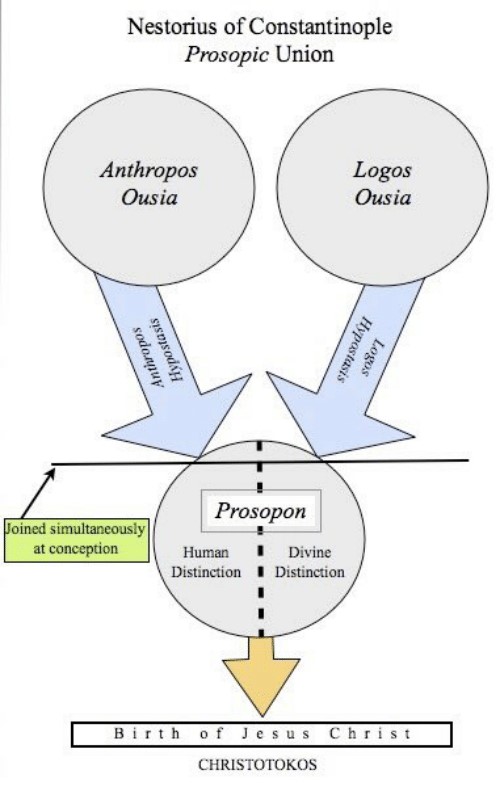
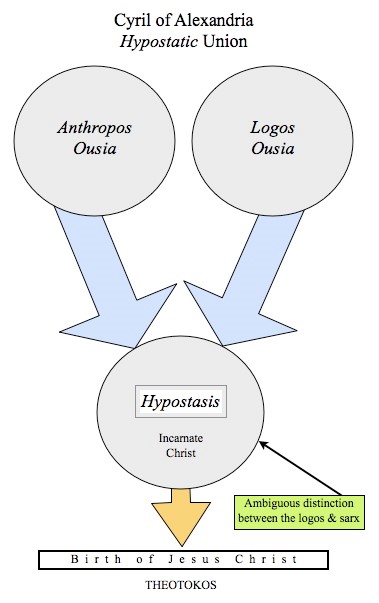
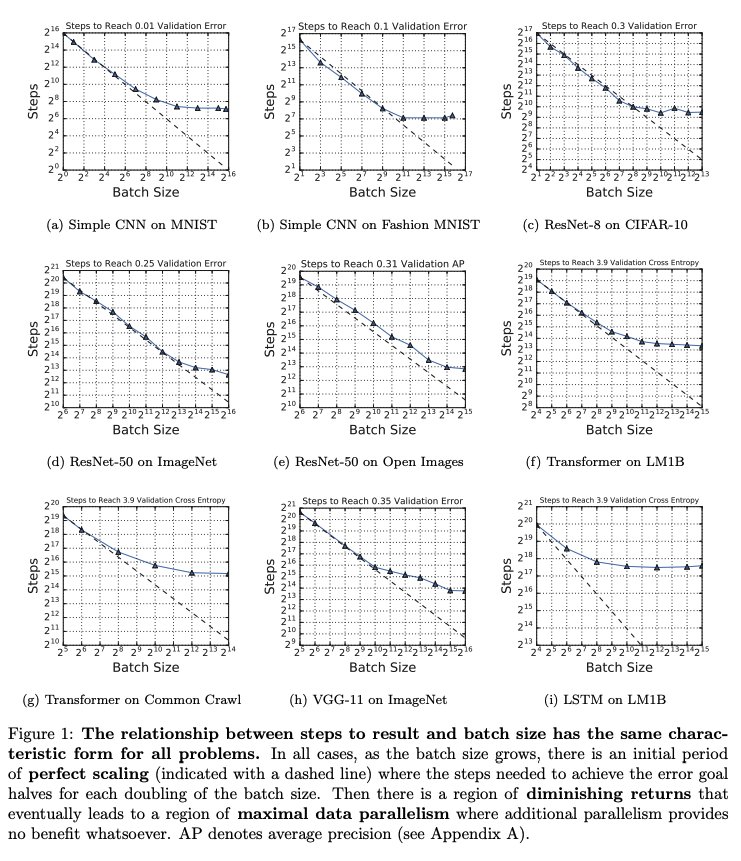
Important paper from Google on large batch optimization. They do impressively careful experiments measuring # iterations needed to achieve target validation error at various batch sizes. The main "surprise" is the lack of surprises. [thread]
https://t.co/7QIx5CFdfJ
More from Machine learning



