers, arguably, the worst of these three emotions.
3. The Qian kun purse “乾坤袋 (qián kūn dài) – can be called “Heaven and Earth” Pouch. In Buddhism, Maitreya (मैत्रेय) owns this to store items. It was believed that there was a mythical space inside the bag that could absorb the world.” (TWX)
1. LWJ’s sword Bichen ‘is likely an abbreviation for the term 躲避红尘 (duǒ bì hóng chén), which can be translated as such: 躲避: shunning or hiding away from 红尘 (worldly affairs; which is a buddhist teaching.) (https://t.co/zF65W3roJe) (abbrev. TWX)
2. Sandu (三 毒), Jiang Cheng’s sword, refers to the three poisons (triviṣa) in Buddhism; desire (kāma-taṇhā), delusion (bhava-taṇhā) and hatred (vibhava-taṇhā).
These 3 poisons represent the roots of craving (tanha) and are the cause of Dukkha (suffering, pain) and thus result in rebirth.
Interesting that MXTX used this name for one of the characters who suffers, arguably, the worst of these three emotions.
3. The Qian kun purse “乾坤袋 (qián kūn dài) – can be called “Heaven and Earth” Pouch. In Buddhism, Maitreya (मैत्रेय) owns this to store items. It was believed that there was a mythical space inside the bag that could absorb the world.” (TWX)