
These networks are primary focus for compression tasks of data in Machine Learning.
Ever heard of Autoencoders?
The first time I saw a Neural Network with more output neurons than in the hidden layers, I couldn't figure how it would work?!
#DeepLearning #MachineLearning
Here's a little something about them: 🧵👇

These networks are primary focus for compression tasks of data in Machine Learning.
Later when someone needs, can just take that small representation and recreate the original, just like a zip file.📥
Our inputs and outputs are same and a simple euclidean distance can be used as a loss function for measuring the reconstruction.
Of course, we wouldn't expect a perfect reconstruction.
We are just trying to minimize the L here. All the backpropagation rules still hold.
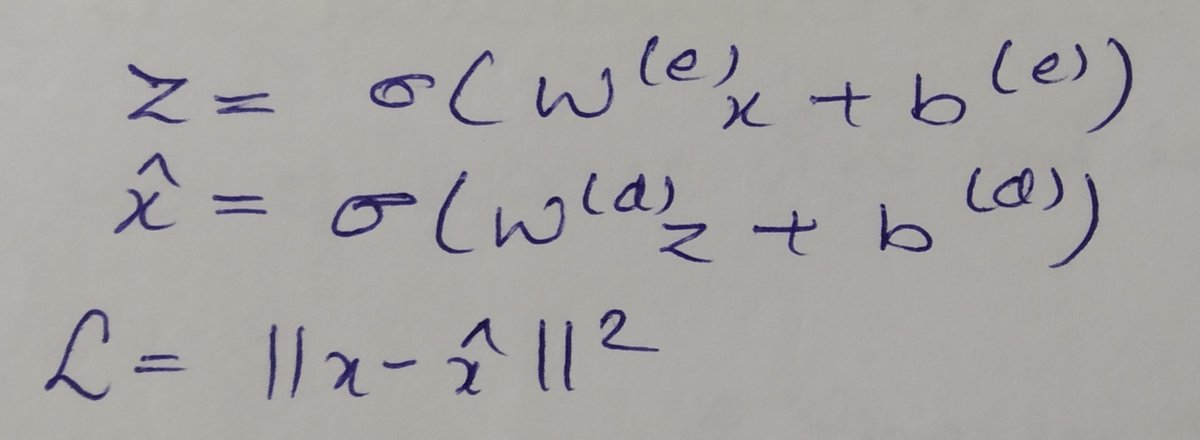
▫️ Can learn non-linear transformations, with non-linear activation functions and multiple layers.
▫️ Doesn't have to learn only from dense layers, can learn from convolutional layers too, better for images, videos right?
▫️ Can make use of pre-trained layers from another model to apply transfer learning to enhance the encoder /decoder
🔸 Image Colouring
🔸 Feature Variation
🔸 Dimensionality Reduction
🔸 Denoising Image
🔸 Watermark Removal
More from Machine learning

Do you want to learn the maths for machine learning but don't know where to start?
This thread is for you.
🧵👇
The guide that you will see below is based on resources that I came across, and some of my experiences over the past 2 years or so.
I use these resources and they will (hopefully) help you in understanding the theoretical aspects of machine learning very well.
Before diving into maths, I suggest first having solid programming skills in Python.
Read this thread for more
These are topics of math you'll have to focus on for machine learning👇
- Trigonometry & Algebra
These are the main pre-requisites for other topics on this list.
(There are other pre-requites but these are the most common)
- Linear Algebra
To manipulate and represent data.
- Calculus
To train and optimize your machine learning model, this is very important.
This thread is for you.
🧵👇
The guide that you will see below is based on resources that I came across, and some of my experiences over the past 2 years or so.
I use these resources and they will (hopefully) help you in understanding the theoretical aspects of machine learning very well.
Before diving into maths, I suggest first having solid programming skills in Python.
Read this thread for more
Are you planning to learn Python for machine learning this year?
— Pratham Prasoon (@PrasoonPratham) February 13, 2021
Here's everything you need to get started.
\U0001f9f5\U0001f447
These are topics of math you'll have to focus on for machine learning👇
- Trigonometry & Algebra
These are the main pre-requisites for other topics on this list.
(There are other pre-requites but these are the most common)
- Linear Algebra
To manipulate and represent data.
- Calculus
To train and optimize your machine learning model, this is very important.

