
1/ A ∞-wide NN of *any architecture* is a Gaussian process (GP) at init. The NN in fact evolves linearly in function space under SGD, so is a GP at *any time* during training. https://t.co/v1b6kndqCk With Tensor Programs, we can calculate this time-evolving GP w/o trainin any NN
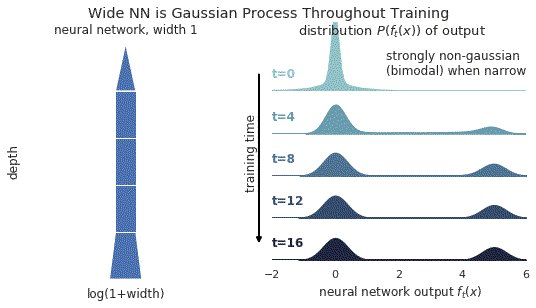
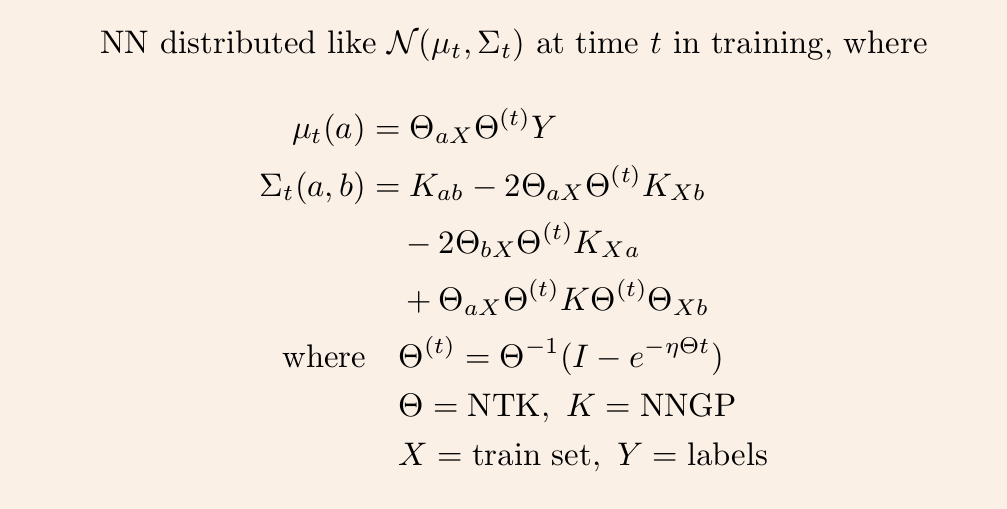
https://t.co/6RO7VZDQNZ
https://t.co/OOoOMdPOsR
More from Data science














You May Also Like











So it's now October 10, 2018 and....Rod Rosenstein is STILL not fired.
He's STILL in charge of the Mueller investigation.
He's STILL refusing to hand over the McCabe memos.
He's STILL holding up the declassification of the #SpyGate documents & their release to the public.
I love a good cover story.......
The guy had a face-to-face with El Grande Trumpo himself on Air Force One just 2 days ago. Inside just about the most secure SCIF in the world.
And Trump came out of AF1 and gave ol' Rod a big thumbs up!
And so we're right back to 'that dirty rat Rosenstein!' 2 days later.
At this point it's clear some members of Congress are either in on this and helping the cover story or they haven't got a clue and are out in the cold.
Note the conflicting stories about 'Rosenstein cancelled meeting with Congress on Oct 11!"
First, rumors surfaced of a scheduled meeting on Oct. 11 between Rosenstein & members of Congress, and Rosenstein just cancelled it.
He's STILL in charge of the Mueller investigation.
He's STILL refusing to hand over the McCabe memos.
He's STILL holding up the declassification of the #SpyGate documents & their release to the public.
I love a good cover story.......
The guy had a face-to-face with El Grande Trumpo himself on Air Force One just 2 days ago. Inside just about the most secure SCIF in the world.
And Trump came out of AF1 and gave ol' Rod a big thumbs up!
And so we're right back to 'that dirty rat Rosenstein!' 2 days later.
At this point it's clear some members of Congress are either in on this and helping the cover story or they haven't got a clue and are out in the cold.
Note the conflicting stories about 'Rosenstein cancelled meeting with Congress on Oct 11!"
First, rumors surfaced of a scheduled meeting on Oct. 11 between Rosenstein & members of Congress, and Rosenstein just cancelled it.
Rep. Andy Biggs and Rep. Matt Gaetz say DAG Rod Rosenstein cancelled an Oct. 11 appearance before the judiciary and oversight committees. They are now calling for a subpoena. pic.twitter.com/TknVHKjXtd
— Ivan Pentchoukov \U0001f1fa\U0001f1f8 (@IvanPentchoukov) October 10, 2018


