SteveeRogerr Categories Society
7 days
30 days
All time
Recent
Popular












At this point, the countries with most genomic data to analyze spread of the variant virus belonging to https://t.co/ImaHU6Jxdv B.1.1.7 lineage or @nextstrain clade 20I/501Y.V1 are the UK, Denmark and the USA. Here I compare growth rates of B.1.17 across these countries. 1/13
Working from @GISAID data, the UK has 18776 genomes, Denmark has 6089 genomes and the USA has 3093 genomes from specimens collected after Dec 15, 2020. Here, I'm looking at daily genomes with collection dates up to Jan 6 that were not pre-screened by "S dropout". 2/13
For the UK, we can see a steady increase in the frequency of sequenced variant viruses belonging to the B.1.1.7 lineage, reaching ~70% frequency at the end of December. Solid line is a 7 day sliding window average. 3/13
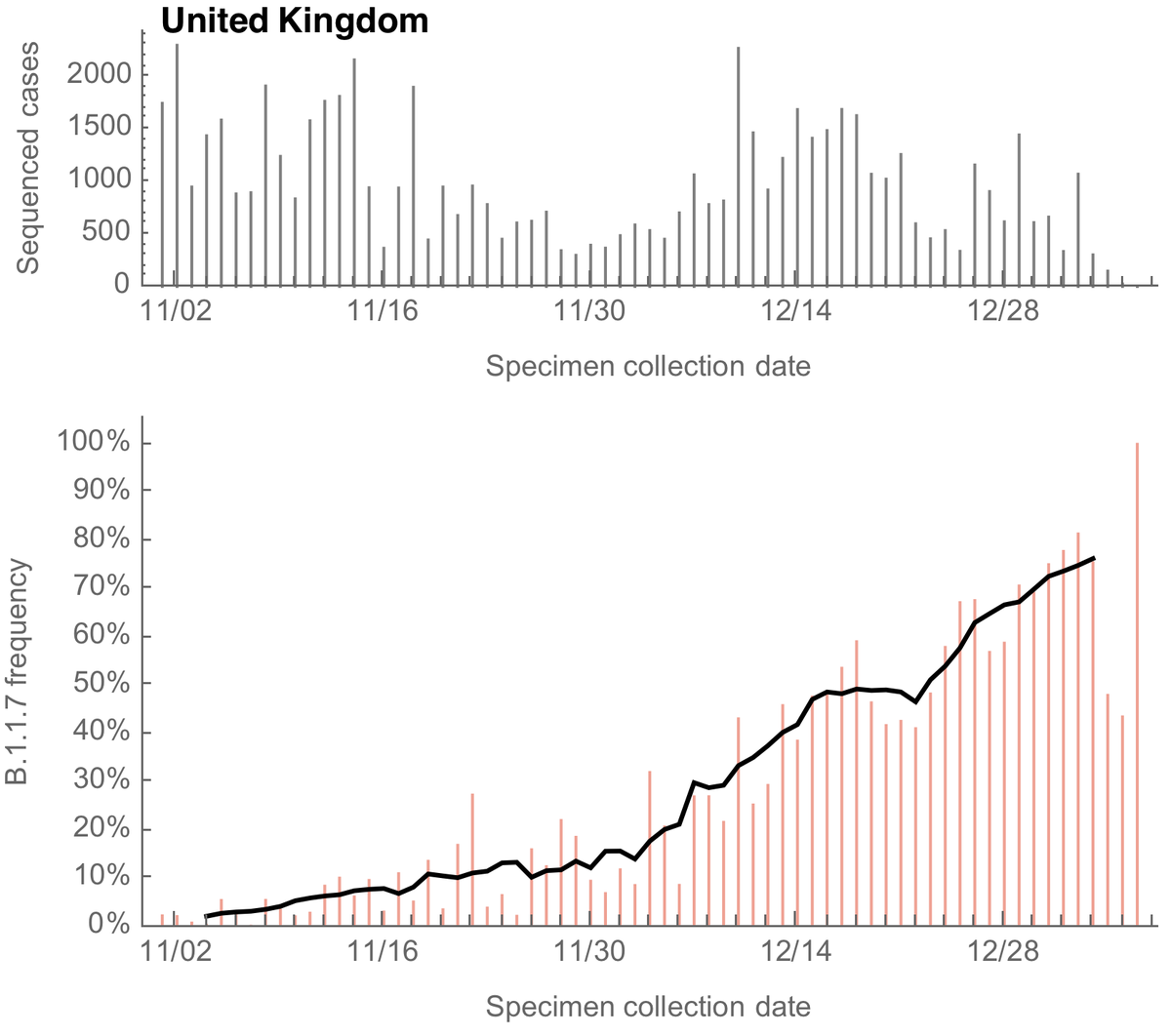
We can fit a logistic growth model to the frequency of B.1.1.7 in the UK data to estimate the rate of frequency increase through time. 4/13
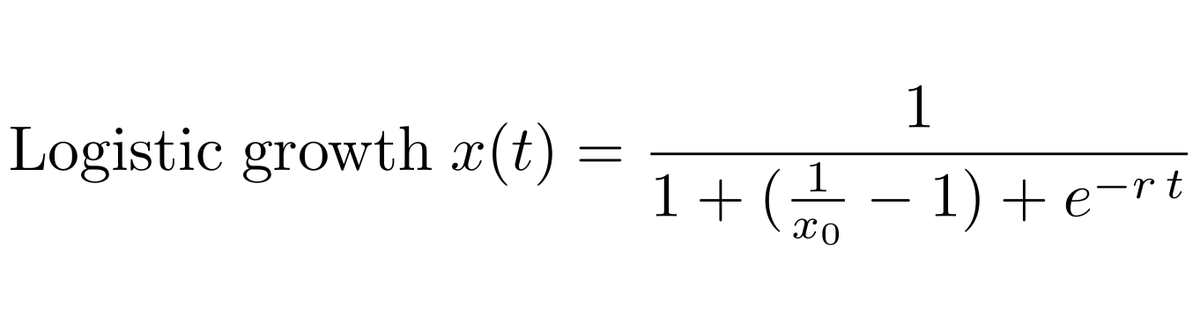
And following @erikmvolz et al (https://t.co/l2ElhJVk8b) we can convert from a measured frequency growth rate to an estimate of increased transmissibility by assuming a particular generation time, which I take to be between 5 days and 6.5 days. 5/13
Working from @GISAID data, the UK has 18776 genomes, Denmark has 6089 genomes and the USA has 3093 genomes from specimens collected after Dec 15, 2020. Here, I'm looking at daily genomes with collection dates up to Jan 6 that were not pre-screened by "S dropout". 2/13
For the UK, we can see a steady increase in the frequency of sequenced variant viruses belonging to the B.1.1.7 lineage, reaching ~70% frequency at the end of December. Solid line is a 7 day sliding window average. 3/13
We can fit a logistic growth model to the frequency of B.1.1.7 in the UK data to estimate the rate of frequency increase through time. 4/13
And following @erikmvolz et al (https://t.co/l2ElhJVk8b) we can convert from a measured frequency growth rate to an estimate of increased transmissibility by assuming a particular generation time, which I take to be between 5 days and 6.5 days. 5/13









