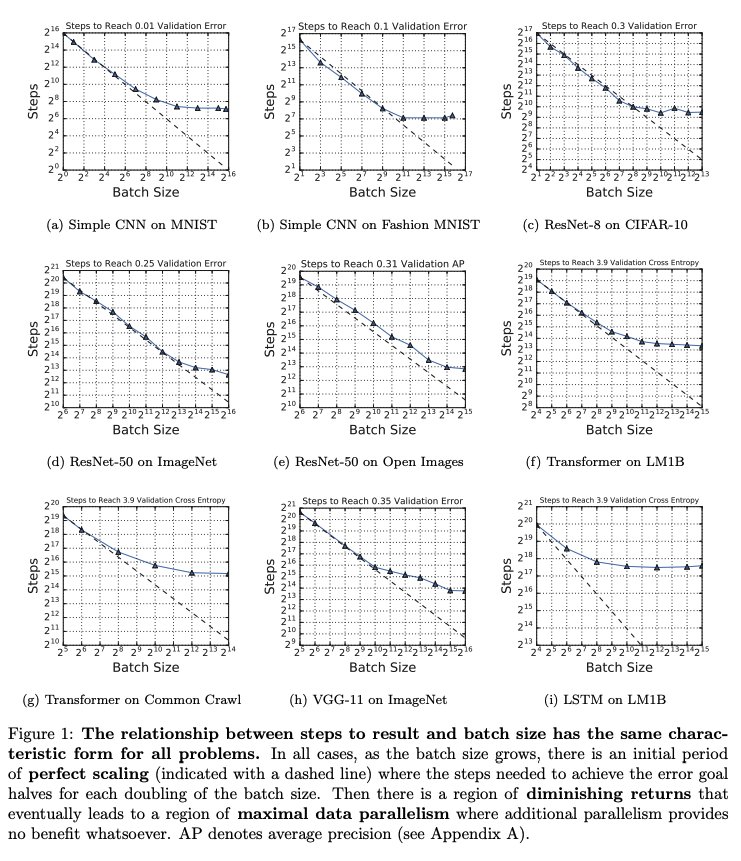
Important paper from Google on large batch optimization. They do impressively careful experiments measuring # iterations needed to achieve target validation error at various batch sizes. The main "surprise" is the lack of surprises. [thread]
https://t.co/7QIx5CFdfJ
The paper is a good example of lots of elements of good experimental design. They validate their metric by showing lots of variants give consistent results. They tune hyperparamters separately for each condition, check that optimum isn't at the endpoints, and measure sensitivity.
They have separate experiments where the hold fixed # iterations and # epochs, which (as they explain) measure very different things. They avoid confounds, such as batch norm's artificial dependence between batch size and regularization strength.
When the experiments are done carefully enough, the results are remarkably consistent between different datasets and architectures. Qualitatively, MNIST behaves just like ImageNet.
Importantly, they don't find any evidence for a "sharp/flat optima" effect whereby better optimization leads to worse final results. They have a good discussion of experimental artifacts/confounds in past papers where such effects were reported.