
You breathe. I am so sorry. This helped me when I lost my son, and I hope it can bring you just a respite from the storms ahead. Just breathe.

More from All












You May Also Like

BREAKING: @CommonsCMS @DamianCollins just released previously sealed #Six4Three @Facebook documents:
Some random interesting tidbits:
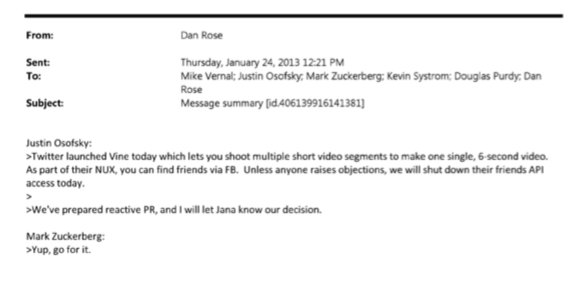
1) Zuck approves shutting down platform API access for Twitter's when Vine is released #competition
2) Facebook engineered ways to access user's call history w/o alerting users:
Team considered access to call history considered 'high PR risk' but 'growth team will charge ahead'. @Facebook created upgrade path to access data w/o subjecting users to Android permissions dialogue.

3) The above also confirms @kashhill and other's suspicion that call history was used to improve PYMK (People You May Know) suggestions and newsfeed rankings.
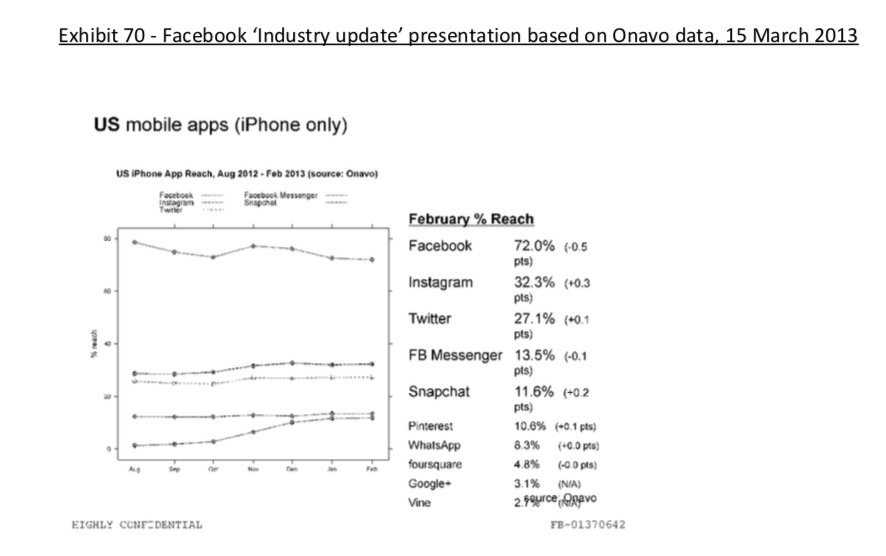
4) Docs also shed more light into @dseetharaman's story on @Facebook monitoring users' @Onavo VPN activity to determine what competitors to mimic or acquire in 2013.
https://t.co/PwiRIL3v9x
Some random interesting tidbits:
1) Zuck approves shutting down platform API access for Twitter's when Vine is released #competition
2) Facebook engineered ways to access user's call history w/o alerting users:
Team considered access to call history considered 'high PR risk' but 'growth team will charge ahead'. @Facebook created upgrade path to access data w/o subjecting users to Android permissions dialogue.
3) The above also confirms @kashhill and other's suspicion that call history was used to improve PYMK (People You May Know) suggestions and newsfeed rankings.
4) Docs also shed more light into @dseetharaman's story on @Facebook monitoring users' @Onavo VPN activity to determine what competitors to mimic or acquire in 2013.
https://t.co/PwiRIL3v9x









