

Last up in Privacy Tech for #enigma2021, @xchatty speaking about "IMPLEMENTING DIFFERENTIAL PRIVACY FOR THE 2020
* Data users expect consistent data releases
* Some people call synthetic data "fake data" like
"fake news"
* It's not clear what "quality assurance" and "data exploration" means in a DP framework

* required to collect it by the constitution
* but required to maintain privacy by law
* differential privacy is open and we can talk about privacy loss/accuracy tradeoff
* swapping assumed limitations of the attackers (e.g. limited computational power)
Change in the meaning of "privacy" as relative -- it requires a lot of explanation and overcoming organizational barriers.
* different groups at the Census thought that meant different things
* before, states were processed as they came in. Differential privacy requires everything be computed on at once
* required a lot more computing power
* initial implementation was by Dan Kiefer, who took a sabbatical
* expanded team to with Simson and others
* 2018 end to end test
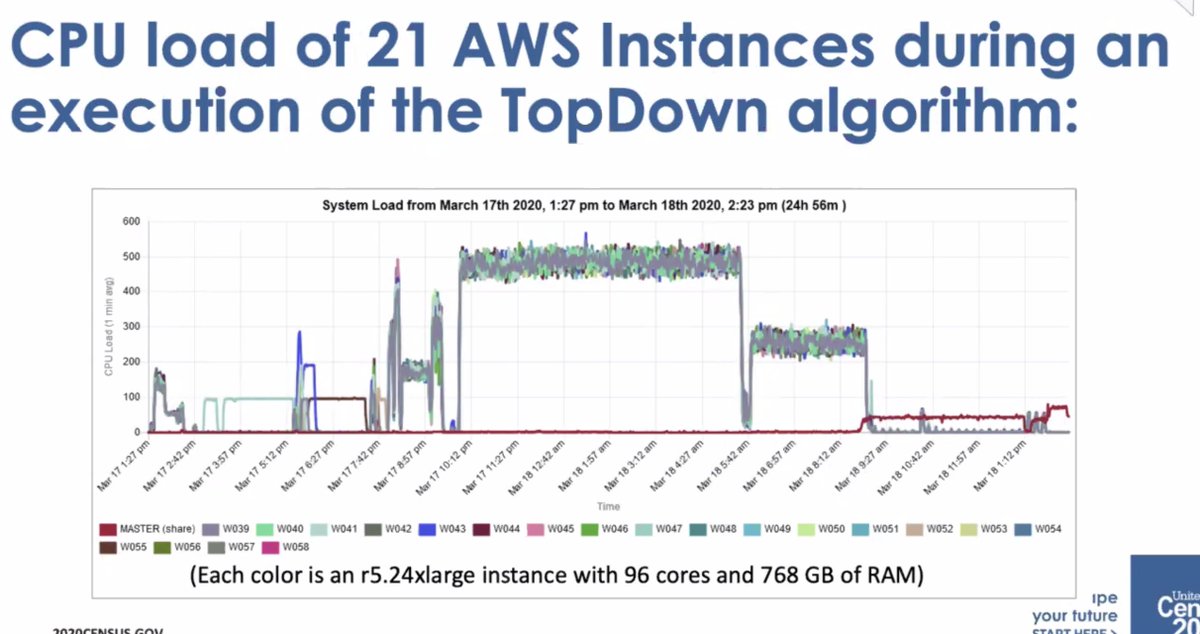
* then got to move to AWS Elastic compute... but the monitoring wasn't good enough and had to create their own dashboard to track execution
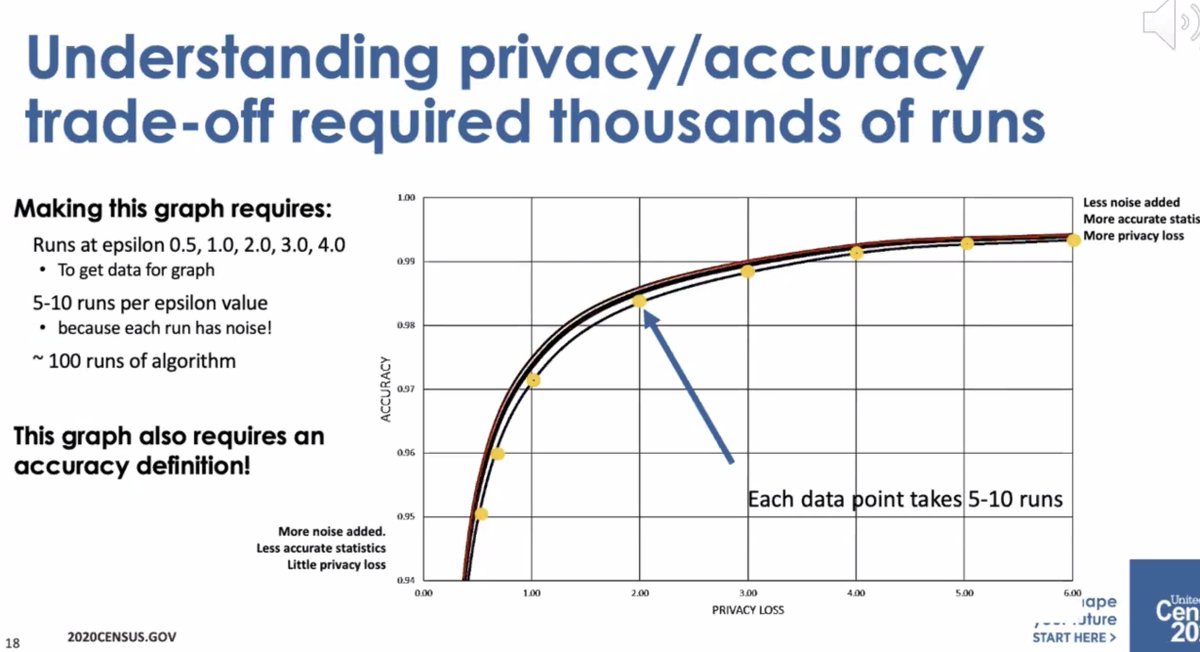
* it wasn't a small amount of compute
* ... it wasn't well-received by the data users who thought there was too much error
If you avoid that, you might add bias to the data. How to avoid that? Let some data users get access to the measurement files [I don't follow]