10 machine learning YouTube videos.
On libraries, algorithms, and tools.
(If you want to start with machine learning, having a comprehensive set of hands-on tutorials you can always refer to is fundamental.)
🧵👇
1⃣ Notebooks are a fantastic way to code, experiment, and communicate your results.
Take a look at @CoreyMSchafer's fantastic 30-minute tutorial on Jupyter Notebooks.
https://t.co/HqE9yt8TkB

2⃣ The Pandas library is the gold-standard to manipulate structured data.
Check out @joejamesusa's "Pandas Tutorial. Intro to DataFrames."
https://t.co/aOLh0dcGF5
3⃣ Data visualization is key for anyone practicing machine learning.
Check out @blondiebytes's "Learn Matplotlib in 6 minutes" tutorial.
https://t.co/QxjsODI1HB
4⃣ Another trendy data visualization library is Seaborn.
@NewThinkTank put together "Seaborn Tutorial 2020," which I highly recommend.
https://t.co/eAU5NBucbm
On libraries, algorithms, and tools.
(If you want to start with machine learning, having a comprehensive set of hands-on tutorials you can always refer to is fundamental.)
🧵👇
1⃣ Notebooks are a fantastic way to code, experiment, and communicate your results.
Take a look at @CoreyMSchafer's fantastic 30-minute tutorial on Jupyter Notebooks.
https://t.co/HqE9yt8TkB
2⃣ The Pandas library is the gold-standard to manipulate structured data.
Check out @joejamesusa's "Pandas Tutorial. Intro to DataFrames."
https://t.co/aOLh0dcGF5
3⃣ Data visualization is key for anyone practicing machine learning.
Check out @blondiebytes's "Learn Matplotlib in 6 minutes" tutorial.
https://t.co/QxjsODI1HB
4⃣ Another trendy data visualization library is Seaborn.
@NewThinkTank put together "Seaborn Tutorial 2020," which I highly recommend.
https://t.co/eAU5NBucbm


You May Also Like




There are many strategies in market 📉and it's possible to get monthly 4% return consistently if you master 💪in one strategy .
One of those strategies which I like is Iron Fly✈️
Few important points on Iron fly stategy
This is fixed loss🔴 defined stategy ,so you are aware of your losses . You know your risk ⚠️and breakeven points to exit the positions.
Risk is defined , so at psychological🧠 level you are at peace🙋♀️
How to implement
1. Should be done on Tuesday or Wednesday for next week expiry after 1-2 pm
2. Take view of the market ,looking at daily chart
3. Then do weekly iron fly.
4. No need to hold this till expiry day .
5.Exit it one day before expiry or when you see more than 2% within the week.
5. High vix is preferred for iron fly
6. Can be executed with less capital of 3-5 lakhs .
https://t.co/MYDgWkjYo8 have R:2R so over all it should be good.
8. If you are able to get 6% return monthly ,it means close to 100% return on your capital per annum.
One of those strategies which I like is Iron Fly✈️
Few important points on Iron fly stategy
This is fixed loss🔴 defined stategy ,so you are aware of your losses . You know your risk ⚠️and breakeven points to exit the positions.
Risk is defined , so at psychological🧠 level you are at peace🙋♀️
How to implement
1. Should be done on Tuesday or Wednesday for next week expiry after 1-2 pm
2. Take view of the market ,looking at daily chart
3. Then do weekly iron fly.
4. No need to hold this till expiry day .
5.Exit it one day before expiry or when you see more than 2% within the week.
5. High vix is preferred for iron fly
6. Can be executed with less capital of 3-5 lakhs .
https://t.co/MYDgWkjYo8 have R:2R so over all it should be good.
8. If you are able to get 6% return monthly ,it means close to 100% return on your capital per annum.

A list of cool websites you might now know about
A thread 🧵
1) Learn Anything - Search tools for knowledge discovery that helps you understand any topic through the most efficient
2) Grad Speeches - Discover the best commencement speeches.
This website is made by me
3) What does the Internet Think - Find out what the internet thinks about anything
4) https://t.co/vuhT6jVItx - Send notes that will self-destruct after being read.
A thread 🧵
1) Learn Anything - Search tools for knowledge discovery that helps you understand any topic through the most efficient
2) Grad Speeches - Discover the best commencement speeches.
This website is made by me
3) What does the Internet Think - Find out what the internet thinks about anything
4) https://t.co/vuhT6jVItx - Send notes that will self-destruct after being read.







