"Attention is all you need" implementation from scratch in PyTorch. A Twitter thread:
1/
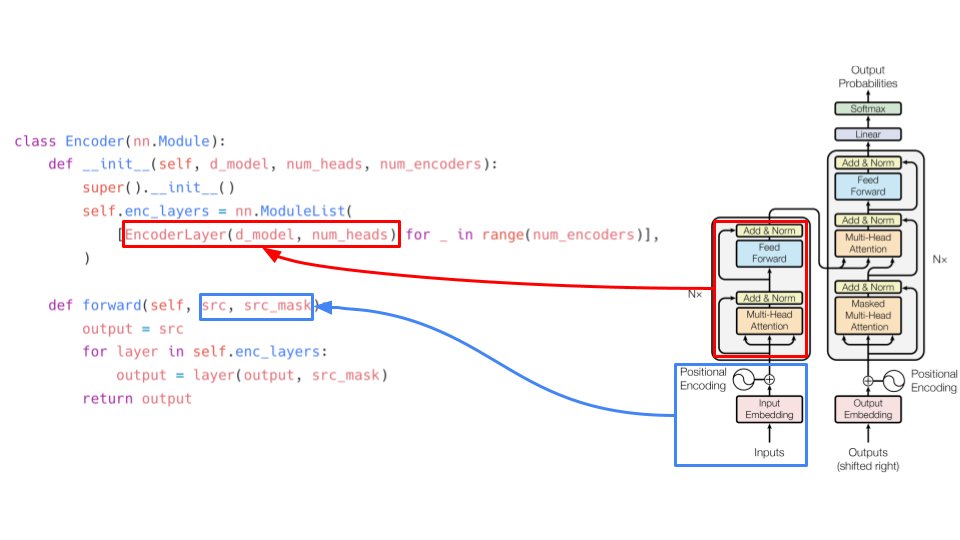
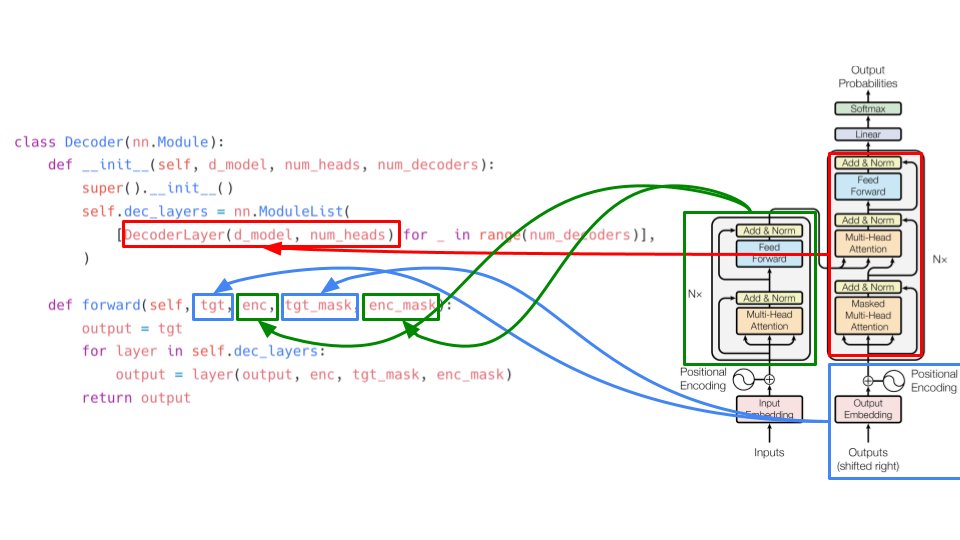
There are two parts: encoder and decoder. Encoder takes source embeddings and source mask as inputs and decoder takes target embeddings and target mask. Decoder inputs are shifted right. What does shifted right mean? Keep reading the thread. 2/
The encoder is composed of N encoder layers. Let's implement this as a black box too. The output of one encoder goes as input to the next encoder and so on. The source mask remains the same till the end 3/
Similarly, we have the decoder composed of decoder layers. The decoder takes input from the last encoder layer and the target embeddings and target mask. enc_mask is the same as src_mask as explained previously 4/
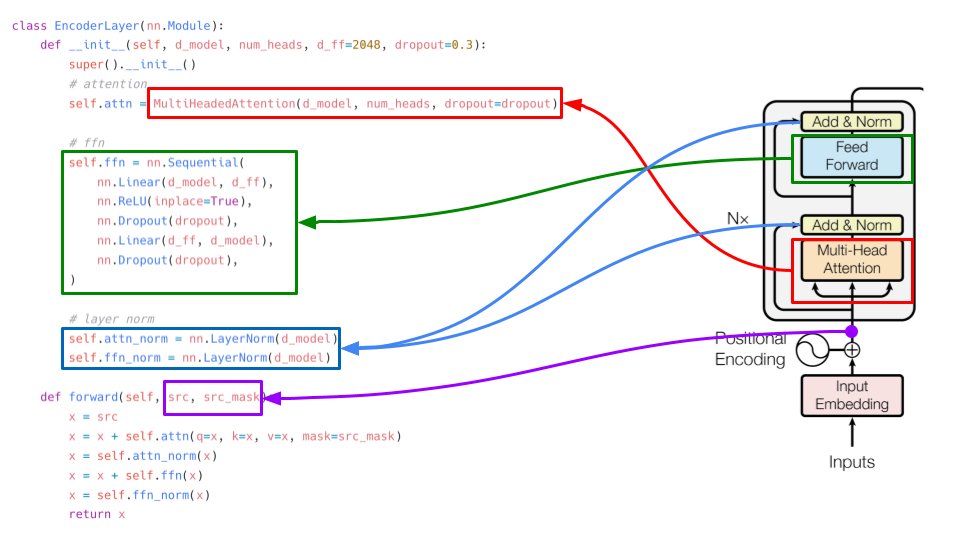
Let's take a look at the encoder layer. It consists of multi-headed attention, a feed forward network and two layer normalization layers. See forward(...) function to understand how skip-connection works. Its just adding original inputs to the outputs. 5/