More from Lea Kissner




More from Tech



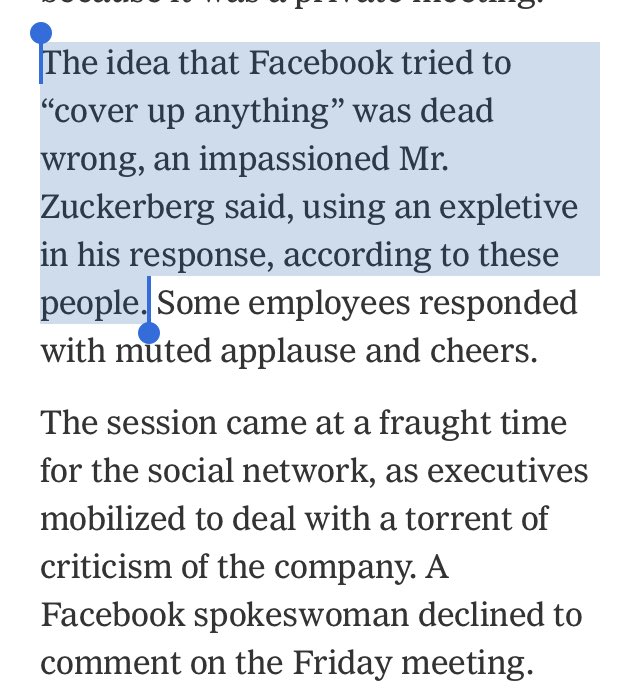
I could create an entire twitter feed of things Facebook has tried to cover up since 2015. Where do you want to start, Mark and Sheryl? https://t.co/1trgupQEH9
Ok, here. Just one of the 236 mentions of Facebook in the under read but incredibly important interim report from Parliament. ht @CommonsCMS https://t.co/gfhHCrOLeU

Let’s do another, this one to Senate Intel. Question: “Were you or CEO Mark Zuckerberg aware of the hiring of Joseph Chancellor?"
Answer "Facebook has over 30,000 employees. Senior management does not participate in day-today hiring decisions."

