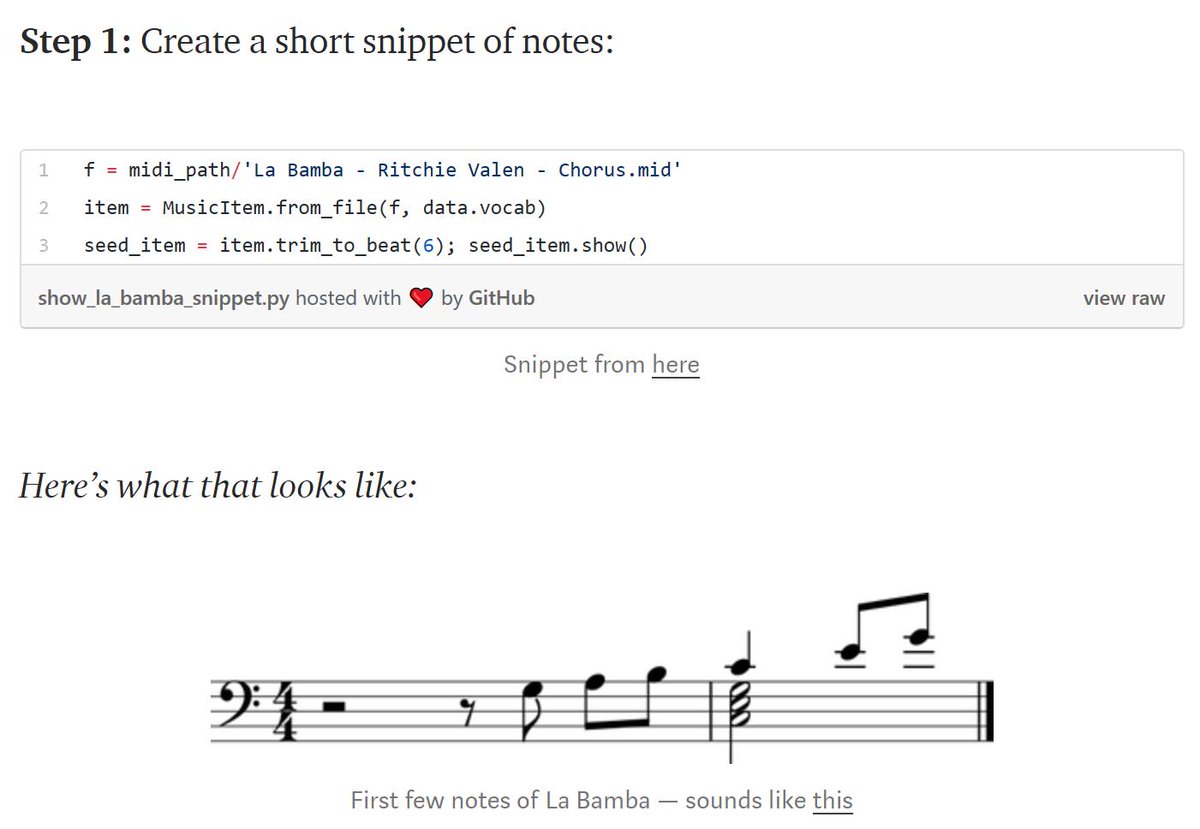
Tired of word clouds? Want to do better sentiment analysis? Not sure how to look at the words underneath your measures?
Our long overdue paper on generalized word shift graphs is finally here!
https://t.co/lIBXvbMJWX
https://t.co/vSL1REYT8V
So what are they?
1/n
If we have two texts, there are many ways we can compare them. Weighted averages are a particularly useful measure because they're flexible and interpretable
Proportions, Shannon entropy, the KLD, the JSD, and dictionary methods can all be written as weighted averages
2/n
But weighted avgs are also slippery. When we try to compress complex phenomena like happiness, surprise, divergence, or diversity into a single number, it can be unclear what we're measuring
If the measure goes up, what does that mean? Why did it do that? Can we trust it?
3/n
Very often, that's the end of the line and we're left with an uneasy feeling in the pit of our stomach that our weighted avg is actually picking up a data artifact or some other unintended peculiarity
Word shift graphs help us address those concerns
4/n
First, word shifts look under the hood of weighted averages to see what's going on
All weighted averages are a sum of contributions from individual words. We can pull out those words, and rank which ones contribute the most to the difference between two texts
5/n