
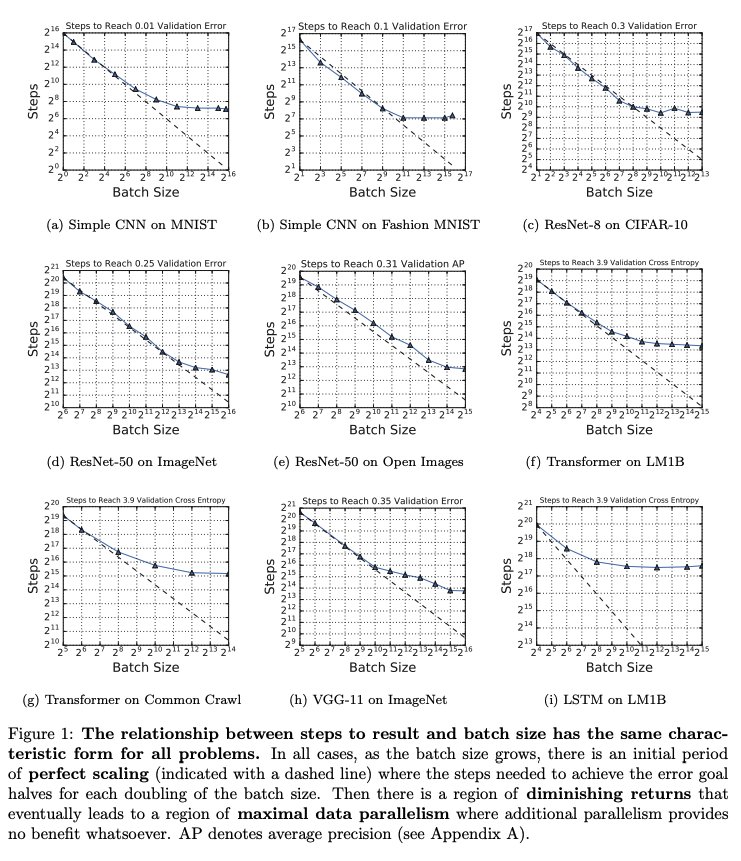
Important paper from Google on large batch optimization. They do impressively careful experiments measuring # iterations needed to achieve target validation error at various batch sizes. The main "surprise" is the lack of surprises. [thread]
https://t.co/7QIx5CFdfJ
More from Machine learning








You May Also Like



The first area to focus on is diversity. This has become a dogma in the tech world, and despite the fact that tech is one of the most meritocratic industries in the world, there are constant efforts to promote diversity at the expense of fairness, merit and competency. Examples:
USC's Interactive Media & Games Division cancels all-star panel that included top-tier game developers who were invited to share their experiences with students. Why? Because there were no women on the
ElectronConf is a conf which chooses presenters based on blind auditions; the identity, gender, and race of the speaker is not known to the selection team. The results of that merit-based approach was an all-male panel. So they cancelled the conference.
Apple's head of diversity (a black woman) got in trouble for promoting a vision of diversity that is at odds with contemporary progressive dogma. (She left the company shortly after this
Also in the name of diversity, there is unabashed discrimination against men (especially white men) in tech, in both hiring policies and in other arenas. One such example is this, a developer workshop that specifically excluded men: https://t.co/N0SkH4hR35

USC's Interactive Media & Games Division cancels all-star panel that included top-tier game developers who were invited to share their experiences with students. Why? Because there were no women on the
ElectronConf is a conf which chooses presenters based on blind auditions; the identity, gender, and race of the speaker is not known to the selection team. The results of that merit-based approach was an all-male panel. So they cancelled the conference.
Apple's head of diversity (a black woman) got in trouble for promoting a vision of diversity that is at odds with contemporary progressive dogma. (She left the company shortly after this
Also in the name of diversity, there is unabashed discrimination against men (especially white men) in tech, in both hiring policies and in other arenas. One such example is this, a developer workshop that specifically excluded men: https://t.co/N0SkH4hR35

Took me 5 years to get the best Chartink scanners for Stock Market, but you’ll get it in 5 mminutes here ⏰
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times