Or to @CommonsCMS: Question: "When did Mark Zuckerberg know about Cambridge Analytica?"
Answer: "He did not become aware of allegations CA may not have deleted data about FB users obtained through Dr. Kogan's app until March of 2018, when
these issues were raised in the media."

If you prefer visuals, watch this short clip after @IanCLucas rightly expresses concern about a Facebook exec failing to disclose info.
Ok, here. Just one of the 236 mentions of Facebook in the under read but incredibly important interim report from Parliament. ht @CommonsCMS https://t.co/gfhHCrOLeU
Let’s do another, this one to Senate Intel. Question: “Were you or CEO Mark Zuckerberg aware of the hiring of Joseph Chancellor?"
Answer "Facebook has over 30,000 employees. Senior management does not participate in day-today hiring decisions."
Or to @CommonsCMS: Question: "When did Mark Zuckerberg know about Cambridge Analytica?"
Answer: "He did not become aware of allegations CA may not have deleted data about FB users obtained through Dr. Kogan's app until March of 2018, when
these issues were raised in the media."
If you prefer visuals, watch this short clip after @IanCLucas rightly expresses concern about a Facebook exec failing to disclose info.
A company as powerful as @facebook should be subject to proper scrutiny. Mike Schroepfer, its CTO, told us that the buck stops with Mark Zuckerberg on the Cambridge Analytica scandal, which is why he should come and answer our questions @DamianCollins @IanCLucas pic.twitter.com/0H4VMhtIFu
— Digital, Culture, Media and Sport Committee (@CommonsCMS) May 23, 2018





Thought I'd put a thread together of some resources & people I consider really valuable & insightful for anyone considering or just starting out on their @SorareHQ journey. It's by no means comprehensive, this community is super helpful so no offence to anyone I've missed off...
1) Get yourself on the official Sorare Discord group https://t.co/1CWeyglJhu, the forum is always full of interesting debate. Got a question? Put it on the relevant thread & it's usually answered in minutes. This is also a great place to engage directly with the @SorareHQ team.
2) Bury your head in @HGLeitch's @SorareData & get to grips with all the collated information you have to hand FOR FREE! IMO it's vital for price-checking, scouting & S05 team building plus they are hosts to the forward thinking SO11 and SorareData Cups 🏆
3) Get on YouTube 📺, subscribe to @Qu_Tang_Clan's channel https://t.co/1ZxMsQR1kq & engross yourself in hours of Sorare tutorials & videos. There's a good crowd that log in to the live Gameweek shows where you get to see Quinny scratching his head/ beard over team selection.
4) Make sure to follow & give a listen to the @Sorare_Podcast on the streaming service of your choice 🔊, weekly shows are always insightful with great guests. Worth listening to the old episodes too as there's loads of information you'll take from them.
1) Get yourself on the official Sorare Discord group https://t.co/1CWeyglJhu, the forum is always full of interesting debate. Got a question? Put it on the relevant thread & it's usually answered in minutes. This is also a great place to engage directly with the @SorareHQ team.
2) Bury your head in @HGLeitch's @SorareData & get to grips with all the collated information you have to hand FOR FREE! IMO it's vital for price-checking, scouting & S05 team building plus they are hosts to the forward thinking SO11 and SorareData Cups 🏆
3) Get on YouTube 📺, subscribe to @Qu_Tang_Clan's channel https://t.co/1ZxMsQR1kq & engross yourself in hours of Sorare tutorials & videos. There's a good crowd that log in to the live Gameweek shows where you get to see Quinny scratching his head/ beard over team selection.
4) Make sure to follow & give a listen to the @Sorare_Podcast on the streaming service of your choice 🔊, weekly shows are always insightful with great guests. Worth listening to the old episodes too as there's loads of information you'll take from them.
You May Also Like