This is a Twitter series on #FoundationsOfML.
❓ Today, I want to start discussing the different types of Machine Learning flavors we can find.
This is a very high-level overview. In later threads, we'll dive deeper into each paradigm... 👇🧵
Last time we talked about how Machine Learning works.
Basically, it's about having some source of experience E for solving a given task T, that allows us to find a program P which is (hopefully) optimal w.r.t. some metric
According to the nature of that experience, we can define different formulations, or flavors, of the learning process.
A useful distinction is whether we have an explicit goal or desired output, which gives rise to the definitions of 1️⃣ Supervised and 2️⃣ Unsupervised Learning 👇
1️⃣ Supervised Learning
In this formulation, the experience E is a collection of input/output pairs, and the task T is defined as a function that produces the right output for any given input.
👉 The underlying assumption is that there is some correlation (or, in general, a computable relation) between the structure of an input and its corresponding output and that it is possible to infer that function or mapping from a sufficiently large number of examples.
❓ Today, I want to start discussing the different types of Machine Learning flavors we can find.
This is a very high-level overview. In later threads, we'll dive deeper into each paradigm... 👇🧵
Last time we talked about how Machine Learning works.
Basically, it's about having some source of experience E for solving a given task T, that allows us to find a program P which is (hopefully) optimal w.r.t. some metric
I'm starting a Twitter series on #FoundationsOfML. Today, I want to answer this simple question.
— Alejandro Piad Morffis (@AlejandroPiad) January 12, 2021
\u2753 What is Machine Learning?
This is my preferred way of explaining it... \U0001f447\U0001f9f5
According to the nature of that experience, we can define different formulations, or flavors, of the learning process.
A useful distinction is whether we have an explicit goal or desired output, which gives rise to the definitions of 1️⃣ Supervised and 2️⃣ Unsupervised Learning 👇
1️⃣ Supervised Learning
In this formulation, the experience E is a collection of input/output pairs, and the task T is defined as a function that produces the right output for any given input.
👉 The underlying assumption is that there is some correlation (or, in general, a computable relation) between the structure of an input and its corresponding output and that it is possible to infer that function or mapping from a sufficiently large number of examples.

With hard work and determination, anyone can learn to code.
Here’s a list of my favorites resources if you’re learning to code in 2021.
👇
1. freeCodeCamp.
I’d suggest picking one of the projects in the curriculum to tackle and then completing the lessons on syntax when you get stuck. This way you know *why* you’re learning what you’re learning, and you're building things
2. https://t.co/7XC50GlIaa is a hidden gem. Things I love about it:
1) You can see the most upvoted solutions so you can read really good code
2) You can ask questions in the discussion section if you're stuck, and people often answer. Free
3. https://t.co/V9gcXqqLN6 and https://t.co/KbEYGL21iE
On stackoverflow you can find answers to almost every problem you encounter. On GitHub you can read so much great code. You can build so much just from using these two resources and a blank text editor.
4. https://t.co/xX2J00fSrT @eggheadio specifically for frontend dev.
Their tutorials are designed to maximize your time, so you never feel overwhelmed by a 14-hour course. Also, the amount of prep they put into making great courses is unlike any other online course I've seen.
Here’s a list of my favorites resources if you’re learning to code in 2021.
👇
1. freeCodeCamp.
I’d suggest picking one of the projects in the curriculum to tackle and then completing the lessons on syntax when you get stuck. This way you know *why* you’re learning what you’re learning, and you're building things
2. https://t.co/7XC50GlIaa is a hidden gem. Things I love about it:
1) You can see the most upvoted solutions so you can read really good code
2) You can ask questions in the discussion section if you're stuck, and people often answer. Free
3. https://t.co/V9gcXqqLN6 and https://t.co/KbEYGL21iE
On stackoverflow you can find answers to almost every problem you encounter. On GitHub you can read so much great code. You can build so much just from using these two resources and a blank text editor.
4. https://t.co/xX2J00fSrT @eggheadio specifically for frontend dev.
Their tutorials are designed to maximize your time, so you never feel overwhelmed by a 14-hour course. Also, the amount of prep they put into making great courses is unlike any other online course I've seen.
You May Also Like

To people who are under the impression that you can get rich quickly by working on an app, here are the stats for https://t.co/az8F12pf02
📈 ~12000 vistis
☑️ 109 transactions
💰 353€ profit (285 after tax)
I have spent 1.5 months on this app. You can make more $ in 2 days.
🤷♂️

I'm still happy that I launched a paid app bcs it involved extra work:
- backend for processing payments (+ permissions, webhooks, etc)
- integration with payment processor
- UI for license activation in Electron
- machine activation limit
- autoupdates
- mailgun emails
etc.
These things seemed super scary at first. I always thought it was way too much work and something would break. But I'm glad I persisted. So far the only problem I have is that mailgun is not delivering the license keys to certain domains like https://t.co/6Bqn0FUYXo etc. 👌
omg I just realized that me . com is an Apple domain, of course something wouldn't work with these dicks
📈 ~12000 vistis
☑️ 109 transactions
💰 353€ profit (285 after tax)
I have spent 1.5 months on this app. You can make more $ in 2 days.
🤷♂️
I'm still happy that I launched a paid app bcs it involved extra work:
- backend for processing payments (+ permissions, webhooks, etc)
- integration with payment processor
- UI for license activation in Electron
- machine activation limit
- autoupdates
- mailgun emails
etc.
These things seemed super scary at first. I always thought it was way too much work and something would break. But I'm glad I persisted. So far the only problem I have is that mailgun is not delivering the license keys to certain domains like https://t.co/6Bqn0FUYXo etc. 👌
omg I just realized that me . com is an Apple domain, of course something wouldn't work with these dicks