Alex1Powell Categories Tech
7 days
30 days
All time
Recent
Popular


They sure will. Here's a quick analysis of how, from my perspective as someone who studies societal impacts of natural language technology:
First, some guesses about system components, based on current tech: it will include a very large language model (akin to GPT-3) trained on huge amounts of web text, including Reddit and the like.
It will also likely be trained on sample input/output pairs, where they asked crowdworkers to create the bulleted summaries for news articles.
The system will be some sort of encoder-decoder that "reads" the news article and then uses its resulting internal state to output bullet points. Likely no controls to make sure the bullet points are each grounded in specific statements in the article.
(This is sometimes called "abstractive" summarization, as opposed to "extractive", which has to use substrings of the article. Maybe they're doing the latter, but based on what the research world is all excited about right now, I'm guessing the former.)
I have no idea how, but these will end up being racist https://t.co/pjZN0WXnnE
— Michael Hobbes (@RottenInDenmark) December 16, 2020
First, some guesses about system components, based on current tech: it will include a very large language model (akin to GPT-3) trained on huge amounts of web text, including Reddit and the like.
It will also likely be trained on sample input/output pairs, where they asked crowdworkers to create the bulleted summaries for news articles.
The system will be some sort of encoder-decoder that "reads" the news article and then uses its resulting internal state to output bullet points. Likely no controls to make sure the bullet points are each grounded in specific statements in the article.
(This is sometimes called "abstractive" summarization, as opposed to "extractive", which has to use substrings of the article. Maybe they're doing the latter, but based on what the research world is all excited about right now, I'm guessing the former.)

Because our feed has been blowing up about the injustice of Zebras Unite (uh, that's us) being erased from this article about...uh, us in @TechCrunch we are going to do a thread about what we know and how this happened. tl;dr: Follow the money. https://t.co/f4CaGJwN8n
First off: hello! @marazepeda here. I used to be an economic reporter for places like @planetmoney & @Marketplace. (If credentials are your kink I even graduated at the top of my class from @columbiajourn 🎉) Follow along, friends, as we attempt to unravel this rat's nest.
We get this message: "Uh, WTF there is an article about Zebras without mentioning Zebras." This happens more often than you might think. (What's the best is when men tweak your ideas and then put another name on it like camel and publish in @HarvardBiz)
As a refresher @operaqueenie @JenniferBrandel @operaqueenie + @marazepeda coined the term in this essay written in, ahem, 2017 https://t.co/ipWzgPxfg1 You can see why the @TechCrunch article by @beckshoneyman sounded...familiar but what was really weird is
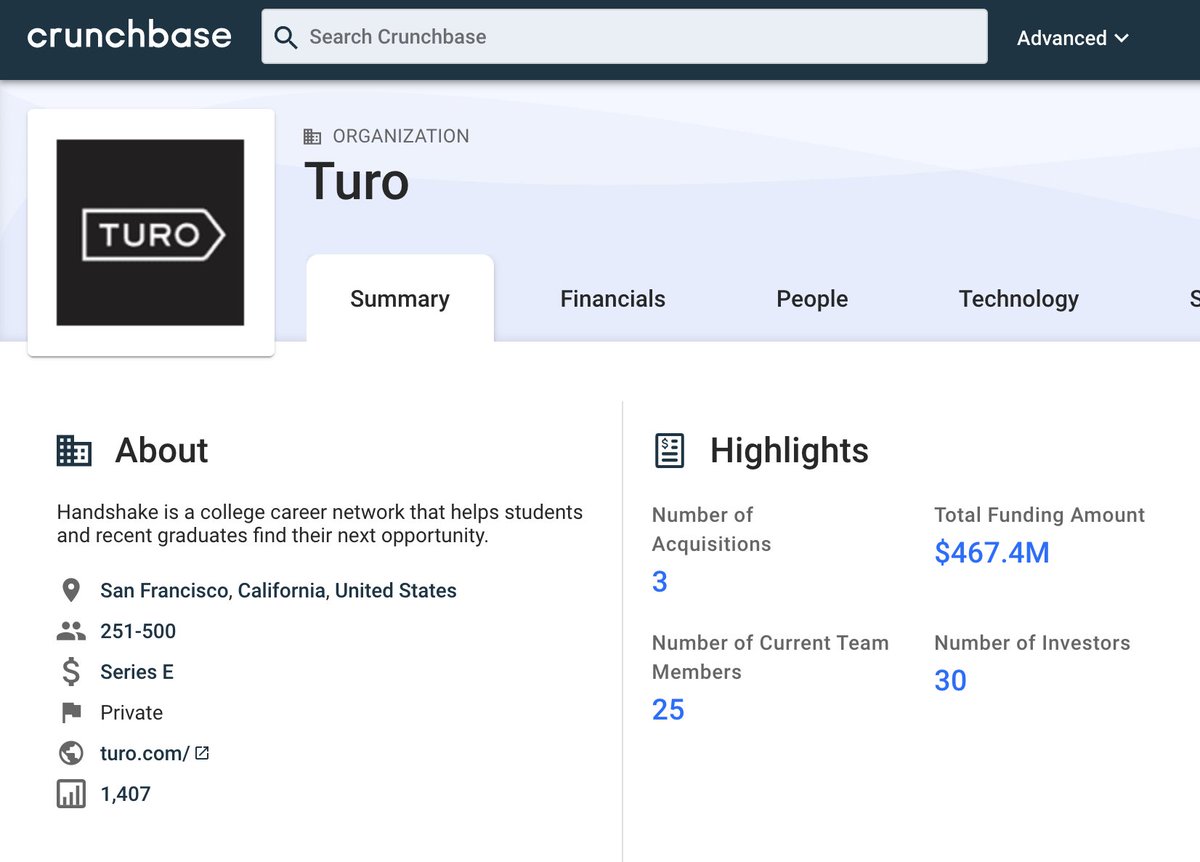
The examples @beckshoneyman cited of so called Zebra companies? @joinHandshake and @turo? Uh no. Handshake has raised $150M and Turo has raised $450M. These are squarely in the #VC funded 🦄 camp. AS THEY SHOULD BE! No shade to VC! You do you! However...
First off: hello! @marazepeda here. I used to be an economic reporter for places like @planetmoney & @Marketplace. (If credentials are your kink I even graduated at the top of my class from @columbiajourn 🎉) Follow along, friends, as we attempt to unravel this rat's nest.
We get this message: "Uh, WTF there is an article about Zebras without mentioning Zebras." This happens more often than you might think. (What's the best is when men tweak your ideas and then put another name on it like camel and publish in @HarvardBiz)
As a refresher @operaqueenie @JenniferBrandel @operaqueenie + @marazepeda coined the term in this essay written in, ahem, 2017 https://t.co/ipWzgPxfg1 You can see why the @TechCrunch article by @beckshoneyman sounded...familiar but what was really weird is
The examples @beckshoneyman cited of so called Zebra companies? @joinHandshake and @turo? Uh no. Handshake has raised $150M and Turo has raised $450M. These are squarely in the #VC funded 🦄 camp. AS THEY SHOULD BE! No shade to VC! You do you! However...