A little venting: How do you get nutrition journalists to do their job? I spoke to @TamarHaspel 2 months ago. I suggested she interview MDs who prescribe LCHF/keto diets to their patients, to understand the passion, and ob experts who now buy into the carb/insulin/keto logic.
She had my book, The Case for Keto, which cited over 120+ MDs and she had the endorsements from leading researchers (attached). But none appear in this article. Just @whsource, a blogger, and @KevinH_PhD, and @GardnerPhD.
Claude Rains would call them "the usual suspects."

At the time, @TamarHaspel told me she didn't have time to do that kind of journalistic research: i.e., her job. Is that too much to ask?
Considering the exploding prevalence of ob and db, the public health crisis, can we get journalists to work a little harder asking why?
Finally, why is this so hard to understand?
Re "nothing can defeat the caloric balance equation," @tamarhaspel says "To lose weight you have to burn more calories than you absorb."
NO, IF you are losing weight, THEN you are burning more calories than you absorb.

The energy balance equation says the two things are equivalent--THAT'S WHY THERE'S AN EQUAL SIGN (=) BETWEEN THEM.
It doesn't say one causes the other. It says they are equivalent.
That's the tautology. That's the laws of physics.
Is keto better than other diets for weight loss?
— Tamar Haspel (@TamarHaspel) January 21, 2021
A brand new study by @KevinH_PhD sheds some light.
With comment from @garytaubes @whsource @GardnerPhD.https://t.co/eyB8G0MN3c
She had my book, The Case for Keto, which cited over 120+ MDs and she had the endorsements from leading researchers (attached). But none appear in this article. Just @whsource, a blogger, and @KevinH_PhD, and @GardnerPhD.
Claude Rains would call them "the usual suspects."
At the time, @TamarHaspel told me she didn't have time to do that kind of journalistic research: i.e., her job. Is that too much to ask?
Considering the exploding prevalence of ob and db, the public health crisis, can we get journalists to work a little harder asking why?
Finally, why is this so hard to understand?
Re "nothing can defeat the caloric balance equation," @tamarhaspel says "To lose weight you have to burn more calories than you absorb."
NO, IF you are losing weight, THEN you are burning more calories than you absorb.
The energy balance equation says the two things are equivalent--THAT'S WHY THERE'S AN EQUAL SIGN (=) BETWEEN THEM.
It doesn't say one causes the other. It says they are equivalent.
That's the tautology. That's the laws of physics.



I have distracted myself this week with the extraordinarily mundane task of designing a sample identifier scheme. I want to share some decisions I made in the hope that it saves somebody else some time.
The first choice was the alphabet. I wanted to use human friendly, familiar ASCII characters, but intentionally leave out potentially confusing characters. I'd previously read about "Crockford's base32" (https://t.co/xa3WREc1RQ) which tries to address this problem.
But my search led me instead to z-base32 (https://t.co/5PlTgAgyDU). The z-base32 alphabet is shuffled to try and make encoded identifiers easier to discern. I don't actually need the encoding, but I liked the idea that this shuffle makes sequential identifiers less sequential.
z-base32 takes the interesting choice of using the letters in lowercase to help identifiers form "coastlines" that aid with human recognition. The lab quickly fed back they didn't like this, so I force the alphabet back to uppercase.
With the alphabet decided, I wanted to pick a checking scheme. I learned that each algorithm catches different types of errors, so one needs some knowledge of how the identifiers will be used when making a decision.
The first choice was the alphabet. I wanted to use human friendly, familiar ASCII characters, but intentionally leave out potentially confusing characters. I'd previously read about "Crockford's base32" (https://t.co/xa3WREc1RQ) which tries to address this problem.
But my search led me instead to z-base32 (https://t.co/5PlTgAgyDU). The z-base32 alphabet is shuffled to try and make encoded identifiers easier to discern. I don't actually need the encoding, but I liked the idea that this shuffle makes sequential identifiers less sequential.
z-base32 takes the interesting choice of using the letters in lowercase to help identifiers form "coastlines" that aid with human recognition. The lab quickly fed back they didn't like this, so I force the alphabet back to uppercase.
With the alphabet decided, I wanted to pick a checking scheme. I learned that each algorithm catches different types of errors, so one needs some knowledge of how the identifiers will be used when making a decision.
