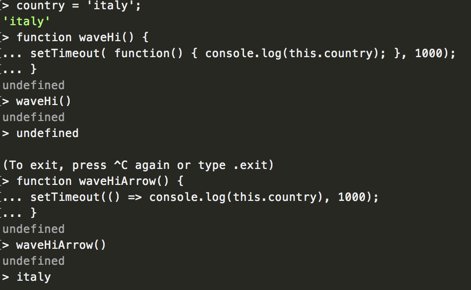
"Attention is all you need" implementation from scratch in PyTorch. A Twitter thread:
1/







More from All
















You May Also Like






Following @BAUDEGS I have experienced hateful and propagandist tweets time after time. I have been shocked that an academic community would be so reckless with their publications. So I did some research.
The question is:
Is this an official account for Bahcesehir Uni (Bau)?

Bahcesehir Uni, BAU has an official website https://t.co/ztzX6uj34V which links to their social media, leading to their Twitter account @Bahcesehir
BAU’s official Twitter account

BAU has many departments, which all have separate accounts. Nowhere among them did I find @BAUDEGS
@BAUOrganization @ApplyBAU @adayBAU @BAUAlumniCenter @bahcesehirfbe @baufens @CyprusBau @bauiisbf @bauglobal @bahcesehirebe @BAUintBatumi @BAUiletisim @BAUSaglik @bauebf @TIPBAU
Nowhere among them was @BAUDEGS to find

The question is:
Is this an official account for Bahcesehir Uni (Bau)?
Bahcesehir Uni, BAU has an official website https://t.co/ztzX6uj34V which links to their social media, leading to their Twitter account @Bahcesehir
BAU’s official Twitter account
BAU has many departments, which all have separate accounts. Nowhere among them did I find @BAUDEGS
@BAUOrganization @ApplyBAU @adayBAU @BAUAlumniCenter @bahcesehirfbe @baufens @CyprusBau @bauiisbf @bauglobal @bahcesehirebe @BAUintBatumi @BAUiletisim @BAUSaglik @bauebf @TIPBAU
Nowhere among them was @BAUDEGS to find