1/12
RT-PCR corona (test) scam
Symptomatic people are tested for one and only one respiratory virus. This means that other acute respiratory infections are reclassified as
2/12
It is tested exquisitely with a hypersensitive non-specific RT-PCR test / Ct >35 (>30 is nonsense, >35 is madness), without considering Ct and clinical context. This means that more acute respiratory infections are reclassified as
3/12
The Drosten RT-PCR test is fabricated in a way that each country and laboratory perform it differently at too high Ct and that the high rate of false positives increases massively due to cross-reaction with other (corona) viruses in the "flu
4/12
Even asymptomatic, previously called healthy, people are tested (en masse) in this way, although there is no epidemiologically relevant asymptomatic transmission. This means that even healthy people are declared as COVID
5/12
Deaths within 28 days after a positive RT-PCR test from whatever cause are designated as deaths WITH COVID. This means that other causes of death are reclassified as
RT-PCR corona (test) scam
Symptomatic people are tested for one and only one respiratory virus. This means that other acute respiratory infections are reclassified as
4/10
— Dr. Thomas Binder, MD (@Thomas_Binder) October 22, 2020
...indication, first of all that testing for a (single) respiratory virus is done outside of surveillance systems or need for specific therapy, but even so the lack of consideration of Ct, symptoms and clinical findings when interpreting its result. https://t.co/gHH6kwRdZG
2/12
It is tested exquisitely with a hypersensitive non-specific RT-PCR test / Ct >35 (>30 is nonsense, >35 is madness), without considering Ct and clinical context. This means that more acute respiratory infections are reclassified as
6/10
— Dr. Thomas Binder, MD (@Thomas_Binder) October 22, 2020
The neither validated nor standardised hypersensitive RT-PCR test / Ct 35-45 for SARS-CoV-2 is abused to mislabel (also) other diseases, especially influenza, as COVID-19.https://t.co/AkFIfTCTkS
3/12
The Drosten RT-PCR test is fabricated in a way that each country and laboratory perform it differently at too high Ct and that the high rate of false positives increases massively due to cross-reaction with other (corona) viruses in the "flu
External peer review of the RTPCR test to detect SARS-CoV-2 reveals 10 major scientific flaws at the molecular and methodological level: consequences for false positive results.https://t.co/mbNY8bdw1p pic.twitter.com/OQBD4grMth
— Dr. Thomas Binder, MD (@Thomas_Binder) November 29, 2020
4/12
Even asymptomatic, previously called healthy, people are tested (en masse) in this way, although there is no epidemiologically relevant asymptomatic transmission. This means that even healthy people are declared as COVID
Thread web\u2b06\ufe0f\u2b07\ufe0f
— Dr. Thomas Binder, MD (@Thomas_Binder) December 16, 2020
The fabrication of the "asymptomatic (super) spreader" is the coronation of the total nons(ci)ense in the belief system of #CoronasWitnesses.
Asymptomatic transmission 0.7%; 95% CI 0%-4.9% - could well be 0%!https://t.co/VeZTzxXfvT
5/12
Deaths within 28 days after a positive RT-PCR test from whatever cause are designated as deaths WITH COVID. This means that other causes of death are reclassified as
8/8
— Dr. Thomas Binder, MD (@Thomas_Binder) March 24, 2020
By the way, who the f*** created this obviously (almost) worldwide definition of #CoronaDeath?
This is not only medical malpractice, this is utterly insane!https://t.co/FFsTx4L2mw










