We’ve recently seen research about so-called “bots” and misinformation on Twitter and wanted to share our perspective on why findings that might seem remarkable at first are likely inaccurate. We’re working on a more detailed explanation, but some comments for now.
Activity that attempts to manipulate or disrupt Twitter\u2019s service is not allowed. We remove this when we see it.
— Twitter Safety (@TwitterSafety) October 31, 2018
You can now specify what type of spam you're seeing when you report, including fake accounts. pic.twitter.com/GN9NKw2Qyn
More from Tech


BREAKING: @CommonsCMS @DamianCollins just released previously sealed #Six4Three @Facebook documents:
Some random interesting tidbits:
1) Zuck approves shutting down platform API access for Twitter's when Vine is released #competition
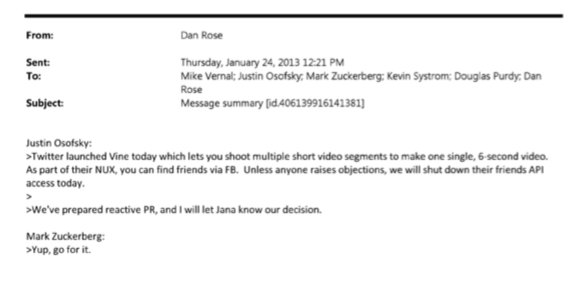
2) Facebook engineered ways to access user's call history w/o alerting users:
Team considered access to call history considered 'high PR risk' but 'growth team will charge ahead'. @Facebook created upgrade path to access data w/o subjecting users to Android permissions dialogue.

3) The above also confirms @kashhill and other's suspicion that call history was used to improve PYMK (People You May Know) suggestions and newsfeed rankings.
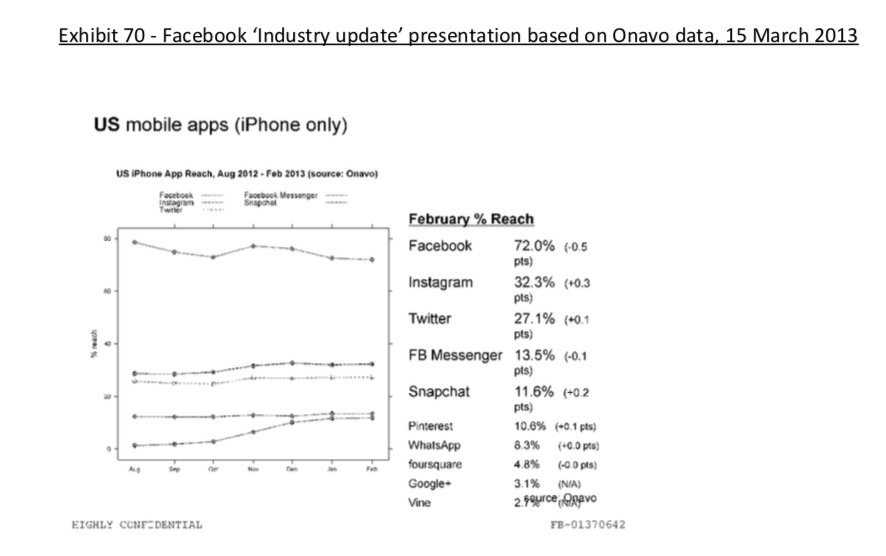
4) Docs also shed more light into @dseetharaman's story on @Facebook monitoring users' @Onavo VPN activity to determine what competitors to mimic or acquire in 2013.
https://t.co/PwiRIL3v9x
Some random interesting tidbits:
1) Zuck approves shutting down platform API access for Twitter's when Vine is released #competition
2) Facebook engineered ways to access user's call history w/o alerting users:
Team considered access to call history considered 'high PR risk' but 'growth team will charge ahead'. @Facebook created upgrade path to access data w/o subjecting users to Android permissions dialogue.
3) The above also confirms @kashhill and other's suspicion that call history was used to improve PYMK (People You May Know) suggestions and newsfeed rankings.
4) Docs also shed more light into @dseetharaman's story on @Facebook monitoring users' @Onavo VPN activity to determine what competitors to mimic or acquire in 2013.
https://t.co/PwiRIL3v9x

The YouTube algorithm that I helped build in 2011 still recommends the flat earth theory by the *hundreds of millions*. This investigation by @RawStory shows some of the real-life consequences of this badly designed AI.
This spring at SxSW, @SusanWojcicki promised "Wikipedia snippets" on debated videos. But they didn't put them on flat earth videos, and instead @YouTube is promoting merchandising such as "NASA lies - Never Trust a Snake". 2/

A few example of flat earth videos that were promoted by YouTube #today:
https://t.co/TumQiX2tlj 3/
https://t.co/uAORIJ5BYX 4/
https://t.co/yOGZ0pLfHG 5/
Flat Earth conference attendees explain how they have been brainwashed by YouTube and Infowarshttps://t.co/gqZwGXPOoc
— Raw Story (@RawStory) November 18, 2018
This spring at SxSW, @SusanWojcicki promised "Wikipedia snippets" on debated videos. But they didn't put them on flat earth videos, and instead @YouTube is promoting merchandising such as "NASA lies - Never Trust a Snake". 2/
A few example of flat earth videos that were promoted by YouTube #today:
https://t.co/TumQiX2tlj 3/
https://t.co/uAORIJ5BYX 4/
https://t.co/yOGZ0pLfHG 5/